
前端成长进阶指北(网络篇)
点击上方 三分钟学前端,关注公众号
回复交流,加入前端编程面试算法每日一题群
嗨!各位早上好,三分钟学前端来一波第一季度回顾与总结,今天主讲 网络 篇 ,且已整理成了 pdf ,文末免费获取
下面进入正文吧👇
分别介绍下 http 和 tcp 协议,它们之间的区别与联系
TCP 协议对应于传输层,而 HTTP 协议对应于应用层,从本质上来说,二者没有可比性:
HTTP 对应于应用层,TCP 协议对应于传输层 HTTP 协议是在 TCP 协议之上建立的,HTTP 在发起请求时通过 TCP 协议建立起连接服务器的通道,请求结束后,立即断开 TCP 连接 HTTP 是无状态的短连接,而 TCP 是有状态的长连接 TCP是传输层协议,定义的是数据传输和连接方式的规范,HTTP是应用层协议,定义的是传输数据的内容的规范
HTTP/2对比HTTP/1.1,特性是什么?是如何解决队头阻塞与压缩头部的?
自从 1997 年 HTTP/1.1 发布以来,我们已经使用 HTTP/1.x 相当长一段时间了,但近几年内容的爆炸式成长使得 HTTP/1.1 越来越无法满足现代网络的需求了,HTTP/1.1 协议的性能缺陷:
高延迟:页面访问速度下降 明文传输:不安全 无状态:头部巨大切重复 不支持服务器推送 HTTP/1.x 为了性能考虑,会引入雪碧图、将小图内联、使用多个域名等等的方式,但还是有一些关键点无法优化,例如HTTP头部巨大且重复、明文传输不安全、服务器不能主动推送等,要改变这些必须重新设计 HTTP 协议,于是 HTTP/2 就出来了!
2015 年,HTTP/2 发布。HTTP/2 是现行 HTTP 协议(HTTP/1.x)的替代,但它不是重写,HTTP 方法 / 状态码 / 语义都与 HTTP/1.x 一样。HTTP/2 基于 SPDY,专注于性能,最大的目标是在用户和网站间只用一个连接(connec-tion)。
二进制传输 Header 压缩(HPACK) 多路复用 服务端 Push 提高安全性 HTTP/2 遗留问题:
HTTP/2 也存在队头阻塞问题,比如丢包。 慢启动
HTTP/2对比HTTP/1.1,新特性是什么?是如何解决队头阻塞与压缩头部的?
说一下HTTP/3新特性,为什么选择使用UDP协议?
HTTP/2 使用二进制传输、Header 压缩(HPACK)、多路复用等,相较于 HTTP/1.1 大幅提高了数据传输效率,但它仍然存在着以下几个致命问题(主要由底层支撑的 TCP 协议造成):
建立连接时间长 队头阻塞问题相较于 HTTP/1.1 更严重 而修改 TCP 协议已经是一件不可能完成的任务,所以Google 就更起炉灶搞了一个基于 UDP 协议的 QUIC 协议:
基于 TCP 开发的设备和协议非常多,兼容困难 TCP 协议栈是 Linux 内部的重要部分,修改和升级成本很大 UDP 本身是无连接的、没有建链和拆链成本 UDP 的数据包无队头阻塞问题 UDP 改造成本小 QUIC 虽然基于 UDP,但是在原本的基础上新增了很多功能,比如多路复用、0-RTT、使用 TLS1.3 加密、流量控制、有序交付、重传等等功能
说一下 HTTP/3 新特性,为什么选择使用 UDP 协议?
有关 HTTP 缓存的首部字段说一下
常见的HTTP 缓存首部字段有:
Expires:响应头,代表该资源的过期时间 Cache-Control:请求/响应头,缓存控制字段,精确控制缓存策略 If-Modified-Since:请求头,资源最近修改时间,由浏览器告诉服务器 Last-Modified:响应头,资源最近修改时间,由服务器告诉浏览器 Etag:响应头,资源标识,由服务器告诉浏览器 If-None-Match:请求头,缓存资源标识,由浏览器告诉服务器 其中, 强缓存 :
Expires(HTTP/1.0) Cache-Control(HTTP/1.1) 协商缓存:
Last-Modified 和 If-Modified-Since(HTTP/1.0) ETag 和 If-None-Match(HTTP/1.1)
了解 HTTP 缓存吗?有关 HTTP 缓存的首部字段说一下 ?
