
详解 | 大型分布式电商系统架构

- 前言 -
- 大型分布式网站架构技术 -
1、大型网站的特点
用户多,分布广泛。 大流量,高并发。 海量数据,服务高可用。 安全环境恶劣,易受网络攻击。 功能多,变更快,频繁发布。 从小到大,渐进发展。 以用户为中心。 免费服务,付费体验。
2、大型网站架构目标
高性能:提供快速的访问体验。 高可用:网站服务一直可以正常访问。 可伸缩:通过硬件增加/减少,提高/降低处理能力。 安全性:提供网站安全访问和数据加密、安全存储等策略。 扩展性:方便地通过新增/移除方式,增加/减少新的功能/模块。 敏捷性:随需应变,快速响应。

3、大型网站架构模式

分层:一般可分为应用层、服务层、数据层、管理层与分析层。 分割:一般按照业务/模块/功能特点进行划分,比如应用层分为首页、用户中心。 分布式:将应用分开部署(比如多台物理机),通过远程调用协同工作。 集群:一个应用/模块/功能部署多份(如:多台物理机),通过负载均衡共同提供对外访问。 缓存:将数据放在距离应用或用户最近的位置,加快访问速度。 异步:将同步的操作异步化。客户端发出请求,不等待服务端响应,等服务端处理完毕后,使用通知或轮询的方式告知请求方。一般指:请求——响应——通知模式。 冗余:增加副本,提高可用性、安全性与性能。 安全:对已知问题有有效的解决方案,对未知/潜在问题建立发现和防御机制。 自动化:将重复的、不需要人工参与的事情,通过工具的方式,使用机器完成。 敏捷性:积极接受需求变更,快速响应业务发展需求。
4、高性能架构
前端优化:网站业务逻辑之前的部分; 浏览器优化:减少HTTP请求数,使用浏览器缓存,启用压缩,CSS JS位置,JS异步,减少Cookie传输;CDN加速,反向代理; 应用层优化:处理网站业务的服务器。使用缓存,异步,集群 代码优化:合理的架构,多线程,资源复用(对象池,线程池等),良好的数据结构,JVM调优,单例,Cache等; 存储优化:缓存、固态硬盘、光纤传输、优化读写、磁盘冗余、分布式存储(HDFS)、NoSQL等。
