
盘点那些强大又低调的 Java 缓存
点击关注公众号,Java干货及时送达
这篇文章,笔者想聊聊那些在业务系统中较少被使用,但却活跃于中间件或者框架里,强大却又低调的缓存,笔者愿称他们为缓存世界的扫地僧。
1 HashMap/ConcurrentHashMap 配置缓存
HashMap 是一种基于哈希表的集合类,它提供了快速的插入、查找和删除操作。
HashMap 是很多程序员接触的第一种缓存 , 因为现实业务场景里,我们可能需要给缓存添加缓存统计、过期失效、淘汰策略等功能,HashMap 的功能就显得孱弱 ,所以 HashMap 在业务系统中使用得并不算多。
但 HashMap 在中间件中却是香饽饽,我们消息中间件 RocketMQ 为例。
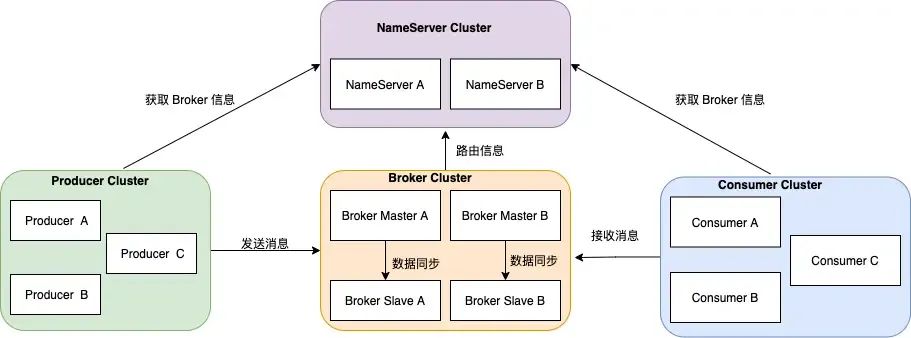
上图是 RocketMQ 的集群模式 ,Broker 分为 Master 与 Slave,一个 Master 可以对应多个 Slave,但是一个 Slave 只能对应一个 Master。
每个 Broker 与 Name Server 集群中的所有节点建立长连接,定时每隔 30 秒注册 主题的路由信息到所有 Name Server。
消息发送者、消息消费者,在同一时间只会连接 Name Server 集群中的一台服务器,并且会每隔 30s 会定时更新 Topic 的路由信息。
我们可以理解 Name Server 集群的作用就是注册中心,注册中心会保存路由信息(主题的读写队列数、操作权限等),路由信息就是保存在 HashMap 中 。
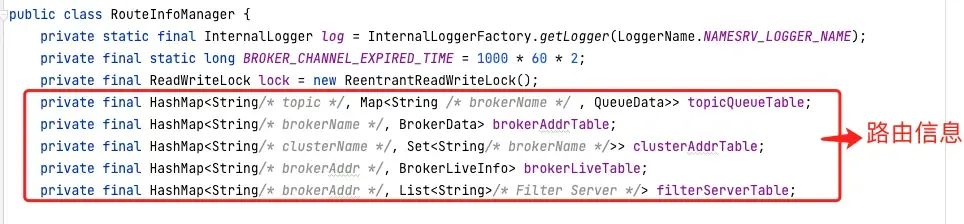