HTTP 常见的响应码,拒绝服务资源是哪个?
RFC 把状态码分成五类,分别是:
1××: 请求已被接受正被处理,表示目前是协议处理的中间状态,还需要后续的操作 2××: 请求成功处理,报文已经收到并被正确处理 3××: 代表需要客户端采取进一步的操作才能完成请求,例如重定向,通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明 4××: 客户端错误,请求报文有误,服务器无法处理 5××: 服务器错误,服务器在处理请求时内部发生了错误 容易争论的点:
301、302 和 307区别(对 SEO 的影响) 401 和 404 的区别
HTTP 中的 keep-alive 有了解吗?它和多路复用的区别
HTTP/1.x keep-alive 与 HTTP/2 多路复用区别:
HTTP/1.x 是基于文本的,只能整体去传;HTTP/2 是基于二进制流的,可以分解为独立的帧,交错发送 HTTP/1.x keep-alive 必须按照请求发送的顺序返回响应;HTTP/2 多路复用不按序响应 HTTP/1.x keep-alive 为了解决队头阻塞,将同一个页面的资源分散到不同域名下,开启了多个 TCP 连接;HTTP/2 同域名下所有通信都在单个连接上完成 HTTP/1.x keep-alive 单个 TCP 连接在同一时刻只能处理一个请求(两个请求的生命周期不能重叠);HTTP/2 单个 TCP 同一时刻可以发送多个请求和响应
了解 HTTP/1.x 的 keep-alive 吗?它与 HTTP/2 多路复用的区别是什么?
http header怎么判断协议是不是 websocket
WebSocket 使用
ws或wss的统一资源标志符,通过判断 header 中是否包含Connection: Upgrade与Upgrade: websocket来判断当前是否需要升级到 websocket 协议,除此之外,它还包含Sec-WebSocket-Key、Sec-WebSocket-Version等header,当服务器同意 WebSocket 连接时,返回响应码101,它的 API 很简单。方法:
socket.send(data)socket.close([code], [reason])事件:
openmessageerrorclose
http header 怎么判断协议是不是 websocket
GET 与 POST 区别是什么?
w3school 给出的标准答案:
GET POST 后退按钮/刷新 无害 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 书签 可收藏为书签 不可收藏为书签 缓存 能被缓存 不能缓存 编码类型 application/x-www-form-urlencoded application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 历史 参数保留在浏览器历史中。 参数不会保存在浏览器历史中。 对数据长度的限制 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 无限制。 对数据类型的限制 只允许 ASCII 字符。 没有限制。也允许二进制数据。 安全性 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使用 GET ! POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 可见性 数据在 URL 中对所有人都是可见的。 数据不会显示在 URL 中。 从 HTTP 协议上看,GET 与 POST 的本质区别有两点:
请求行不同: GET:GET /uri HTTP/1.1 POST:POST /uri HTTP/1.1 对服务器资源的操作不同: GET:表示从服务器获取资源 POST:向指定的服务器资源提交数据(通常导致状态或服务器上的副作用的更改) 进阶:常见问题及解答:
POST 方法比 GET 方法安全? POST 方法会产生两个 TCP 数据包?
session 和 cookie 的区别
安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。 存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。 有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时(一般30分钟无操作)都会失效。 存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
傻傻分不清之 Cookie、Session、Token、JWT
如果让你去实现一个 CSRF 攻击你会怎么做?
了解 CSRF 常见的攻击方式,模拟攻击就很简单了,几种常见的攻击方式:
自动发起 GET 请求的 CSRF 自动发起 POST 请求的 CSRF 引诱用户点击链接的 CSRF 防护策略:
利用 Cookie 的 SameSite 属性 利用同源策略 Token 认证
除了CSRF,你还知道其它的攻击方式吗?