5、高可用架构
应用层:一般设计为无状态的,对于每次请求,使用哪一台服务器处理是没有影响的。一般使用负载均衡技术(需要解决Session同步问题)实现高可用。 服务层:负载均衡,分级管理,快速失败(超时设置),异步调用,服务降级,幂等设计等。 数据层:冗余备份(冷,热备[同步,异步],温备),失效转移(确认,转移,恢复)。数据高可用方面著名的理论基础是CAP理论(持久性,可用性,数据一致性[强一致,用户一致,最终一致])
6、可伸缩架构
应用层:对应用进行垂直或水平切分。然后针对单一功能进行负载均衡(DNS、HTTP[反向代理]、IP、链路层)。 服务层:与应用层类似; 数据层:分库、分表、NoSQL等;常用算法Hash,一致性Hash。
7、可扩展架构
模块化,组件化:高内聚,低耦合,提高复用性,扩展性。 稳定接口:定义稳定的接口,在接口不变的情况下,内部结构可以“随意”变化。 设计模式:应用面向对象思想,原则,使用设计模式,进行代码层面的设计。 消息队列:模块化的系统,通过消息队列进行交互,使模块之间的依赖解耦。 分布式服务:公用模块服务化,提供其他系统使用,提高可重用性,扩展性。
8、安全架构
基础设施安全:硬件采购,操作系统,网络环境方面的安全。一般采用正规渠道购买高质量的产品,选择安全的操作系统,及时修补漏洞,安装杀毒软件防火墙。防范病毒,后门。设置防火墙策略,建立DDOS防御系统,使用攻击检测系统,进行子网隔离等手段。 应用系统安全:在程序开发时,对已知常用问题,使用正确的方式,在代码层面解决掉。防止跨站脚本攻击(XSS),注入攻击,跨站请求伪造(CSRF),错误信息,HTML注释,文件上传,路径遍历等。还可以使用Web应用防火墙(比如:ModSecurity),进行安全漏洞扫描等措施,加强应用级别的安全。 数据保密安全:存储安全(存储在可靠的设备,实时,定时备份),保存安全(重要的信息加密保存,选择合适的人员复杂保存和检测等),传输安全(防止数据窃取和数据篡改)。
9、敏捷性
10、大型架构举例