路由信息通过几个 HashMap 来保存,当 Broker 向 Nameserver 发送心跳包(路由信息),Nameserver 需要对 HashMap 进行数据更新,但我们都知道 HashMap 并不是线程安全的,高并发场景下,容易出现 CPU 100% 问题,所以更新 HashMap 时需要加锁,RocketMQ 使用了 JDK 的读写锁 ReentrantReadWriteLock 。
下面我们看下路由信息如何更新和读取:
1、写操作:更新路由信息,操作写锁
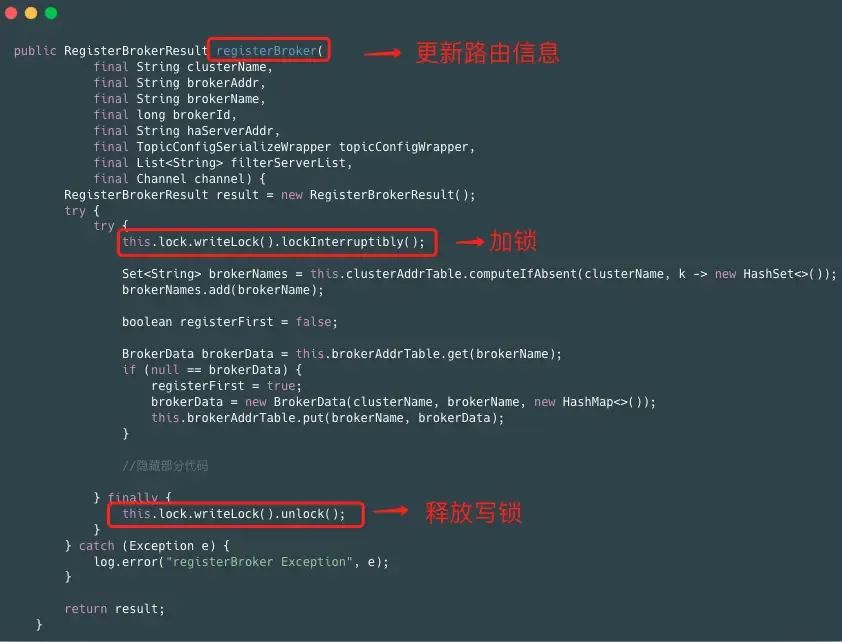
2、读操作:查询主题信息,操作读锁
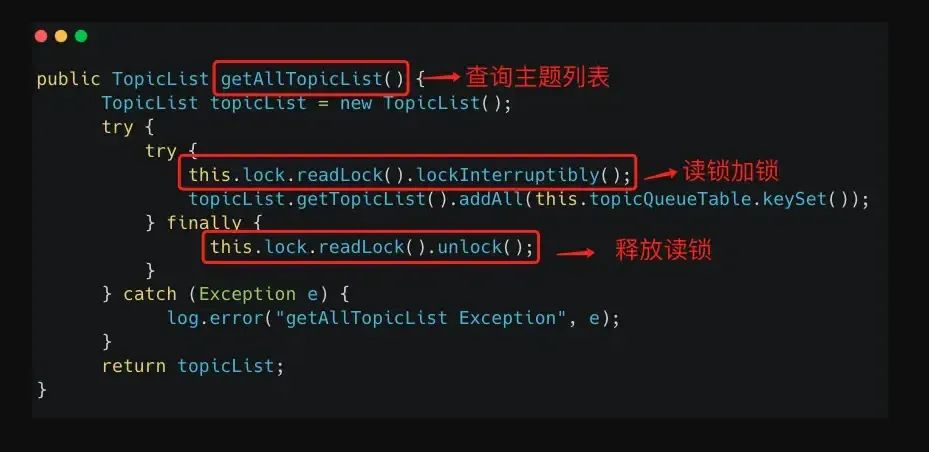
同时,我们需要注意 Name Server 维护路由信息还需要定时任务的支撑。
-
每个 Broker 定时每隔 30 秒注册 主题的路由信息到所有 Name Server
-
Name Server 定时任务每隔10 秒清除已宕机的 Broker
我们做一个小小的总结,Name Server 维护路由的模式是:HashMap + 读写锁 + 定时任务更新。
-
HashMap 作为存储容器
-
读写锁控制锁的颗粒度
-
定时任务定时更新缓存
写到这里,我们不禁想到 ConcurrentHashMap。
ConcurrentHashMap 可以保证线程安全,JDK1.7 之前使用分段锁机制实现,JDK1.8 则使用数组+链表+红黑树数据结构和CAS原子操作实现。
Broker 使用不同的 ConcurrentHashMap 分别用来存储消费组、消费进度、消息过滤信息等。
那么名字服务为什么不使用 ConcurrentHashMap 作为存储容器呢 ?