我所了解的,除了 CSRF ,还有:
XSS 攻击 SQL 注入攻击 DDoS 攻击 上传文件漏洞 DNS 查询攻击 结合上篇 如果让你去实现一个 CSRF 攻击你会怎么做? ,总共介绍了六种 web 攻击与防护,其中最重要的是 CSRF 攻击、 XSS 攻击,其余只做了解即可。
为什么说 HTTPS 比 HTTP 安全呢
HTTP 协议使用起来非常的方便,但是它存在一个致命的缺点:
不安全。HTTPS并非是应用层的一种新协议,其实是 HTTP+SSL/TLS 的简称HTTP 和 HTTPS 的区别:
HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的TLS(SSL)加密传输协议 HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443 HTTP 的连接很简单,是无状态的;HTTPS协议是由 HTTP+SSL/TLS 协议构建的可进行加密传输、身份认证的网络协议,比 HTTPS 协议安全。 针对抓包问题,HTTPS 可以防止用户在不知情的情况下通信链路被监听,对于主动授信的抓包操作是不提供防护的,因为这个场景用户是已经对风险知情。
DNS 协议是什么?完整查询过程?为什么选择使用 UDP 协议发起 DNS 查询?
DNS(Domain Name System:域名系统),与 HTTP、FTP 和 SMTP 一样,DNS 协议也是应用层的协议,用于将用户提供的主机名(域名)解析为 IP 地址
DNS完整查询过程👇:
首先搜索 浏览器的 DNS 缓存 ,缓存中维护一张域名与 IP 地址的对应表 如果没有命中😢,则继续搜索 操作系统的 DNS 缓存 如果依然没有命中🤦♀️,则操作系统将域名发送至 本地域名服务器 ,本地域名服务器查询自己的 DNS 缓存,查找成功则返回结果(注意:主机和本地域名服务器之间的查询方式是 递归查询 ) 若本地域名服务器的 DNS 缓存没有命中🤦,则本地域名服务器向上级域名服务器进行查询,通过以下方式进行 迭代查询 (注意:本地域名服务器和其他域名服务器之间的查询方式是迭代查询,防止根域名服务器压力过大):
首先本地域名服务器向根域名服务器发起请求,根域名服务器是最高层次的,它并不会直接指明这个域名对应的 IP 地址,而是返回顶级域名服务器的地址,也就是说给本地域名服务器指明一条道路,让他去这里寻找答案 本地域名服务器拿到这个顶级域名服务器的地址后,就向其发起请求,获取权限域名服务器的地址 本地域名服务器根据权限域名服务器的地址向其发起请求,最终得到该域名对应的 IP 地址
本地域名服务器 将得到的 IP 地址返回给操作系统,同时自己将 IP 地址 缓存 起来📝 操作系统 将 IP 地址返回给浏览器,同时自己也将 IP 地址 缓存 起来📝 至此, 浏览器 就得到了域名对应的 IP 地址,并将 IP 地址 缓存 起来📝 需要注意的是,DNS 使用了 UDP 协议来获取域名对应的 IP 地址,这个没错,但有些片面,准确的来说,DNS 查询在刚设计时主要使用 UDP 协议进行通信,而 TCP 协议也是在 DNS 的演进和发展中被加入到规范的:
DNS 在设计之初就在区域 传输中引入了 TCP 协议 , 在查询中使用 UDP 协议 ,它同时占用了 UDP 和 TCP 的 53 端口 当 DNS 超过了 512 字节的限制,我们第一次在 DNS 协议中明确了 『当 DNS 查询被截断时,应该使用 TCP 协议进行重试』 这一规范; 随后引入的 EDNS 机制允许我们使用 UDP 最多传输 4096 字节的数据,但是由于 MTU 的限制导致的数据分片以及丢失,使得这一特性不够可靠; 在最近的几年,我们重新规定了 DNS 应该同时支持 UDP 和 TCP 协议,TCP 协议也不再只是重试时的选择;
DNS 协议是什么?完整查询过程?为什么选择使用 UDP 协议发起 DNS 查询?