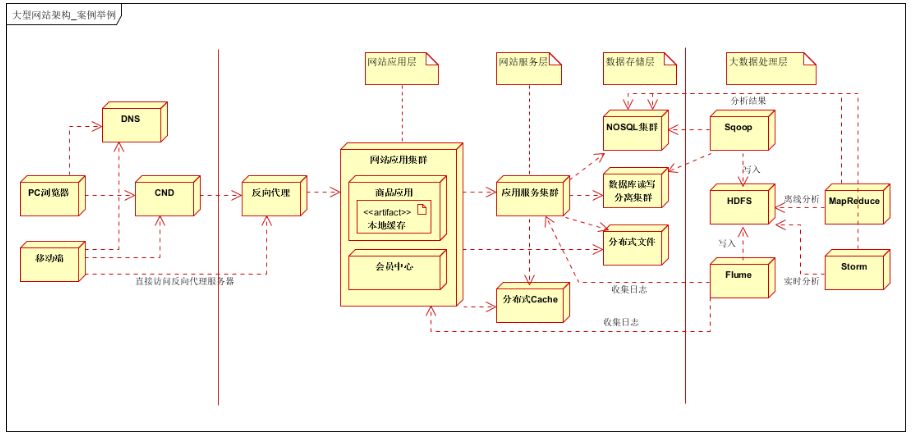
客户层:支持PC浏览器和手机APP。差别是手机APP可以直接通过IP访问,反向代理服务器。 前端层:使用DNS负载均衡,CDN本地加速以及反向代理服务。 应用层:网站应用集群;按照业务进行垂直拆分,比如商品应用,会员中心等。 服务层:提供公用服务,比如用户服务,订单服务,支付服务等。 数据层:支持关系型数据库集群(支持读写分离),NOSQL集群,分布式文件系统集群;以及分布式Cache。 大数据存储层:支持应用层和服务层的日志数据收集,关系数据库和NOSQL数据库的结构化和半结构化数据收集。 大数据处理层:通过Mapreduce进行离线数据分析或Storm实时数据分析,并将处理后的数据存入关系型数据库。(实际使用中,离线数据和实时数据会按照业务要求进行分类处理,并存入不同的数据库中,供应用层或服务层使用)。
- 大型电商网站系统架构演变过程 -
1、最开始的网站架构
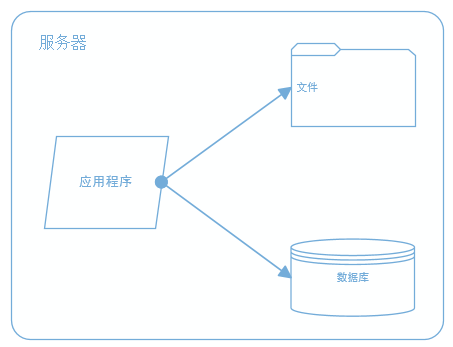
2、应用、数据、文件分离

3、利用缓存改善网站性能

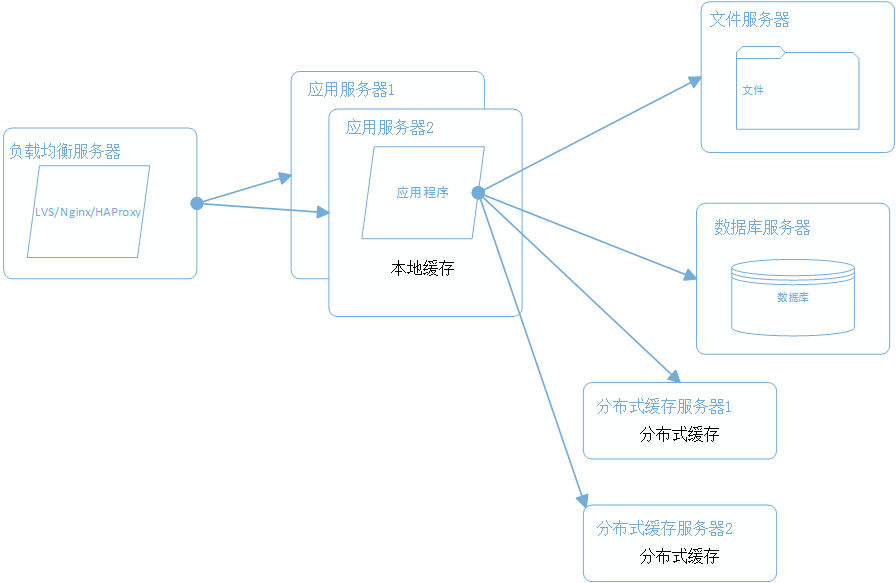
4、使用集群改善应用服务器性能
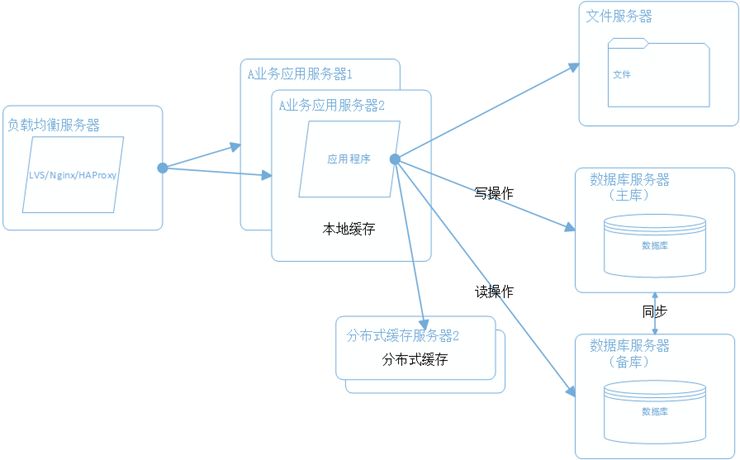
5、数据库读写分离和分库分表
6、使用CDN和反向代理提高网站性能
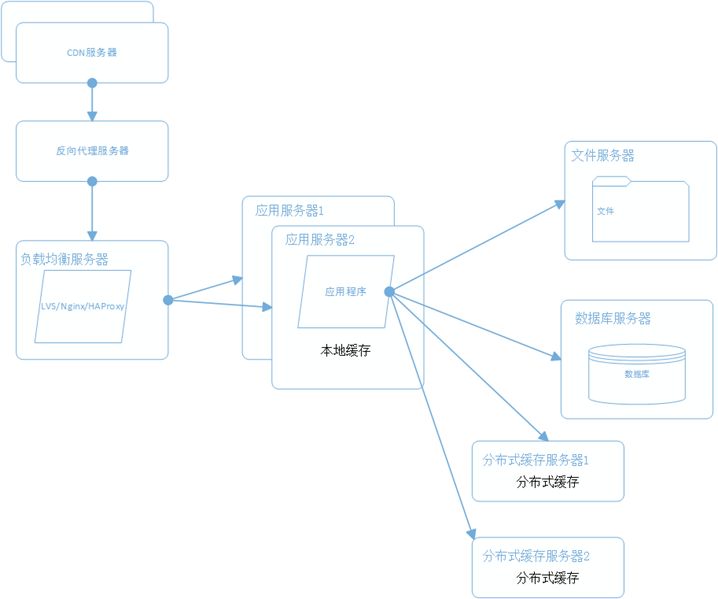
7、使用分布式文件系统

8、使用NoSQL和搜索引擎
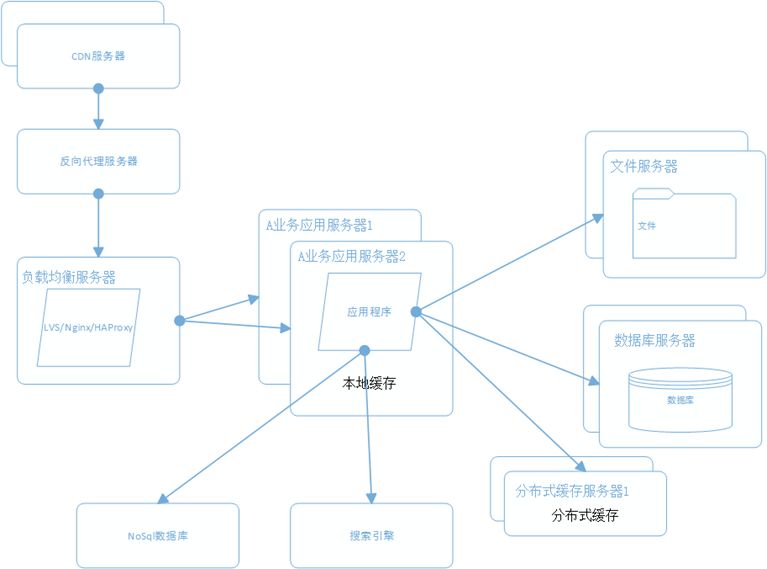
9、将应用服务器进行业务拆分

10、搭建分布式服务
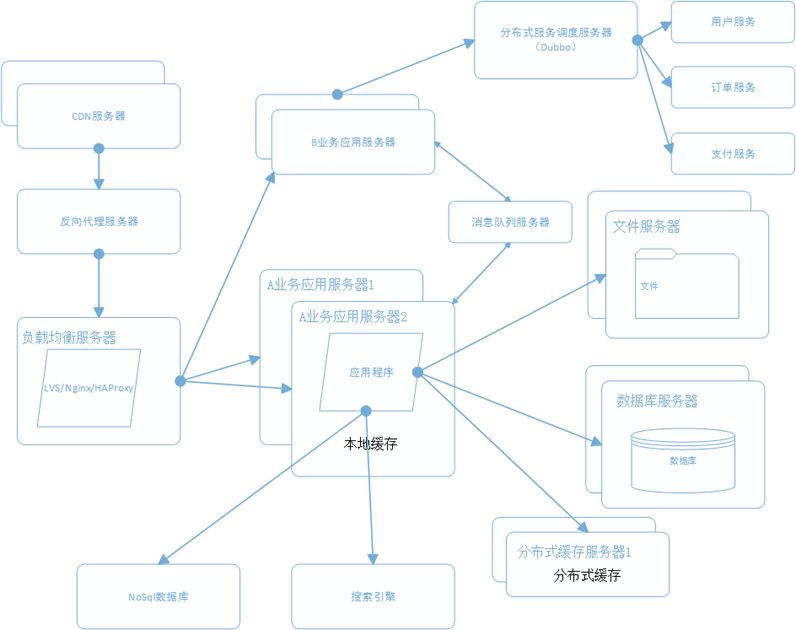
- 一张图说明电商架构 -
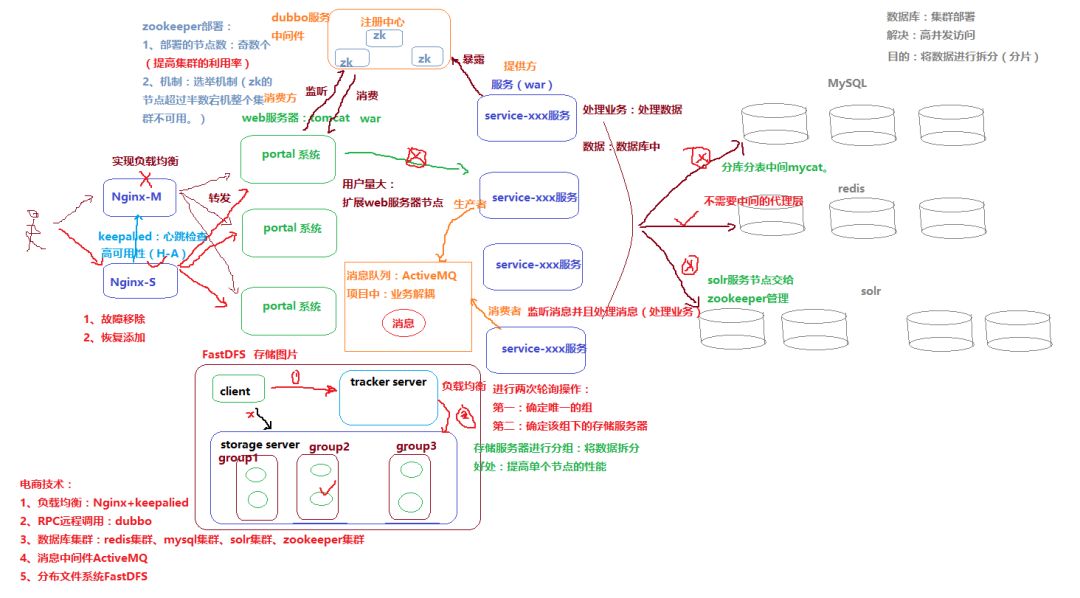
- 大型电商网站架构案例 -
分布式大型网站,目前看主要有几类:
大型门户,比如网易,新浪等; SNS网站,比如校内,开心网等; 电商网站,比如阿里巴巴,京东商城,国美在线,汽车之家等。
客户需求:
建立一个全品类的电子商务网站(B2C),用户可以在线购买商品,可以在线支付,也可以货到付款; 用户购买时可以在线与客服沟通; 用户收到商品后,可以给商品打分,评价; 目前有成熟的进销存系统;需要与网站对接; 希望能够支持3~5年,业务的发展; 预计3~5年用户数达到1000万; 定期举办双11、双12、三八男人节等活动; 其他的功能参考京东或国美在线等网站。
需求功能矩阵
需求管理传统的做法,会使用用例图或模块图(需求列表)进行需求的描述。这样做常常忽视掉一个很重要的需求(非功能需求),因此推荐大家使用需求功能矩阵,进行需求描述。
本电商网站的需求矩阵如下:

一般网站,刚开始的做法,是三台服务器,一台部署应用,一台部署数据库,一台部署NFS文件系统。
这是前几年比较传统的做法,之前见到一个网站10万多会员,垂直服装设计门户,N多图片。使用了一台服务器部署了应用,数据库以及图片存储。出现了很多性能问题。
如下图:
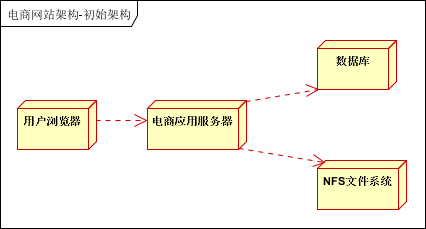

使用集群对应用服务器进行冗余,实现高可用;(负载均衡设备可与应用一块部署) 使用数据库主备模式,实现数据备份和高可用;
预估步骤:
注册用户数-日均UV量-每日的PV量-每天的并发量; 峰值预估:平常量的2~3倍; 根据并发量(并发,事务数),存储容量计算系统容量。
每天的UV为200万(二八原则); 每日每天点击浏览30次; PV量:200*30=6000万; 集中访问量:24*0.2=4.8小时会有6000万*0.8=4800万(二八原则); 每分并发量:4.8*60=288分钟,每分钟访问4800/288=16.7万(约等于); 每秒并发量:16.7万/60=2780(约等于); 假设:高峰期为平常值的三倍,则每秒的并发数可以达到8340次。 1毫秒=1.3次访问;
