
从工具OneForAll代码角度学习子域名挖掘
工具里用到的原理,大部分都可以通过下文找到:
代码分析版本为:OneForAll v0.4.3
OneForAll目录结构:
参考来源
./docs/directory_structure.md
D:.
| .gitignore
| .travis.yml
| brute.py
可以单独运行的子域爆破模块
| collect.py
各个收集模块上层调用
| dbexport.py
可以单独运行的数据库导出模块
| Dockerfile
| LICENSE
| oneforall.py
OneForAll主入口
| Pipfile
| Pipfile.lock
| README.en.md
| README.md
| requirements.txt
| takeover.py
可以单独运行的子域接口风险检查模块
| _config.yml
|
+---.github
| +---ISSUE_TEMPLATE
| | bug_report.md
| | bug_report_zh.md
| | custom.md
| | feature_request.md
| |
| \---workflows
| test.yml
|
|
+---common 公共调用模块
| crawl.py
| database.py
| domain.py
| lookup.py
| module.py
| query.py
| request.py
| resolve.py
| search.py
| utils.py
| __init__.py
|
+---config 配置目录
| api.py
部分收集模块的API配置文件
| log.py
日志模块配置文件
| setting.py
OneForAll主要配置文件
|
+---data 存放一些所需数据
| authoritative_dns.txt
临时存放开启了泛解析域名的权威DNS名称服务器IP地址
| subnames_big.7z
子域爆破超大字典
| nameservers_cn.txt
中国主流名称服务器IP地址
| fingerprints.json 检查子域接管风险的指纹
| nameservers.txt 全球主流名称服务器IP地址
| subnames_next.txt 下一层子域字典
| public_suffix_list.dat 顶级域名后缀
| srv_prefixes.json 常见SRV记录前缀名
| subnames.txt 子域爆破常见字典
|
+---docs 有关文档
| changes.md
| collection_modules.md
| contributors.md
| installation_dependency.md
| todo.md
| troubleshooting.md
| usage_example.svg
| usage_help.en.md
| usage_help.md
|
+---images
| Database.png
| Donate.png
| Result.png
|
+---modules
| +---autotake 自动接管模块
| | github.py
| |
| +---certificates 利用证书透明度收集子域模块
| | censys_api.py
| | certspotter.py
| | crtsh.py
| | entrust.py
| | google.py
| | spyse_api.py
| |
| +---check 常规检查收集子域模块
| | axfr.py
| | cdx.py
| | cert.py
| | csp.py
| | robots.py
| | sitemap.py
| |
| +---crawl 利用网上爬虫档案收集子域模块
| | archivecrawl.py
| | commoncrawl.py
| |
| +---datasets 利用DNS数据集收集子域模块
| | binaryedge_api.py
| | bufferover.py
| | cebaidu.py
| | chinaz.py
| | chinaz_api.py
| | circl_api.py
| | dnsdb_api.py
| | dnsdumpster.py
| | hackertarget.py
| | ip138.py
| | ipv4info_api.py
| | netcraft.py
| | passivedns_api.py
| | ptrarchive.py
| | qianxun.py
| | rapiddns.py
| | riddler.py
| | robtex.py
| | securitytrails_api.py
| | sitedossier.py
| | threatcrowd.py
| | wzpc.py
| | ximcx.py
| |
| +---dnsquery 利用DNS查询收集子域模块
| | mx.py
| | ns.py
| | soa.py
| | srv.py
| | txt.py
| |
| +---intelligence 利用威胁情报平台数据收集子域模块
| | alienvault.py
| | riskiq_api.py
| | threatbook_api.py
| | threatminer.py
| | virustotal.py
| | virustotal_api.py
| |
| \---search 利用搜索引擎发现子域模块
| ask.py
| baidu.py
| bing.py
| bing_api.py
| exalead.py
| fofa_api.py
| gitee.py
| github_api.py
| google.py
| google_api.py
| shodan_api.py
| so.py
| sogou.py
| yahoo.py
| yandex.py
| zoomeye_api.py
|
+---results 结果目录
+---test 测试目录
| example.py
|
\---thirdparty 存放要调用的三方工具
\---massdns
| LICENSE
| massdns_darwin_x86_64
| massdns_linux_i686
| massdns_linux_x86_64
| README.md
|
\---windows
+---x64
| cygwin1.dll
| massdns_windows_amd64.exe
|
\---x86
cyggcc_s-1.dll
cygwin1.dll
massdns_windows_i686.exe依赖如下:
来源
./requirements.txt
beautifulsoup4==4.9.3
bs4==0.0.1
# Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
certifi==2020.12.5
https://appdividend.com/2020/06/19/python-certifi-example-how-to-use-ssl-certificate-in-python/
chardet==4.0.0
# 判断编码
https://pypi.org/project/chardet/
colorama==0.4.4
# 终端颜色显示
https://pypi.org/project/colorama/
dnspython==2.1.0
# Dns查询工具包
https://www.dnspython.org/