最核心的原因在于:路由信息由多个 HashMap 组成,通过每次写操作可能要操作多个对象 ,为了保证其一致性,所以才需要加读写锁。
2 LinkedHashMap 最近最少使用缓存
LinkedHashMap 是 HashMap 的子类,但是内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。
LinkedHashMap 支持两种顺序插入顺序 、 访问顺序。
-
插入顺序:先添加的在前面,后添加的在后面,修改操作并不影响顺序
-
访问顺序:问指的是 get/put 操作,对一个键执行 get/put 操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。
LinkedHashMap 经典的用法是作为 LruCache (最近最少使用缓存) ,而 MyBatis 的二级缓存的淘汰机制就是使用的 LinkedHashMap 。
MyBatis 的二级缓存是使用责任链+ 装饰器的设计模式实现的。
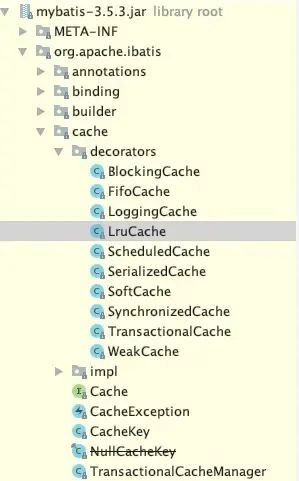
上图中,装饰器包目录下 Cache 接口有不同的实现类,比如过期淘汰、日志记录等。