服务器预估:(以tomcat服务器举例)
按一台web服务器,支持每秒300个并发计算。平常需要10台服务器(约等于);[tomcat默认配置是150],高峰期需要30台服务器;
容量预估:70/90原则
系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的。内存,IO类似。
以上预估仅供参考,因为服务器配置,业务逻辑复杂度等都有影响。在此CPU,硬盘,网络等不再进行评估。
5、网站架构分析
根据以上预估,有几个问题:
需要部署大量的服务器,高峰期计算,可能要部署30台Web服务器。并且这三十台服务器,只有秒杀,活动时才会用到,存在大量的浪费。 所有的应用部署在同一台服务器,应用之间耦合严重。需要进行垂直切分和水平切分。 大量应用存在冗余代码。 服务器Session同步耗费大量内存和网络带宽。 数据需要频繁访问数据库,数据库访问压力巨大。
业务拆分 应用集群部署(分布式部署,集群部署和负载均衡) 多级缓存 单点登录(分布式Session) 数据库集群(读写分离,分库分表) 服务化 消息队列 其他技术
- 网站架构优化 -
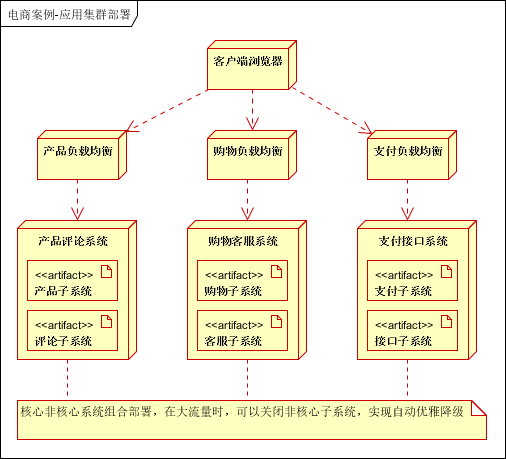
根据业务属性进行垂直切分,划分为产品子系统,购物子系统,支付子系统,评论子系统,客服子系统,接口子系统(对接如进销存,短信等外部系统)。
根据业务子系统进行等级定义,可分为核心系统和非核心系统。核心系统:产品子系统,购物子系统,支付子系统;非核心:评论子系统,客服子系统,接口子系统。
业务拆分作用:提升为子系统可由专门的团队和部门负责,专业的人做专业的事,解决模块之间耦合以及扩展性问题;每个子系统单独部署,避免集中部署导致一个应用挂了,全部应用不可用的问题。 等级定义作用:用于流量突发时,对关键应用进行保护,实现优雅降级;保护关键应用不受到影响。


分布式部署:将业务拆分后的应用单独部署,应用直接通过RPC进行远程通信; 集群部署:电商网站的高可用要求,每个应用至少部署两台服务器进行集群部署; 负载均衡:是高可用系统必须的,一般应用通过负载均衡实现高可用,分布式服务通过内置的负载均衡实现高可用,关系型数据库通过主备方式实现高可用。