exrex==0.10.5
# Exrex 是一个命令行工具和 python 模块,可生成与给定正则表达式等的所有或随机匹配的字符串。
https://github.com/asciimoo/exrex
fire==0.4.0
# Python Fire 是一个用于从绝对任何 Python 对象自动生成命令行界面 (CLI) 的库。
https://github.com/google/python-fire https://blog.csdn.net/qq_17550379/article/details/79943740
future==0.18.2
# 并行
https://docs.python.org/zh-cn/3/library/concurrent.futures.html
idna==2.10
https://pypi.org/project/idna/
loguru==0.5.3
# 日志模块
https://blog.csdn.net/cui_yonghua/article/details/107498535
PySocks==1.7.1
# 代理模块
https://pypi.org/project/PySocks/
requests==2.25.1
# 网页请求模块
https://docs.python-requests.org/en/latest/
six==1.15.0
# 兼容性
https://six.readthedocs.io/
soupsieve==2.2.1
# css选择
https://pypi.org/project/soupsieve/
SQLAlchemy==1.3.22
# Python SQL 工具包和对象关系映射器
https://pypi.org/project/SQLAlchemy/
tenacity==7.0.0
# 简化将重试行为添加到几乎任何内容的任务
https://tenacity.readthedocs.io/en/latest/
termcolor==1.1.0
# 终端颜色
https://pypi.org/project/termcolor/
tqdm==4.59.0
# 进度显示
https://github.com/tqdm/tqdm
treelib==1.6.1
# 在 Python 中提供树数据结构的有效实现
https://treelib.readthedocs.io/en/latest/
urllib3==1.26.4
# 网页请求
https://urllib3.readthedocs.io/en/stable/
win32-setctime==1.0.3
# 一个小的 Python 实用程序,用于在 Windows 上设置文件创建时间。
https://pypi.org/project/win32-setctime/0x1 流程总结
run()->main()->detect_wildcard()泛域名解析->收集模块(Collect)->SRV爆破模块(BruteSRV)->爆破模块(Brute)->dns解析验证(resolve)->http请求验证模块(req)->爬取解析模块(Finder)->子域置换模块(Altdns)->丰富结果(enrich)->子域名接管扫描模块(Takeover)0x2 流程分析
0x2.1 run()
默认配置&检查
for domain in self.domains:
self.domain = utils.get_main_domain(domain)
# 注册域名
self.main()def get_main_domain(domain):
if not isinstance(domain, str):
return None
return Domain(domain).registered()
# Domain类class Domain(object):
def __init__(self, string):
self.string = str(string)
self.regexp = r'\b((?=[a-z0-9-]{1,63}\.)(xn--)?[a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,63}\b'
self.domain = None
# 初始化
def registered(self):
"""
registered domain
>>> d = Domain('www.example.com')
>>> d.registered()
example.com
:return: registered domain result
"""
result = self.extract()
if result:
return result.registered_domain
return None
# 注册&解析(非dns解析)域名变量0x2.2 main()
self.main()
// 调用OneForAll类 main方法0x2.2.1
utils.init_table(self.domain)def init_table(domain):
db = Database()
db.drop_table(domain)
db.create_table(domain)
db.close()
//创建表(先删除,防止报错)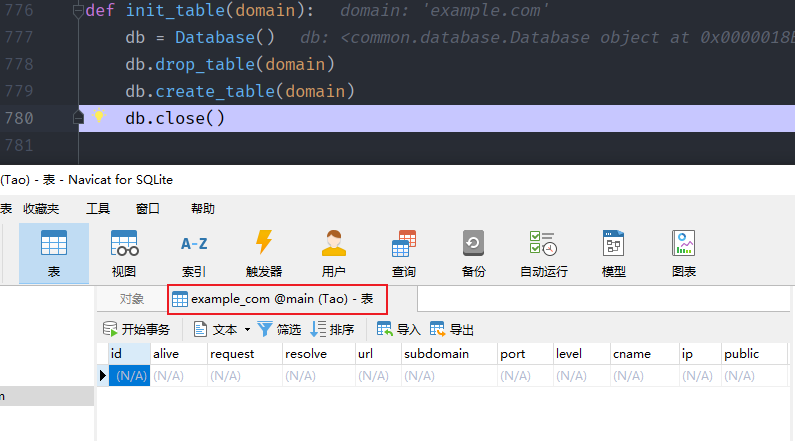
if self.access_internet:
self.enable_wildcard = wildcard.detect_wildcard(self.domain)
# 泛域名解析
collect = Collect(self.domain)
collect.run()
# 跑collect模块
def to_detect_wildcard(domain):
"""
Detect use wildcard dns record or not
:param str domain: domain
:return bool use wildcard dns record or not
"""
logger.log('INFOR', f'Detecting {domain} use wildcard dns record or not')
random_subdomains = gen_random_subdomains(domain, 3) # 随机生成子域名
if not all_resolve_success(random_subdomains):
return False
is_all_success, all_request_resp = all_request_success(random_subdomains)
if not is_all_success:
return True
return any_similar_html(all_request_resp)def gen_random_subdomains(domain, count):
"""
生成指定数量的随机子域域名列表
:param domain: 主域
:param count: 数量
"""
subdomains = set()
if count < 1:
return subdomains
for _ in range(count):
token = secrets.token_hex(4)
subdomains.add(f'{token}.{domain}')
return subdomains0x2.2.2 Collect()模块
以下为收集模块代码:
class Collect(object):
def __init__(self, domain):
self.domain = domain
self.modules = []
self.collect_funcs = []
def run(self):
"""
Class entrance
"""
logger.log('INFOR', f'Start collecting subdomains of {self.domain}')
self.get_mod()
self.import_func()
# 注意上面这两个函数
threads = []
# Create subdomain collection threads
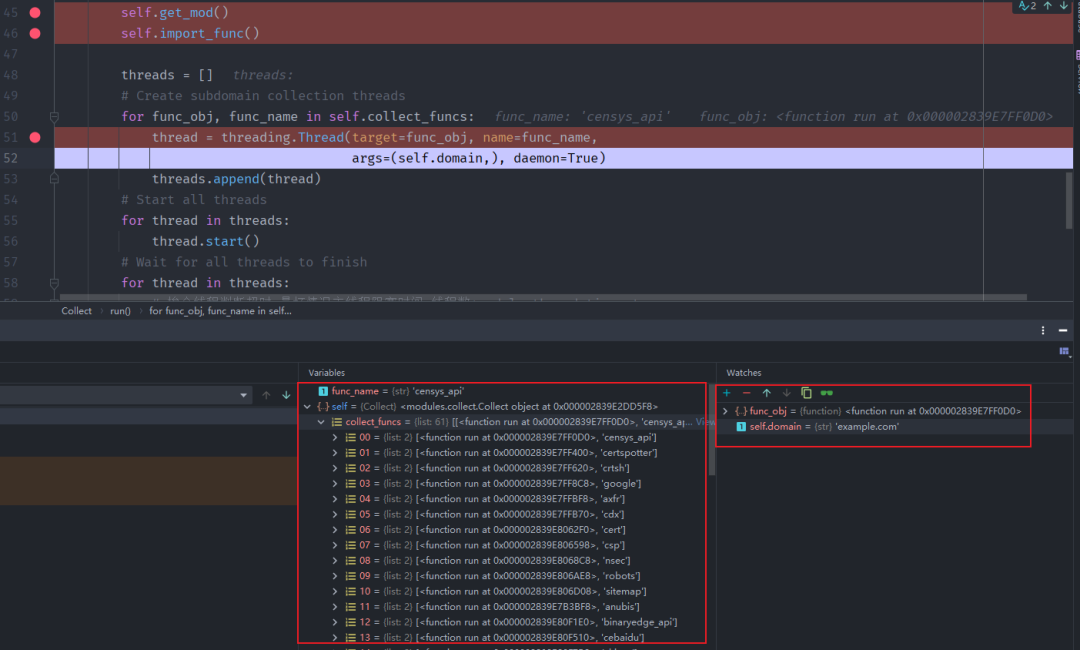
for func_obj, func_name in self.collect_funcs:
thread = threading.Thread(target=func_obj, name=func_name,
args=(self.domain,), daemon=True)
threads.append(thread)
# Start all threads
for thread in threads:
thread.start()
# Wait for all threads to finish
for thread in threads:
# 挨个线程判断超时 最坏情况主线程阻塞时间=线程数*module_thread_timeout
# 超时线程将脱离主线程 由于创建线程时已添加守护属于 所有超时线程会随着主线程结束
thread.join(settings.module_thread_timeout)
for thread in threads:
if thread.is_alive():
logger.log('ALERT', f'{thread.name} module thread timed out')def get_mod(self):
"""
Get modules
"""
if settings.enable_all_module:
# The crawl module has some problems
modules = ['certificates', 'check', 'datasets',
'dnsquery', 'intelligence', 'search']
for module in modules:
module_path = settings.module_dir.joinpath(module)
for path in module_path.rglob('*.py'):
import_module = f'modules.{module}.{path.stem}'
self.modules.append(import_module)
# modules文件导入
else:
self.modules = settings.enable_partial_module
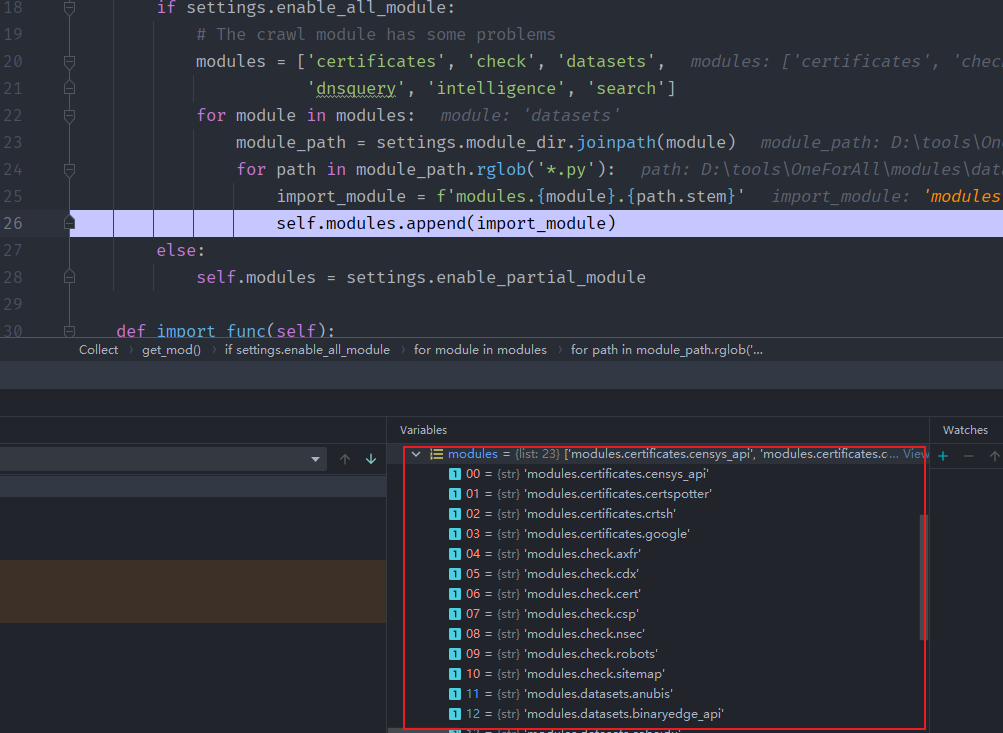
def import_func(self):
"""
Import do function
"""
for module in self.modules:
name = module.split('.')[-1]
import_object = importlib.import_module(module)
func = getattr(import_object, 'run')
self.collect_funcs.append([func, name])
# 获取module每个py文件run方法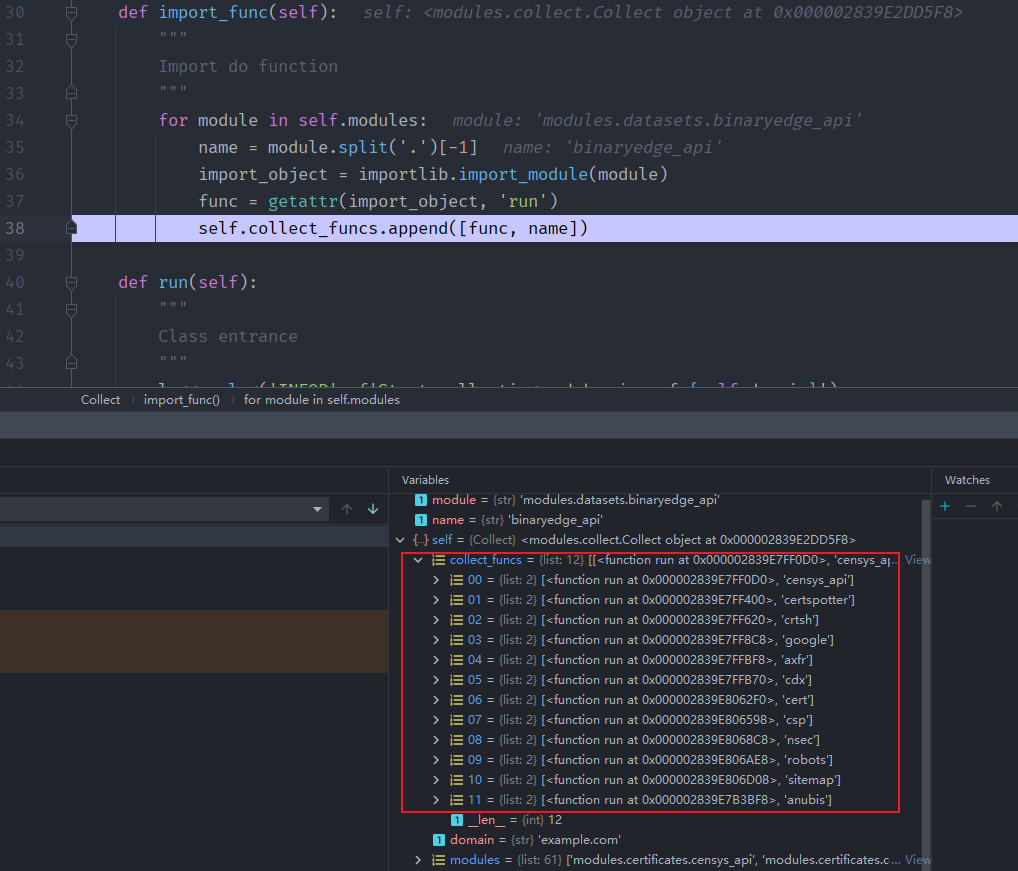
for func_obj, func_name in self.collect_funcs:
thread = threading.Thread(target=func_obj, name=func_name,
args=(self.domain,), daemon=True)
threads.append(thread)
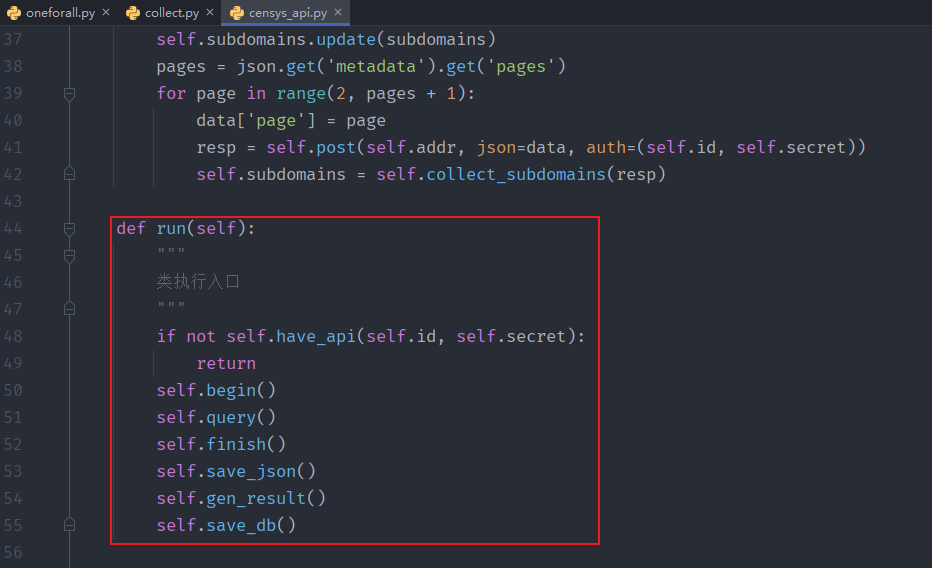
modules每个py文件模板差不多都长这样
因此,这里用到了继承,也重点关注下这块的代码
from common.query import Query
class CensysAPI(Query):
def run():
self.begin()
self.query() // 除了query,其他方法均继承与Query类
self.finish()
self.save_json()
self.gen_result()
self.save_db()Query继承于Module类
from common.module import Module
class Query(Module):
"""
Query base class
"""
def __init__(self):
Module.__init__(self)
class Module(object):
def __init__(self):
self.module = 'Module'
self.source = 'BaseModule'
self.cookie = None
self.header = dict()
self.proxy = None
self.delay = 1 # 请求睡眠时延
self.timeout = settings.request_timeout_second # 请求超时时间
self.verify = settings.request_ssl_verify # 请求SSL验证
self.domain = str() # 当前进行子域名收集的主域
self.subdomains = set() # 存放发现的子域
self.infos = dict() # 存放子域有关信息
self.results = list() # 存放模块结果
self.start = time.time() # 模块开始执行时间
self.end = None # 模块结束执行时间
self.elapse = None # 模块执行耗时
def begin(self):
"""
begin log
"""
logger.log('DEBUG', f'Start {self.source} module to '
f'collect subdomains of {self.domain}')
def finish(self):
"""
finish log
"""
self.end = time.time()
self.elapse = round(self.end - self.start, 1)
logger.log('DEBUG', f'Finished {self.source} module to '
f'collect {self.domain}\'s subdomains')
logger.log('INFOR', f'{self.source} module took {self.elapse} seconds '
f'found {len(self.subdomains)} subdomains')
logger.log('DEBUG', f'{self.source} module found subdomains of {self.domain}\n'
f'{self.subdomains}')
.......