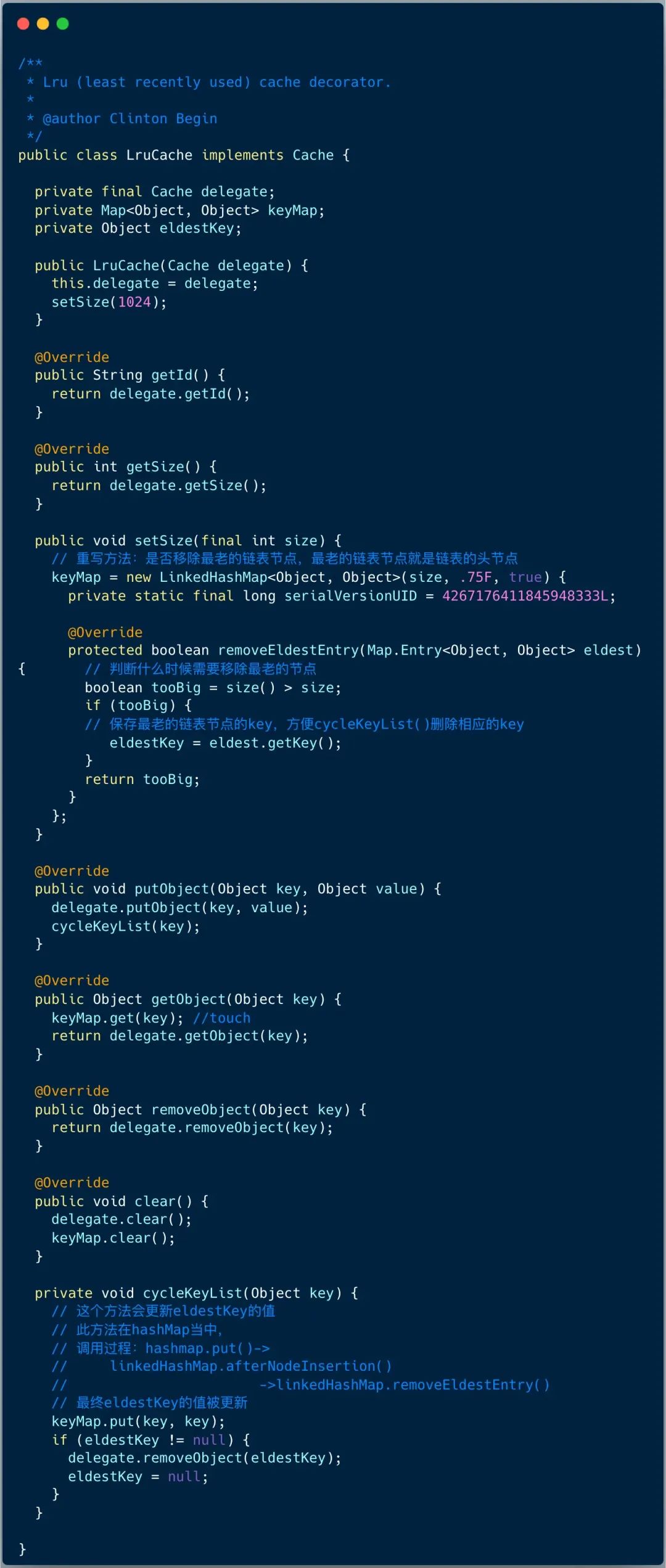
LruCache 使用了装饰器模式 ,使用 LinkedHashMap 默认保存 1024 个缓存 key ,当 key 最久未被访问,并且 keyMap 的大小超过 1024 时 ,记录最老的 key ,当下次添加缓存对象时,删除最老的 key。
使用 LinkedHashMap 重点需要做到使用访问顺序模式和重写 removeEldestEntry 方法。因为 LinkedHashMap 并不是线程安全的,Mybatis 二级缓存责任链中 SynchronizedCache 对象可以实现线程安全的对缓存读写。
3 TreeMap 排序对象缓存
TreeMap 是一种基于红黑树的有序 Map,它可以按照键的顺序进行遍历。
TreeMap 有两种应用场景让笔者印象极为深刻 ,他们分别是一致性哈希算法和 RocketMQ 消费快照 。
下面重点介绍 TreeMap 在一致性哈希算法中的应用。
一致性哈希(Consistent Hashing)算法被广泛应用于缓存系统、分布式数据库、负载均衡器等分布式系统中,以实现高性能和高可用性。它解决了传统哈希算法在动态环境下扩展性和负载均衡性能的问题。