缓存按照存放的位置一般可分为两类本地缓存和分布式缓存。本案例采用二级缓存的方式,进行缓存的设计。一级缓存为本地缓存,二级缓存为分布式缓存。(还有页面缓存,片段缓存等,那是更细粒度的划分)
一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存。当一级缓存过期或不可用时,访问二级缓存的数据。如果二级缓存也没有,则访问数据库。
缓存的比例,一般1:4,即可考虑使用缓存。(理论上是1:2即可)。
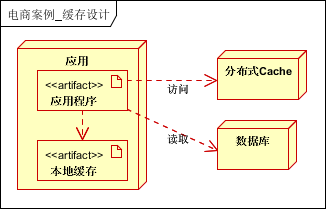
缓存自动过期; 缓存触发过期。
系统分割为多个子系统,独立部署后,不可避免的会遇到会话管理的问题。一般可采用Session同步,Cookies,分布式Session方式。电商网站一般采用分布式Session实现。
再进一步可以根据分布式Session,建立完善的单点登录或账户管理系统。
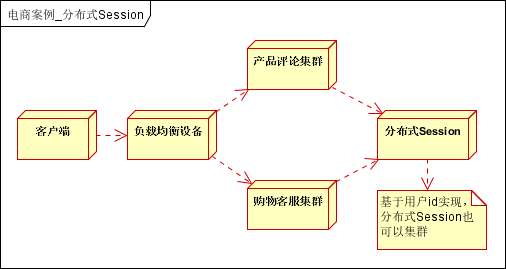
用户第一次登录时,将会话信息(用户Id和用户信息),比如以用户Id为Key,写入分布式Session; 用户再次登录时,获取分布式Session,是否有会话信息,如果没有则调到登录页; 一般采用Cache中间件实现,建议使用Redis,因此它有持久化功能,方便分布式Session宕机后,可以从持久化存储中加载会话信息; 存入会话时,可以设置会话保持的时间,比如15分钟,超过后自动超时。
5、数据库集群(读写分离,分库分表)
大型网站需要存储海量的数据,为达到海量数据存储,高可用,高性能一般采用冗余的方式进行系统设计。一般有两种方式读写分离和分库分表。
读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
本案例在业务拆分的基础上,结合分库分表和读写分离。如下图:
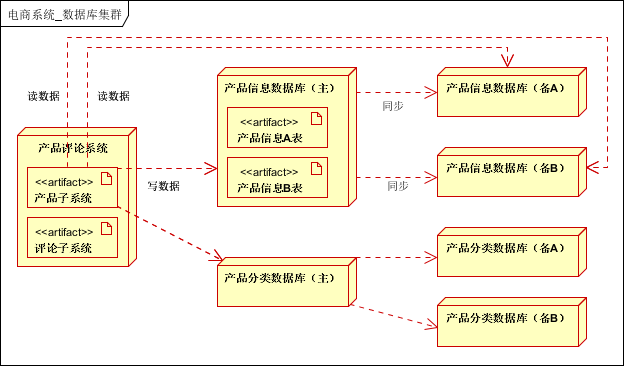
业务拆分后:每个子系统需要单独的库; 如果单独的库太大,可以根据业务特性,进行再次分库,比如商品分类库,产品库; 分库后,如果表中有数据量很大的,则进行分表,一般可以按照Id,时间等进行分表;(高级的用法是一致性Hash) 在分库、分表的基础上,进行读写分离。
分库分表后序列的问题,JOIN,事务的问题,会在分库分表主题分享中,介绍。
6、服务化
将多个子系统公用的功能/模块,进行抽取,作为公用服务使用。比如本案例的会员子系统就可以抽取为公用的服务。
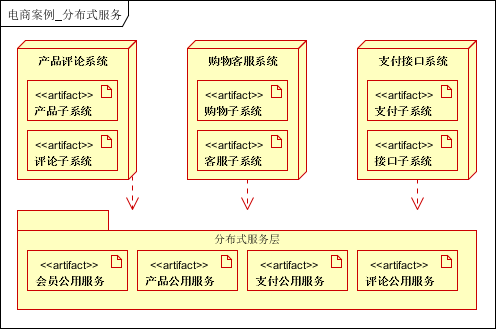
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统。是分布式系统的标准配置。本案例中,消息队列主要应用在购物,配送环节。
用户下单后,写入消息队列,后直接返回客户端; 库存子系统:读取消息队列信息,完成减库存; 配送子系统:读取消息队列信息,进行配送。

目前使用较多的MQ有Active MQ、Rabbit MQ、Zero MQ、MS MQ等,需要根据具体的业务场景进行选择。建议可以研究下Rabbit MQ。
8、其他架构(技术)
除了以上介绍的业务拆分,应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。
此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。
- 架构汇总 -
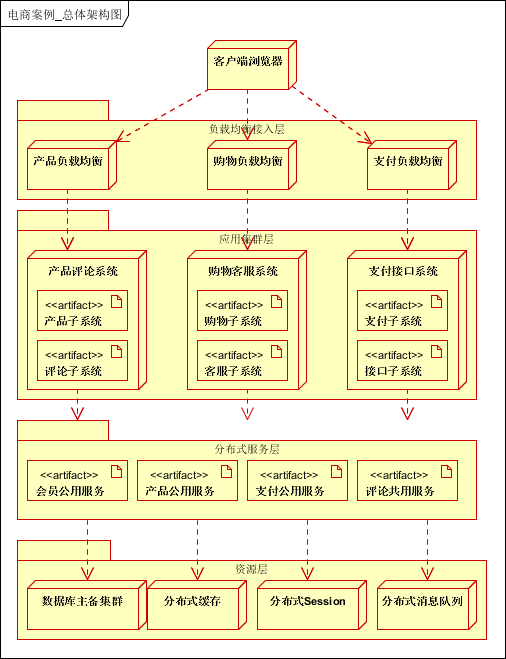
作者:烂猪皮,十余年工作经验,曾在 Google 等外企工作过几年,精通 Java、分布式架构、微服务架构以及数据库,最近正在研究大数据以及区块链,希望能突破到更高的境界。
来源:
https://my.oschina.net/editorial-story/blog/1808757

评论