.......
.......
# 重写了get,post,head等请求
def save_json(self):
"""
Save the results of each module as a json file
:return bool: whether saved successfully
"""
if not settings.save_module_result:
return False
logger.log('TRACE', f'Save the subdomain results found by '
f'{self.source} module as a json file')
path = settings.result_save_dir.joinpath(self.domain, self.module)
path.mkdir(parents=True, exist_ok=True)
name = self.source + '.json'
path = path.joinpath(name)
with open(path, mode='w', errors='ignore') as file:
result = {'domain': self.domain,
'name': self.module,
'source': self.source,
'elapse': self.elapse,
'find': len(self.subdomains),
'subdomains': list(self.subdomains),
'infos': self.infos}
json.dump(result, file, ensure_ascii=False, indent=4)
return True
def gen_result(self):
"""
Generate results
"""
logger.log('DEBUG', f'Generating final results')
if not len(self.subdomains): # 该模块一个子域都没有发现的情况
logger.log('DEBUG', f'{self.source} module result is empty')
result = {'id': None,
'alive': None,
'request': None,
'resolve': None,
'url': None,
'subdomain': None,
'port': None,
'level': None,
'cname': None,
'ip': None,
'public': None,
'cdn': None,
'status': None,
'reason': None,
'title': None,
'banner': None,
'header': None,
'history': None,
'response': None,
'ip_times': None,
'cname_times': None,
'ttl': None,
'cidr': None,
'asn': None,
'org': None,
'addr': None,
'isp': None,
'resolver': None,
'module': self.module,
'source': self.source,
'elapse': self.elapse,
'find': None}
self.results.append(result)
else:
for subdomain in self.subdomains:
url = 'http://' + subdomain
level = subdomain.count('.') - self.domain.count('.')
info = self.infos.get(subdomain)
if info is None:
info = dict()
cname = info.get('cname')
ip = info.get('ip')
ip_times = info.get('ip_times')
cname_times = info.get('cname_times')
ttl = info.get('ttl')
if isinstance(cname, list):
cname = ','.join(cname)
ip = ','.join(ip)
ip_times = ','.join([str(num) for num in ip_times])
cname_times = ','.join([str(num) for num in cname_times])
ttl = ','.join([str(num) for num in ttl])
result = {'id': None,
'alive': info.get('alive'),
'request': info.get('request'),
'resolve': info.get('resolve'),
'url': url,
'subdomain': subdomain,
'port': 80,
'level': level,
'cname': cname,
'ip': ip,
'public': info.get('public'),
'cdn': info.get('cdn'),
'status': None,
'reason': info.get('reason'),
'title': None,
'banner': None,
'header': None,
'history': None,
'response': None,
'ip_times': ip_times,
'cname_times': cname_times,
'ttl': ttl,
'cidr': info.get('cidr'),
'asn': info.get('asn'),
'org': info.get('org'),
'addr': info.get('addr'),
'isp': info.get('isp'),
'resolver': info.get('resolver'),
'module': self.module,
'source': self.source,
'elapse': self.elapse,
'find': len(self.subdomains)}
self.results.append(result)
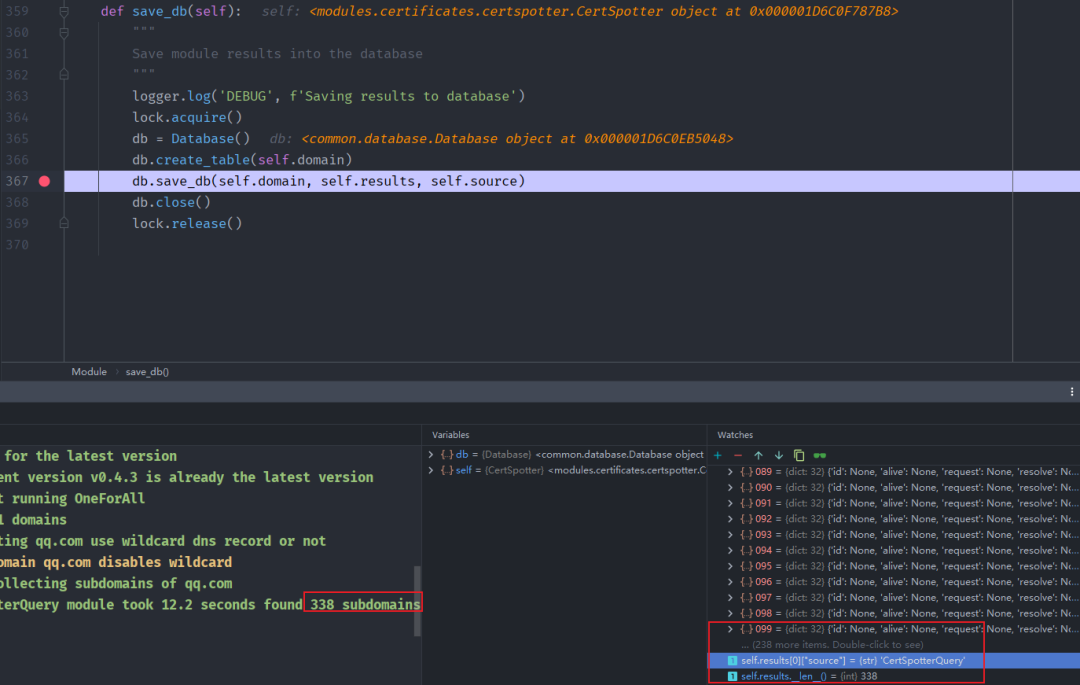
def save_db(self):
"""
Save module results into the database
"""
logger.log('DEBUG', f'Saving results to database')
lock.acquire()
db = Database()
db.create_table(self.domain)
db.save_db(self.domain, self.results, self.source)
db.close()
lock.release()单独拎出来:(不重要的省略,但是不影响后面分析)
def run():
self.begin() # 输出日志
self.query() # 除了query,其他方法均继承与Query类
self.finish() # 输出日志,计算query用了多少时间
self.save_json() # 保存json
self.gen_result()
self.save_db()save_json()
name = self.source + '.json'
path = path.joinpath(name)
with open(path, mode='w', errors='ignore') as file:
result = {'domain': self.domain,
'name': self.module,
'source': self.source,
'elapse': self.elapse,
'find': len(self.subdomains),
'subdomains': list(self.subdomains),
'infos': self.infos}
json.dump(result, file, ensure_ascii=False, indent=4)gen_result()
result = ......