一致性哈希的主要优点是在节点增减时,只有少量的数据需要重新映射,因为只有那些直接或间接与新增或删除节点相邻的数据项需要迁移。这大大减少了系统的迁移开销和影响,使得系统更具扩展性和可伸缩性。
TreeMap 在一致性哈希中可以用作节点/虚拟节点的存储结构,用来维护节点在哈希环上的位置和键的有序性。
1、我们定义一个 TreeMap 存储节点/虚拟节点 。

2、初始化节点
构造函数包含三个部分:物理节点集合、每个物理节点对应的虚拟节点个数、哈希函数 。
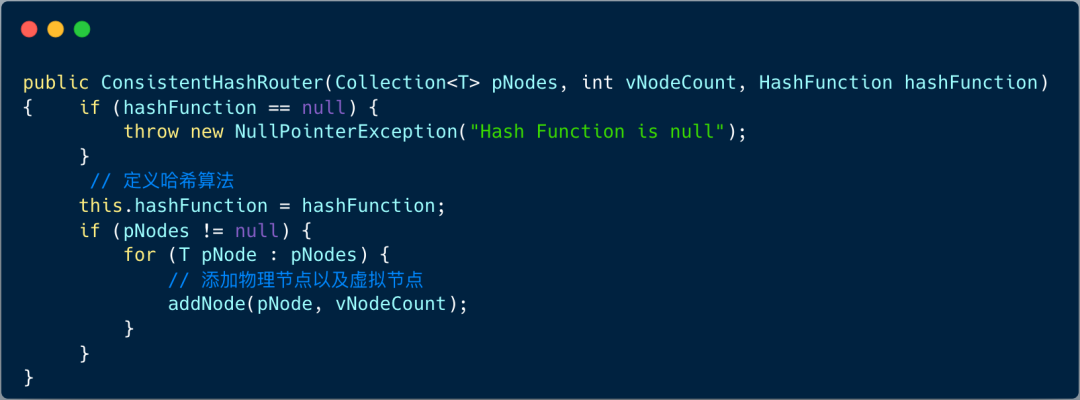
我们重点看下添加节点逻辑:
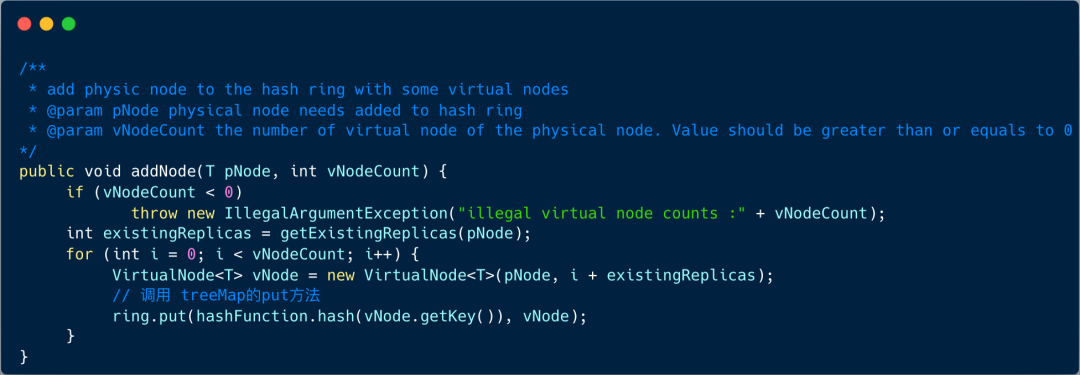
3、按照 key 查询节点
添加完节点之后,节点分布类似下图:
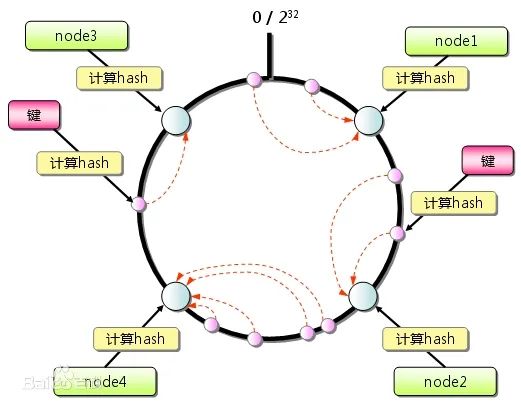
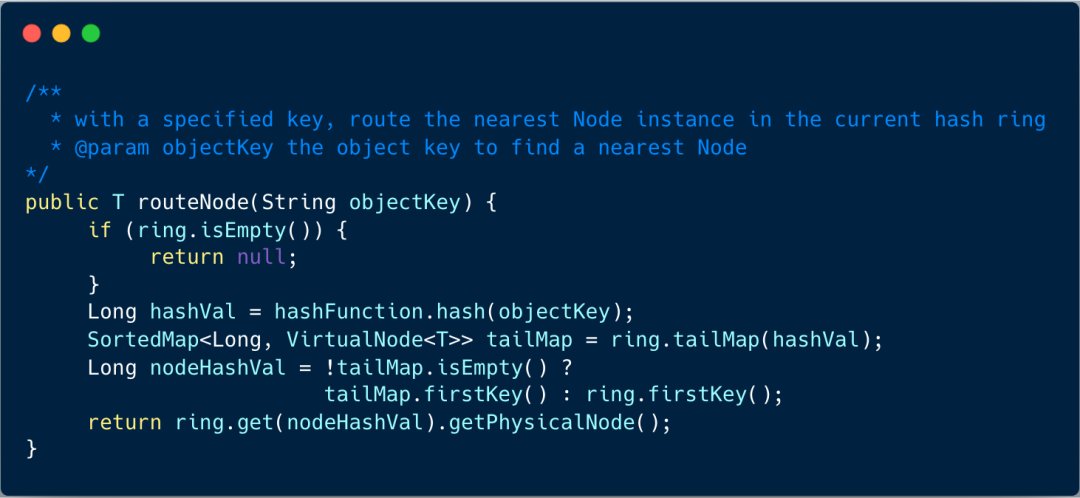
当需要定位某个 key 属于哪个节点时,先通过哈希函数计算 key 的哈希值,并在环上顺时针方向找到第一个大于等于该哈希值的节点位置。该节点即为数据的归属节点 。
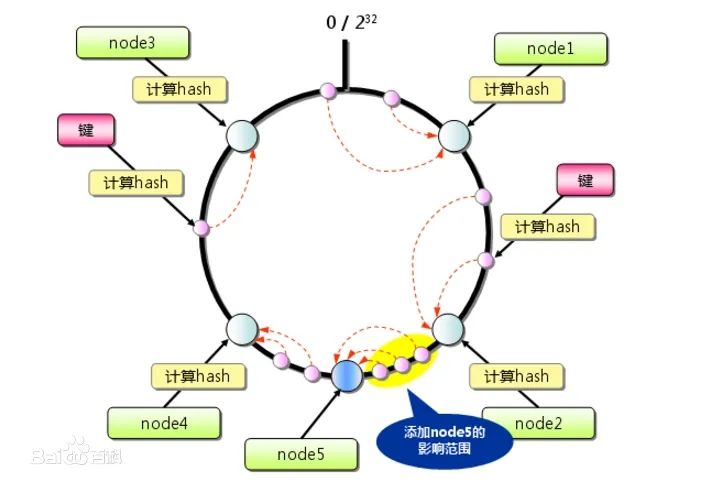