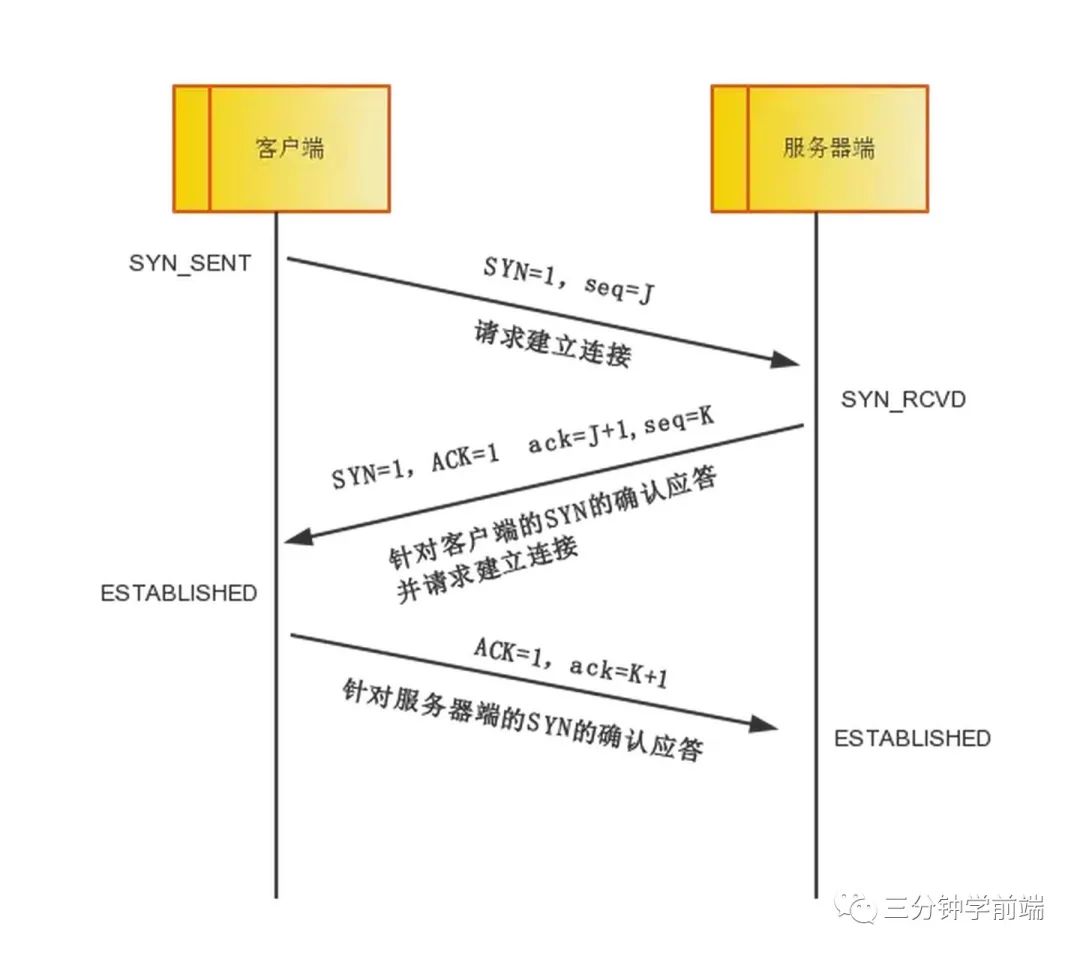
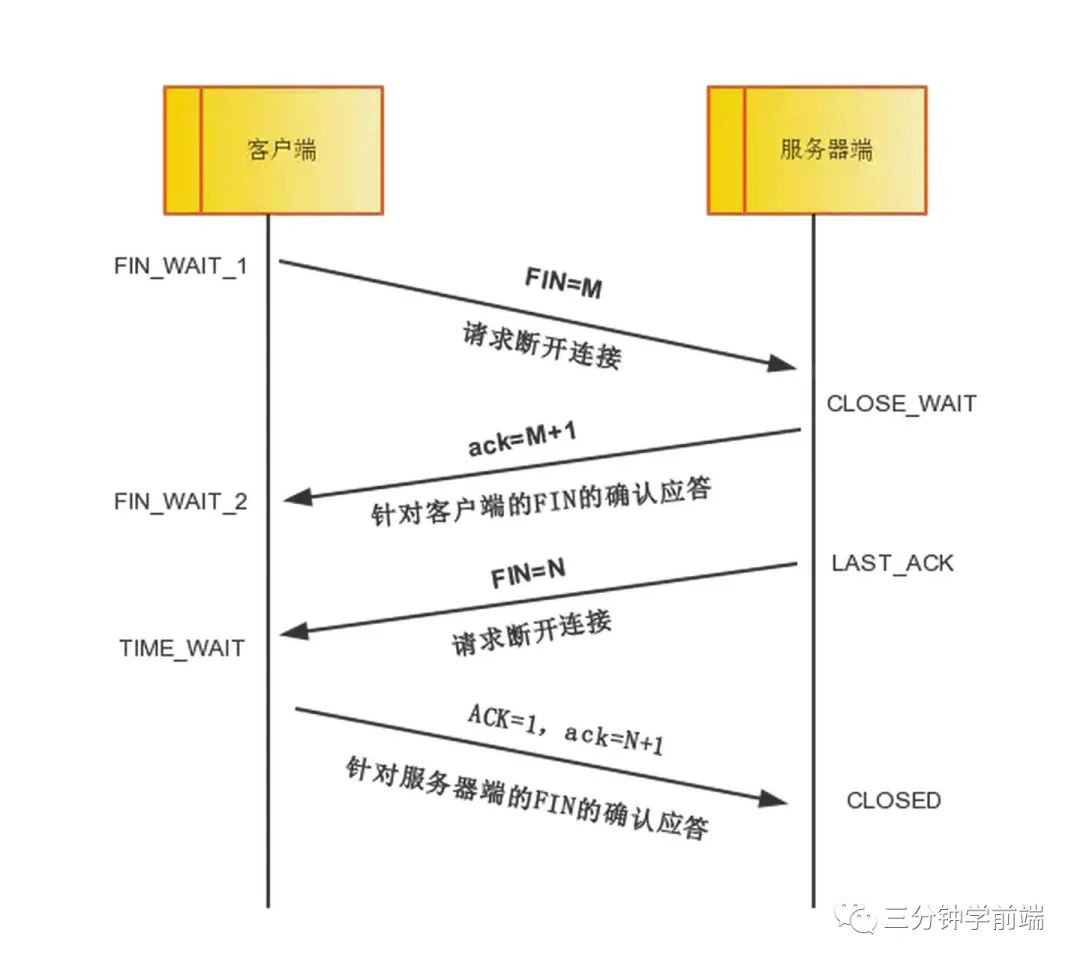
TCP 的三次握手和四次挥手,了解泛洪攻击么
TCP 三次握手(连接过程)
TCP 四次挥手(断开链接)
我们已经知道,TCP 只有经过三次握手才能连接,而 SYN 泛洪攻击就是针对 TCP 握手过程进行攻击:
攻击者发送大量的 SYN 包给服务器(第一次握手成功) 服务器回应(SYN + ACK)包(第二次握手成功) 但是攻击者不回应 ACK 包(第三次握手不进行) 导致服务器存在大量的半开连接,这些半连接可以耗尽服务器资源,使被攻击服务器无法再响应正常 TCP 连接,从而达到攻击的目的
关注「三分钟学前端」
回复「网络」,自动获取三分钟学前端网络篇小书(90+页)
回复「JS」,自动获取三分钟学前端 JS 篇小书(120+页)
回复「算法」,自动获取 github 2.9k+ 的前端算法小书
回复「面试」,自动获取 github 23.2k+ 的前端面试小书
回复「简历」,自动获取程序员系列的 120 套模版
最近开源了一个github仓库:百问百答,在工作中很难做到对社群问题进行立即解答,所以可以将问题提交至 https://github.com/Advanced-Frontend/Just-Now-QA ,我会在每晚花费 1 个小时左右进行处理,更多的是鼓励与欢迎更多人一起参与探讨与解答🌹