self.results.append(result)
save_db(self):
db.save_db(self.domain, self.results, self.source) # 重点可以如何存储的数据
这里用了多线程def save_db(self, table_name, results, module_name=None):
table_name = table_name.replace('.', '_')
if results:
try:
self.conn.bulk_query(insert data sql)
# self.conn = self.get_conn(db_path)
# return db.get_connection()
# Connection(self._engine.connect())def bulk_query(self, query, *multiparams):
self._conn.execute(text(query), *multiparams)
# self._conn = Connection(self._engine.connect())
# 这里挺绕的😅collect模块跑完了,最终数据都在self.results(这其中,跑完一个小模块,存数据,边跑边存)
注意:此时的数据还未进行解析验证、http请求等
后续还有对其导出再删除表再新建表重新插入数据的操作
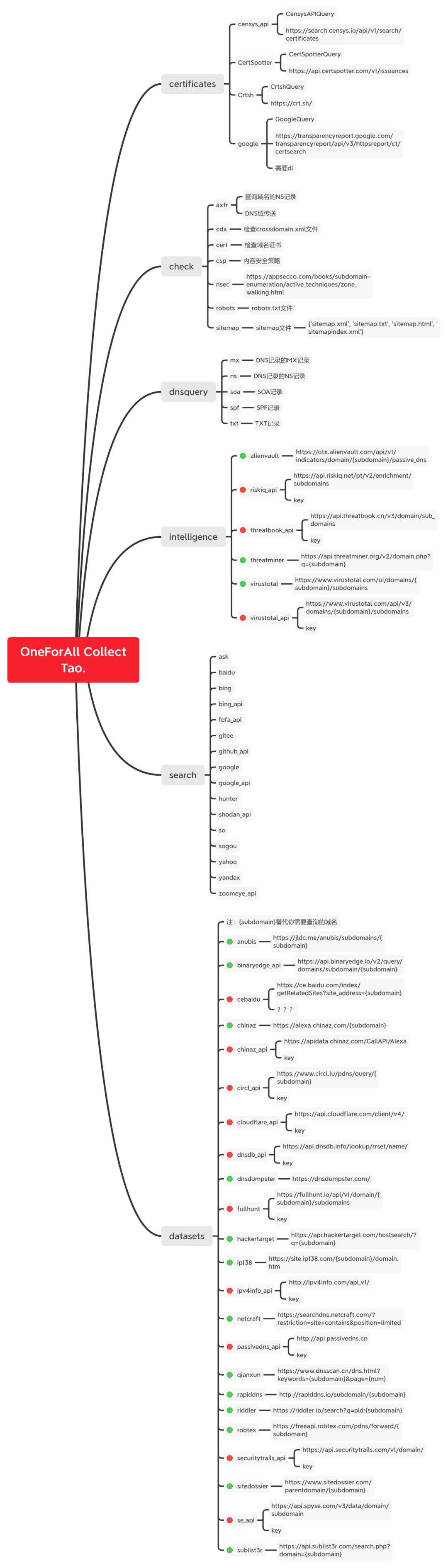
Collect()总结图如下:
0x2.2.3 BruteSRV
# 回到 oneforall.py - 161行
srv = BruteSRV(self.domain)
srv.run()class BruteSRV(Module):
def __init__(self, domain):
Module.__init__(self)
self.domain = domain
self.module = 'BruteSRV'
self.source = "BruteSRV"
self.qtype = 'SRV'
self.thread_num = 20
self.names_queue = queue.Queue()
self.answers_queue = queue.Queue()
def run(self):
self.begin() # 继承的,跟上面一样
self.fill_queue() # 读取 srv_prefixes.json
self.do_brute() # 多线程爆破
self.deal_answers() #
self.finish()
self.save_json()
self.gen_result()
self.save_db()
# 继承于Module.pyself.fill_queue()
path = data_storage_dir.joinpath('srv_prefixes.json')
prefixes = utils.load_json(path)
for prefix in prefixes:
self.names_queue.put(prefix + self.domain)
def do_brute(self):
for num in range(self.thread_num):
thread = BruteThread(self.names_queue, self.answers_queue)
# 类继承方式 多线程
thread.name = f'BruteThread-{num}'
thread.daemon = True
thread.start()
self.names_queue.join()
def deal_answers(self):
while not self.answers_queue.empty():
answer = self.answers_queue.get()
if answer is None:
continue
for item in answer:
record = str(item)
subdomains = self.match_subdomains(record)
self.subdomains.update(subdomains) # set集合存结果0x2.2.4 brute模块
# 爆破模块, 调用brute.py文件
if self.brute:
# Due to there will be a large number of dns resolution requests,
# may cause other network tasks to be error
brute = Brute(self.domain, word=True, export=False)
brute.enable_wildcard = self.enable_wildcard
brute.in_china = self.in_china
brute.quite = True
brute.run() def main(self, domain):
start = time.time()
logger.log('INFOR', f'Blasting {domain} ')
massdns_dir = settings.third_party_dir.joinpath('massdns')
result_dir = settings.result_save_dir
temp_dir = result_dir.joinpath('temp')
utils.check_dir(temp_dir)
massdns_path = utils.get_massdns_path(massdns_dir)
timestring = utils.get_timestring()
wildcard_ips = list() # 泛解析IP列表
wildcard_ttl = int() # 泛解析TTL整型值
ns_list = query_domain_ns(self.domain)
ns_ip_list = query_domain_ns_a(ns_list) # DNS权威名称服务器对应A记录列表
if self.enable_wildcard is None:
self.enable_wildcard = wildcard.detect_wildcard(domain)
if self.enable_wildcard:
wildcard_ips, wildcard_ttl = wildcard.collect_wildcard_record(domain, ns_ip_list)
ns_path = utils.get_ns_path(self.in_china, self.enable_wildcard, ns_ip_list)
dict_set = self.gen_brute_dict(domain)
# 生成字典
def gen_brute_dict(self, domain):
logger.log('INFOR', f'Generating dictionary for {domain}')
dict_set = set()
# 如果domain不是self.subdomain 而是self.domain的子域则生成递归爆破字典
if self.word:
self.place = ''
if not self.place:
self.place = '*.' + domain
wordlist = self.wordlist
main_domain = utils.get_main_domain(domain)
if domain != main_domain:
wordlist = self.recursive_nextlist
if self.word:
word_subdomains = gen_word_subdomains(self.place, wordlist)
dict_set.update(word_subdomains)
if self.fuzz:
fuzz_subdomains = gen_fuzz_subdomains(self.place, self.rule, self.fuzzlist)
dict_set.update(fuzz_subdomains)
count = len(dict_set)
logger.log('INFOR', f'Dictionary size: {count}')
if count > 10000000:
logger.log('ALERT', f'The generated dictionary is '
f'too large {count} > 10000000')
return dict_set未指定参数
--wordlist,默认调用的是./data/subnames.txt字典文件,95247个子域名爆破字典数大于
10000000会报。。。dict_name = f'generated_subdomains_{domain}_{timestring}.txt'
dict_path = temp_dir.joinpath(dict_name)
save_brute_dict(dict_path, dict_set)
del dict_set
gc.collect()
output_name = f'resolved_result_{domain}_{timestring}.json'
output_path = temp_dir.joinpath(output_name)
log_path = result_dir.joinpath('massdns.log')
check_dict()
logger.log('INFOR', f'Running massdns to brute subdomains')
utils.call_massdns(massdns_path, dict_path, ns_path, output_path,
log_path, quiet_mode=self.quite,
concurrent_num=self.concurrent_num)
# 调用massdns进行暴力破解
appear_times = stat_appear_times(output_path)
self.infos, self.subdomains = deal_output(output_path, appear_times,
wildcard_ips, wildcard_ttl)
delete_file(dict_path, output_path)
end = time.time()
self.elapse = round(end - start, 1)
logger.log('ALERT', f'{self.source} module takes {self.elapse} seconds, '
f'found {len(self.subdomains)} subdomains of {domain}')
logger.log('DEBUG', f'{self.source} module found subdomains of {domain}: '
f'{self.subdomains}')
self.gen_result()
self.save_db()
return self.subdomains# call_massdns函数cmd
massdns.exe .......调用massdns爆破
0x2.2.5 数据处理
utils.deal_data(self.domain)def deal_data(domain):
db = Database()
db.remove_invalid(domain)
db.deduplicate_subdomain(domain)
db.close() def remove_invalid(self, table_name):
"""
