
工程启动抖动的排查(JIT)
作者:Adrian
来源:SegmentFault 思否社区
1. 前言
本文仅分享自己在工作中遇到的问题时的解决方案和思路,以及排查的过程。重点还是分享排查的思路,知识点其实已经挺老了。如有疑问或描述不妥,欢迎赐教。
2. 问题表象
在工程启动的时候,系统的请求会有一波超时,从监控来看,JVM 的GC(G1) 波动较大,CPU波动较大,各个业务使用的线程池波动较大,外部IO耗时增加。
3. 先说结论
由于JIT的优化,导致系统启动时触发了热点代码的编译,且为C2编译,引发了CPU占用较高,进而引发一系列问题,最终导致部分请求超时。
4. 排查过程
4.1 最初的排查
其实我们的工程是一个算法排序工程,里面或多或少也加了一些小的模型和大大小小的缓存,而且从监控上来看,JVM 的GC 突刺和 CPU 突刺时间极为接近(这也是一个监控平台时间不够精准的原因)。所以在前期,我耗费了大量精力和时间去排查JVM,GC 的问题。
首先推荐给大家一个网站:https://gceasy.io/ ,真的分析GC日志巨好用。配合以下的JVM参数打印GC日志:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式,你启动的时候相当于12点,跟真实时间无关)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-Xloggc:../logs/gc.log 日志文件的输出路因为看到YGC严重,所以先后尝试了如下的方法:
调整JVM 的堆大小。即 -Xms, -Xmx 参数。无效。
调整回收线程数目。即 -XX:ConcGCThreads 参数。无效。
调整期望单次回收时间。即 -XX:MaxGCPauseMillis 参数,无效,甚至更惨。
以上调整混合测试,均无效。
鸡贼的方法。在加载模型之后sleep 一段时间,让GC平稳,然后再放请求进来,这样操作之后GC确实有些好转,但是刚开始的请求仍然有超时。(当然了,因为问题根本不在GC上)
4.2 换个思路
根据监控上来看,线程池,外部IO,启动时都有明显的RT上升然后下降,而且趋势非常一致,这种一般都是系统性问题造成的,比如CPU,GC,网卡,云主机超售,机房延迟等等。所以GC既然无法根治,那么就从CPU方面入手看看。
因为系统启动时JVM会产生大量GC,无法区分是由于系统启动还没预热好就来了流量还是说无论启动了多久,流量一来就会出问题。而我之前排查GC 的操作,即加sleep时间,恰好帮我看到了这个问题,因为能明显的看出,GC波动的时间,和超时的时间,时间点上已经差了很多了,那就是说,与GC无关,无论GC已经多么平稳,流量一来,还是要超时。
4.3 分析利器Arthas
Arthas 文档:
https://arthas.aliyun.com/doc/quick-start.html
其实要分析的核心还是流量最开始到来的时候,我们的CPU到底做了什么,于是我们使用Arthas分析流量到来时的CPU情况。其实这部分也可以使用top -Hp pid , jstack 等命令配合完成,不展开叙述。
CPU情况,仅展示重要部分:

4.4 问题的核心
那么这个C2 CompilerThread 究竟是什么呢。
《深入理解JAVA虚拟机》其实有对这部分的叙述,这里我就大白话给大家解释一下。
其实Java在最开始运行的时候,你可以理解为,就是傻乎乎的按照你写的代码执行下去,称之为"解释器",这样有一个好处,就是很快,Java搞成.class ,很快就能启动,跑起来了,但是问题也很明显啊,就是运行的慢,那么聪明的JVM开发者们做了一件事情,他们如果发现你有一些代码频繁的执行,那么他们就会在运行期间帮你把这段代码编译成机器码,这样运行就会飞快,这就是即时编译(just-in-time compilation 也就是JIT)。但是这样也有一个问题,就是编译的那段时间,耗费CPU。而C2 CompilerThread,正是JIT中的一层优化(共计五层,C2 是第五层)。所以,罪魁祸首找到了。
5. 尝试解决
解释器和编译器的关系可以如下所示:
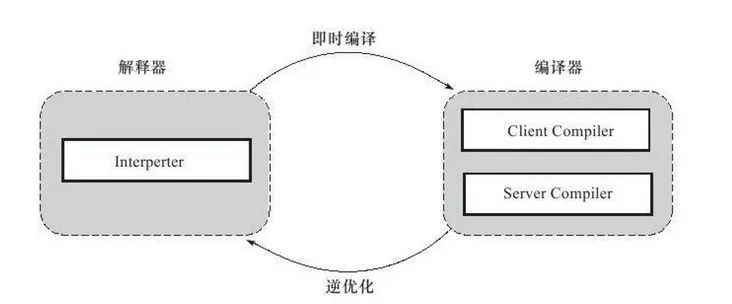
就像上面说的,解释器启动快,但是执行慢。而编译器又分为以下五个层次。
第 0 层:程序解释执行,默认开启性能监控功能(Profiling),如果不开启,可触发第二层编译;
第 1 层:可称为 C1 编译,将字节码编译为本地代码,进行简单、可靠的优化,不开启 Profiling;
第 2 层:也称为 C1 编译,开启 Profiling,仅执行带方法调用次数和循环回边执行次数 profiling 的 C1 编译;
第 3 层:也称为 C1 编译,执行所有带 Profiling 的 C1 编译;
第 4 层:可称为 C2 编译,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化所以我们可以尝试从C1,C2编译器的角度去解决问题。
5.1 关闭分层编译
增加参数 :-XX:-TieredCompilation -client (关闭分层编译,开启C1编译)
效果稀烂。
CPU使用率持续高水位(相比于调整前)。确实没了C2 thread 的问题,但是猜测由于代码编译的不够C2那么优秀,所以代码持续性能低下。
CPU截图:

5.2 增加C2 线程数
增加参数 :-XX:CICompilerCount=8 恢复参数:-XX:+TieredCompilation
效果一般,仍然有请求超时。但是会少一些。
CPU截图:

5.3 推论
其实从上面的分析可以看出,如果绕不过C2,那么必然会有一些抖动,如果绕过了C2,那么整体性能就会低很多,这是我们不愿看见的,所以关闭C1,C2,直接以解释器模式运行我并没有尝试。
5.4 最终方案
既然这部分抖动绕不过去,那么我们可以使用一些mock 流量来承受这部分抖动,也可以称之为预热,在工程启动的时候,使用提前录制好的流量来使系统热点代码完成即时编译,然后再接收真正的流量,这样就可以做到真实流量不抖动的效果。
后话
本文着重分享解决和分析的过程,知识点没有重点分析。更多知识点请看“参考文章”部分。 本文如有问题欢迎各位校正。
参考文章
【关于java:-XX:-TieredCompilation到底做什么】https://www.codenong.com/38721235/ 【好像是上面那篇文章的原版】 https://stackoverflow.com/questions/38721235/what-exactly-does-xx-tieredcompilation-do 【C2 Compiler Thread】 https://blog.csdn.net/chenxiusheng/article/details/74007750 【C2 CompilerThread9 长时间占用CPU解决方案】https://blog.csdn.net/m0_37886429/article/details/105139611 《深入理解Java虚拟机第二版》第四部分的“晚期(运行期)优化” 【深入分析JVM中线程的创建和运行原理 || JIT(future)】 https://www.cnblogs.com/silyvin/p/10228184.html 【HotSpot虚拟机的分层编译(Tiered Compilation)】 https://blog.csdn.net/u013490280/article/details/108522427