我们添加一个新的节点 node5 , 从下图中,我们可以看到,影响的范围(深黄色)并不大 ,这也就是一致性哈希算法的优势。
4 ByteBuffer 网络编程缓冲池
ByteBuffer 是字节缓冲区,主要用于用户读取和缓存字节数据,多用于网络编程、文件 IO 处理等。
笔者第一次接触 ByteBuffer 是在分库分表中间件 Cobar 中 。在网络编程里,经常需要分配内存,在高并发场景下,性能压力比较大。
Cobar 抽象了一个 NIOProcessor 类用来处理网络请求,每个处理器初始化的时候都会创建一个缓冲池 BufferPool 。BufferPool 用于池化 ByteBuffer ,这和我们平常使用的数据库连接池的思路是一致的。
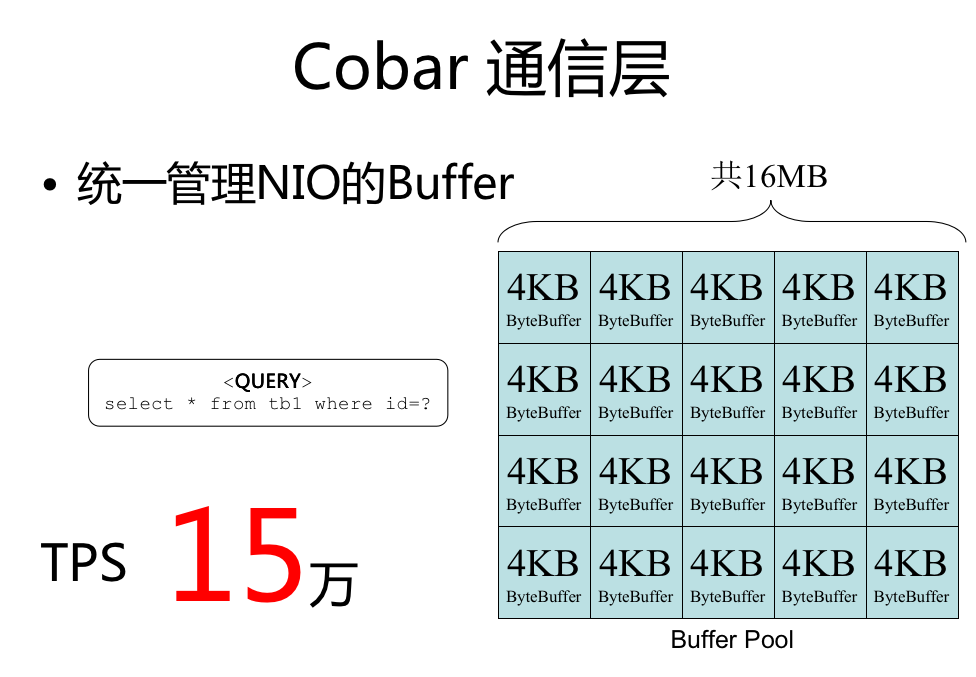
下图展示了缓冲池 BufferPool 的源码:
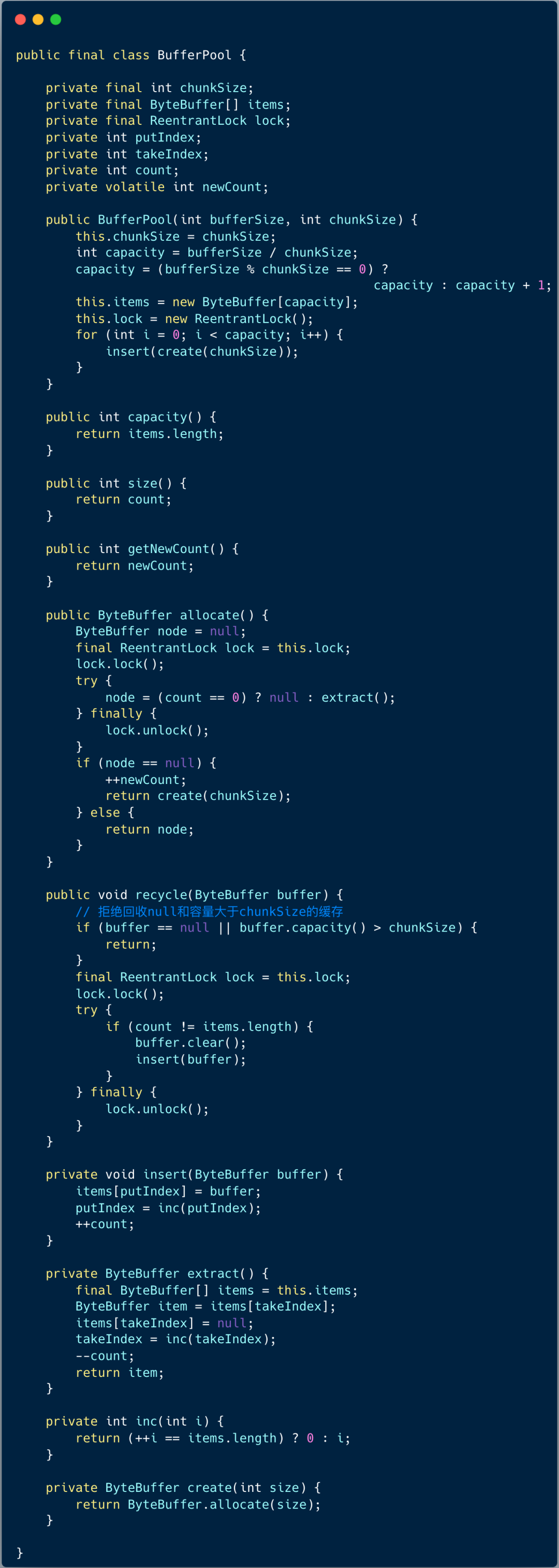
缓冲池 BufferPool 的核心功能是分配缓存和回收缓存 ,通过将缓存池化,可以大大提升系统的性能。
如今 ,Netty 内置了更为强大的内存池化工具 ByteBuf ,我们会在后面的文章里详聊。
5 写到最后
这篇文章,笔者总结了四种强大且低调的缓存。
1、HashMap/ConcurrentHashMap 经常用于配置缓存,对于 HashMap 来讲,HashMap + 读写锁 + 定时任务更新是常用的模式。而 ConcurrentHashMap 广泛存在于各种中间件,线程安全且灵活易用。
2、LinkedHashMap 经常被用于创建最近最少使用缓存 LruCache 。推荐学习 Mybatis 二级缓存的设计,它使用责任链+ 装饰器的设计模式,内置 LruCache 的实现就是使用 LinkedHashMap 。
3、TreeMap 是一种基于红黑树的有序 Map 。TreeMap 在一致性哈希中可以用作节点/虚拟节点的存储结构,用来维护节点在哈希环上的位置和键的有序性。
4、ByteBuffer 是字节缓冲区,主要用于用户读取和缓存字节数据,多用于网络编程、文件 IO 处理等。分库分表中间件 Cobar 在网络请求处理中,创建了缓冲池 BufferPool 用于池化 ByteBuffer ,从而大大提升系统的性能。
往
期
推
荐
3、MySQL到底是 join 性能好,还是in一下更快呢?
5、相比高人气的Rust、Go,为何 Java、C 在工具层面进展缓慢?

点分享

点收藏

点点赞

点在看