Remove nulls or invalid subdomains in the table
:param str table_name: table name
"""
table_name = table_name.replace('.', '_')
logger.log('TRACE', f'Removing invalid subdomains in {table_name} table')
self.query(f'delete from "{table_name}" where '
f'subdomain is null or resolve == 0')
# 移除无效数据 def deduplicate_subdomain(self, table_name):
"""
Deduplicate subdomains in the table
:param str table_name: table name
"""
table_name = table_name.replace('.', '_')
logger.log('TRACE', f'Deduplicating subdomains in {table_name} table')
self.query(f'delete from "{table_name}" where '
f'id not in (select min(id) '
f'from "{table_name}" group by subdomain)')
# 数据去重0x2.2.6
if not self.dns:
self.data = self.export_data()# 导出数据
self.datas.extend(self.data)# self.datas新列表存储数据
return self.data #
self.data = self.export_data()def export_data(self):
"""
Export data from the database
:return: exported data
:rtype: list
"""
return export.export_data(self.domain, alive=self.alive, fmt=self.fmt, path=self.path)def export_data(target, db=None, alive=False, limit=None, path=None, fmt='csv', show=False):
"""
OneForAll export from database module
Example:
python3 export.py --target name --fmt csv --dir= ./result.csv
python3 export.py --target name --tb True --show False
python3 export.py --db result.db --target name --show False
Note:
--fmt csv/json (result format)
--path Result directory (default directory is ./results)
:param str target: Table to be exported
:param str db: Database path to be exported (default ./results/result.sqlite3)
:param bool alive: Only export the results of alive subdomains (default False)
:param str limit: Export limit (default None)
:param str fmt: Result format (default csv)
:param str path: Result directory (default None)
:param bool show: Displays the exported data in terminal (default False)
"""
database = Database(db)
domains = utils.get_domains(target)
datas = list()
if domains:
for domain in domains:
table_name = domain.replace('.', '_')
rows = database.export_data(table_name, alive, limit) # !!!
if rows is None:
continue
data, _, _ = do_export(fmt, path, rows, show, domain, target)# !!!
datas.extend(data)
database.close()
if len(domains) > 1:
utils.export_all(alive, fmt, path, datas) # !!!
return datas def export_data(self, table_name, alive, limit):
"""
Get part of the data in the table
:param str table_name: table name
:param any alive: alive flag
:param str limit: limit value
"""
table_name = table_name.replace('.', '_')
sql = f'select id, alive, request, resolve, url, subdomain, level,' \
f'cname, ip, public, cdn, port, status, reason, title, banner,' \
f'cidr, asn, org, addr, isp, source from "{table_name}" '
if alive and limit:
if limit in ['resolve', 'request']:
where = f' where {limit} = 1'
sql += where
elif alive:
where = f' where alive = 1'
sql += where
sql += ' order by subdomain'
logger.log('TRACE', f'Get the data from {table_name} table')
return self.query(sql)def do_export(fmt, path, rows, show, domain, target):
fmt = utils.check_format(fmt)
path = utils.check_path(path, target, fmt)
if show:
print(rows.dataset)
data = rows.export(fmt)
utils.save_to_file(path, data)
logger.log('ALERT', f'The subdomain result for {domain}: {path}')
data = rows.as_dict()
return data, fmt, pathdef export_all(alive, fmt, path, datas):
"""
将所有结果数据导出
:param bool alive: 只导出存活子域结果
:param str fmt: 导出文件格式
:param str path: 导出文件路径
:param list datas: 待导出的结果数据
"""
fmt = check_format(fmt)
timestamp = get_timestring()
name = f'all_subdomain_result_{timestamp}'
export_all_results(path, name, fmt, datas)
export_all_subdomains(alive, path, name, datas)def export_all_results(path, name, fmt, datas):
path = check_path(path, name, fmt)
logger.log('ALERT', f'The subdomain result for all main domains: {path}')
row_list = list()
for row in datas:
if 'header' in row:
row.pop('header')
if 'response' in row:
row.pop('response')
keys = row.keys()
values = row.values()
row_list.append(Record(keys, values))
rows = RecordCollection(iter(row_list)) //!!!
content = rows.export(fmt)
save_to_file(path, content)def export_all_subdomains(alive, path, name, datas):
path = check_path(path, name, 'txt')
logger.log('ALERT', f'The txt subdomain result for all main domains: {path}')
subdomains = set()
for row in datas:
subdomain = row.get('subdomain')
if alive:
if not row.get('alive'):
continue
subdomains.add(subdomain)
else:
subdomains.add(subdomain)
data = '\n'.join(subdomains)
save_to_file(path, data)self.data = utils.get_data(self.domain)
def get_data(domain):
db = Database()
data = db.get_data(domain).as_dict() # !!!
db.close()
return datadb.get_data(domain)
def get_data(self, table_name):
"""
Get all the data in the table
:param str table_name: table name
"""
table_name = table_name.replace('.', '_')
logger.log('TRACE', f'Get all the data from {table_name} table')
return self.query(f'select * from "{table_name}"')as_dict()
def as_dict(self, ordered=False):
return self.all(as_dict=not (ordered), as_ordereddict=ordered) def all(self, as_dict=False, as_ordereddict=False):
"""Returns a list of all rows for the RecordCollection. If they haven't
been fetched yet, consume the iterator and cache the results."""
# By calling list it calls the __iter__ method
rows = list(self)
if as_dict:
return [r.as_dict() for r in rows]
elif as_ordereddict:
return [r.as_dict(ordered=True) for r in rows]
return rows
# OrderedDict迭代器utils.clear_data(self.domain)
def clear_data(domain):
db = Database()
db.drop_table(domain)
db.close()
# 删除表
# 此时表里的数据未进行resolve, http req, 前面由get_data取出了再删除0x2.2.7 DNS解析验证
self.data = resolve.run_resolve(self.domain, self.data)
resolve.save_db(self.domain, self.data)
def run_resolve(domain, data):
"""
调用子域解析入口函数
:param str domain: 待解析的主域
:param list data: 待解析的子域数据列表
:return: 解析得到的结果列表
:rtype: list
"""
logger.log('INFOR', f'Start resolving subdomains of {domain}')
subdomains = filter_subdomain(data)
if not subdomains:
return data
massdns_dir = settings.third_party_dir.joinpath('massdns')
result_dir = settings.result_save_dir
temp_dir = result_dir.joinpath('temp')
utils.check_dir(temp_dir)
massdns_path = utils.get_massdns_path(massdns_dir)
timestring = utils.get_timestring()
save_name = f'collected_subdomains_{domain}_{timestring}.txt'
save_path = temp_dir.joinpath(save_name)
save_subdomains(save_path, subdomains)
del subdomains
gc.collect()
output_name = f'resolved_result_{domain}_{timestring}.json'
output_path = temp_dir.joinpath(output_name)
log_path = result_dir.joinpath('massdns.log')
ns_path = utils.get_ns_path()
logger.log('INFOR', f'Running massdns to resolve subdomains')
utils.call_massdns(massdns_path, save_path, ns_path,
output_path, log_path, quiet_mode=True)
infos = deal_output(output_path)
data = update_data(data, infos)
logger.log('INFOR', f'Finished resolve subdomains of {domain}')
return datacall_massdnsdef call_massdns(massdns_path, dict_path, ns_path, output_path, log_path,
query_type='A', process_num=1, concurrent_num=10000,
quiet_mode=False):
logger.log('DEBUG', 'Start running massdns')
quiet = ''
if quiet_mode:
quiet = '--quiet'
status_format = settings.brute_status_format
socket_num = settings.brute_socket_num
resolve_num = settings.brute_resolve_num
cmd = f'{massdns_path} {quiet} --status-format {status_format} ' \
f'--processes {process_num} --socket-count {socket_num} ' \
f'--hashmap-size {concurrent_num} --resolvers {ns_path} ' \
f'--resolve-count {resolve_num} --type {query_type} ' \
f'--flush --output J --outfile {output_path} ' \
f'--root --error-log {log_path} {dict_path} --filter OK ' \
f'--sndbuf 0 --rcvbuf 0'
logger.log('DEBUG', f'Run command {cmd}')
subprocess.run(args=cmd, shell=True)
logger.log('DEBUG', f'Finished massdns')resolve.save_db(self.domain, self.data)
def save_db(name, data):
"""
Save resolved results to database
:param str name: table name
:param list data: data to be saved
"""
logger.log('INFOR', f'Saving resolved results')
utils.save_to_db(name, data, 'resolve') // !!!def save_to_db(name, data, module):
"""
Save request results to database
:param str name: table name
:param list data: data to be saved
:param str module: module name
"""
db = Database()
db.drop_table(name)
db.create_table(name)
db.save_db(name, data, module)
db.close()if not self.req: # 如果没有req
self.data = self.export_data()
self.datas.extend(self.data)
return self.data
# 跟前面相同
if self.enable_wildcard: # 如果有泛解析
# deal wildcard
self.data = wildcard.deal_wildcard(self.data)
# HTTP request
utils.clear_data(self.domain)
request.run_request(self.domain, self.data, self.port)self.data = wildcard.deal_wildcard(self.data)
def deal_wildcard(data):
new_data = list()
appear_times = stat_times(data)
for info in data:
subdomain = info.get('subdomain')
isvalid, reason = check_valid_subdomain(appear_times, info)
logger.log('DEBUG', f'{subdomain} is {isvalid} subdomain reason because {reason}')
if isvalid:
new_data.append(info) # !!!
return new_data0x2.2.8 http请求验证模块
utils.clear_data(self.domain) # 跟上一样
request.run_request(self.domain, self.data, self.port) # 跑req,更新数据def run_request(domain, data, port):
"""
HTTP request entrance
:param str domain: domain to be requested
:param list data: subdomains data to be requested
:param any port: range of ports to be requested
:return list: result
"""
logger.log('INFOR', f'Start requesting subdomains of {domain}')
data = utils.set_id_none(data)
ports = get_port_seq(port)
req_data, req_urls = gen_req_data(data, ports)
bulk_request(domain, req_data)
count = utils.count_alive(domain)
logger.log('INFOR', f'Found that {domain} has {count} alive subdomains')def bulk_request(domain, req_data, ret=False):
logger.log('INFOR', 'Requesting urls in bulk')
resp_queue = Queue()
urls_queue = Queue()
task_count = len(req_data)
for index, info in enumerate(req_data):
url = info.get('url')
urls_queue.put((index, url))
session = get_session()
thread_count = req_thread_count()
if task_count <= thread_count:
# 如果请求任务数很小不用创建很多线程了
thread_count = task_count
bar = get_progress_bar(task_count)
progress_thread = Thread(target=progress, name='ProgressThread',
args=(bar, task_count, urls_queue), daemon=True)
progress_thread.start()
for i in range(thread_count):
request_thread = Thread(target=request, name=f'RequestThread-{i}',
args=(urls_queue, resp_queue, session), daemon=True)
request_thread.start()
if ret:
urls_queue.join()
return resp_queue
save_thread = Thread(target=save, name=f'SaveThread',
args=(domain, task_count, req_data, resp_queue), daemon=True)
save_thread.start()
urls_queue.join()
save_thread.join()
0x2.2.9 爬取解析模块
# Finder module
if settings.enable_finder_module:
finder = Finder()
finder.run(self.domain, self.data, self.port)def run(self, domain, data, port):
logger.log('INFOR', f'Start Finder module')
existing_subdomains = set(map(lambda x: x.get('subdomain'), data)) # 已有的子域
found_subdomains = find_subdomains(domain, data) # !!! 主要功能在此函数
new_subdomains = found_subdomains - existing_subdomains
if not len(new_subdomains):
self.finish() # 未发现新的子域就直接返回
self.subdomains = new_subdomains
self.finish()
self.gen_result()
resolved_data = resolve.run_resolve(domain, self.results)
request.run_request(domain, resolved_data, port)
# https://github.com/GerbenJavado/LinkFinderdef find_subdomains(domain, data):
subdomains = set()
js_urls = set()
db = Database()
for infos in data:
jump_history = infos.get('history')
req_url = infos.get('url')
subdomains.update(find_in_history(domain, req_url, jump_history))
# URL跳转历史中查找子域名
rsp_html = db.get_resp_by_url(domain, req_url)
if not rsp_html:
logger.log('DEBUG', f'an abnormal response occurred in the request {req_url}')
continue
subdomains.update(find_in_resp(domain, req_url, rsp_html))
# 返回内容种查找子域名
js_urls.update(find_js_urls(domain, req_url, rsp_html))
# js中查找子域名
req_data = convert_to_dict(js_urls)
resp_data = request.bulk_request(domain, req_data, ret=True)
while not resp_data.empty():
_, resp = resp_data.get()
if not isinstance(resp, Response):
continue
text = utils.decode_resp_text(resp)
subdomains.update(find_in_resp(domain, resp.url, text))
return subdomainsdef find_in_history(domain, url, history):
logger.log('TRACE', f'matching subdomains from history of {url}')
return match_subdomains(domain, history)URL跳转历史中查找子域名,通过match_subdomains匹配
def find_in_resp(domain, url, html):
logger.log('TRACE', f'matching subdomains from response of {url}')
return match_subdomains(domain, html)从返回内容种查找子域名
def find_js_urls(domain, req_url, rsp_html):
js_urls = set()
new_urls = find_new_urls(rsp_html)
if not new_urls:
return js_urls
for rel_url in new_urls:
url = convert_url(req_url, rel_url)
if not filter_url(domain, url):
js_urls.add(url)
return js_urls从js中查找子域名
0x2.2.10 子域置换模块
# altdns module
if settings.enable_altdns_module:
altdns = Altdns(self.domain)
altdns.run(self.data, self.port)
# 根据已有的子域,使用子域替换技术再次发现新的子域 def run(self, data, port):
logger.log('INFOR', f'Start altdns module')
self.now_subdomains = utils.get_subdomains(data)
self.get_words()
self.extract_words()
self.gen_new_subdomains()
self.subdomains = self.new_subdomains - self.now_subdomains
count = len(self.subdomains)
logger.log('INFOR', f'The altdns module generated {count} new subdomains')
self.end = time.time()
self.elapse = round(self.end - self.start, 1)
self.gen_result()
resolved_data = resolve.run_resolve(self.domain, self.results)
valid_data = wildcard.deal_wildcard(resolved_data) # 强制开启泛解析处理
request.run_request(self.domain, valid_data, port)self.get_words() # 得到words,words来源./data/altdns_wordlist.txt
self.extract_words() # 根据目标的域命名约定扩展字典
self.gen_new_subdomains() def get_words(self):
path = settings.data_storage_dir.joinpath('altdns_wordlist.txt')
with open(path) as fd:
for line in fd:
word = line.lower().strip()
if word:
self.words.add(word)
# 读取altdns_wordlist.txt内容, 生成words元组def extract_words(self):
"""
Extend the dictionary based on target's domain naming conventions
"""
for subdomain in self.now_subdomains:
_, parts = split_domain(subdomain)
tokens = set(itertools.chain(*[word.lower().split('-') for word in parts]))
tokens = tokens.union({word.lower() for word in parts})
for token in tokens:
if len(token) >= self.wordlen:
self.words.add(token)
# 从上面收集的数据中,得到words
# eg: xiaotao.tao.com -> token=xiaotao def gen_new_subdomains(self):
for subdomain in self.now_subdomains:
subname, parts = split_domain(subdomain)
subnames = subname.split('.')
if settings.altdns_increase_num:
self.increase_num(subname)
# test.1.foo.example.com -> test.2.foo.example.com, test.3.foo.example.com, ...
# test1.example.com -> test2.example.com, test3.example.com, ...
# test01.example.com -> test02.example.com, test03.example.com, ...
if settings.altdns_decrease_num:
self.decrease_num(subname)
# test.4.foo.example.com -> test.3.foo.example.com, test.2.foo.example.com, ...
# test4.example.com -> test3.example.com, test2.example.com, ...
# test04.example.com -> test03.example.com, test02.example.com, ...
if settings.altdns_replace_word:
self.replace_word(subname)
# WORD1.1.foo.example.com -> WORD2.1.foo.example.com,
# WORD3.1.foo.example.com,
# WORD4.1.foo.example.com,
# ..
if settings.altdns_insert_word:
self.insert_word(parts)
# test.1.foo.example.com -> WORD.test.1.foo.example.com,
# test.WORD.1.foo.example.com,
# test.1.WORD.foo.example.com,
# test.1.foo.WORD.example.com,
# ...
if settings.altdns_add_word:
self.add_word(subnames)
# Prepend with `-`
# test.1.foo.example.com -> WORD-test.1.foo.example.com
# Prepend with `-`
# test.1.foo.example.com -> test-WORD.1.foo.example.com5种置换方式, 具体规则如上面代码注释
......
resolved_data = resolve.run_resolve(self.domain, self.results)
valid_data = wildcard.deal_wildcard(resolved_data) # 强制开启泛解析处理
request.run_request(self.domain, valid_data, port)
对生成的子域名,该模块会对其进行dns验证解析和http请求,利用的原理跟上面一样
0x2.2.11 丰富结果
# Information enrichment module
if settings.enable_enrich_module:
enrich = Enrich(self.domain)
enrich.run()
# 对结果信息进行丰富public、cidr、asn、org、addr、isp等内容,丰富更新数据库结果,不进行域名收集
public: 是否是公网IP
cidr: ip2location库查询出的CIDR
asn: ip2location库查询出的ASN
org:
addr:ip2region库查询出的物理地址
isp: ip2region库查询出的网络服务提供商
0x2.2.12 导出数据至csv文件
self.data = self.export_data() # 导出数据至csv文件
self.datas.extend(self.data)前面提及过export_data函数,于上面一样
0x2.2.13 子域名接管扫描模块
# Scan subdomain takeover
if self.takeover:
subdomains = utils.get_subdomains(self.data)
takeover = Takeover(targets=subdomains)
takeover.run()
# 扫描检测是否存在子域名接管漏洞 def run(self):
start = time.time()
logger.log('INFOR', f'Start running {self.source} module')
if isinstance(self.targets, set):
self.subdomains = self.targets
else:
self.subdomains = utils.get_domains(self.target, self.targets)
self.fmt = utils.check_format(self.fmt)
timestamp = utils.get_timestamp()
name = f'takeover_check_result_{timestamp}'
self.path = utils.check_path(self.path, name, self.fmt)
if self.subdomains:
logger.log('INFOR', f'Checking subdomain takeover')
self.fingerprints = get_fingerprint()
self.results.headers = ['subdomain', 'cname']
# 创建待检查的子域队列
for domain in self.subdomains:
self.queue.put(domain)
# 进度线程
progress_thread = Thread(target=self.progress, name='ProgressThread',
daemon=True)
progress_thread.start()
# 检查线程
for i in range(self.thread):
check_thread = Thread(target=self.check, name=f'CheckThread{i}',
daemon=True)
check_thread.start()
self.queue.join()
self.save()
else:
logger.log('FATAL', f'Failed to obtain domain')
end = time.time()
elapse = round(end - start, 1)
logger.log('ALERT', f'{self.source} module takes {elapse} seconds, '
f'There are {len(self.results)} subdomains exists takeover')
logger.log('INFOR', f'Subdomain takeover results: {self.path}')
logger.log('INFOR', f'Finished {self.source} module')具体参考:https://www.hackerone.com/application-security/guide-subdomain-takeovers
return self.data0x3 总结
看到这里,如果你仔细跟看几遍,那么你会明白的!最后,结合自己的需求进行二开,才是最好的利器!!