
八股必备|Kafka幂等性原理深入解析

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
幂等性
在正常情况下,Producer向Broker投递消息,Broker将消息追加写到对应的流(即某一Topic的某一Partition)中,并向Producer返回ACK信号,表示确认收到。
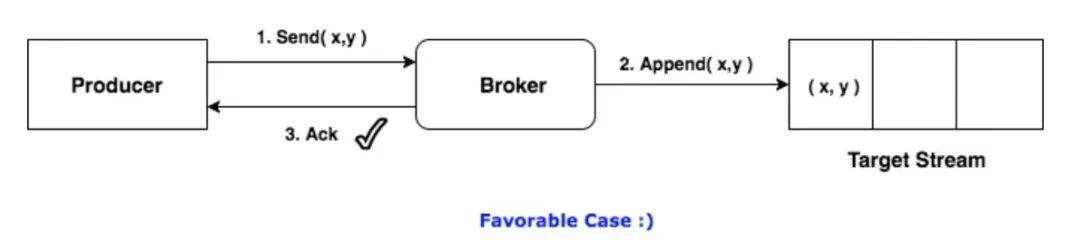
但是Producer和Broker之间的通信总有可能出现异常,如果消息已经写入,但ACK在半途丢失了,Producer就会再次发送该消息,造成重复。
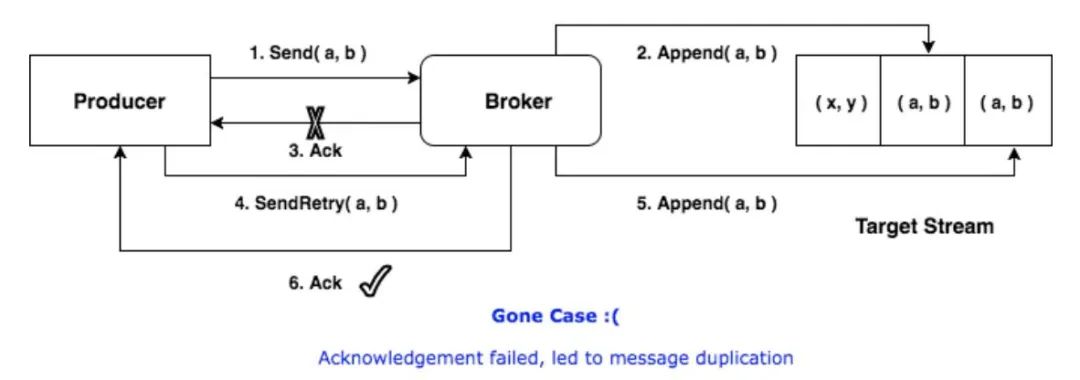
在0.11版本之前,这个问题是无法靠Kafka本身解决的,所以只能得到at least once语义,下游要保证精确的话还得加上去重操作。而在0.11版本引入幂等性之后,只需要将Producer的enable.idempotence配置项设为true,就能保证消息就算重发也仅写入一次了。
究其原因,Kafka加入了以下两个标记值:
PID,在Producer初始化时分配,作为每个Producer会话的唯一标识;
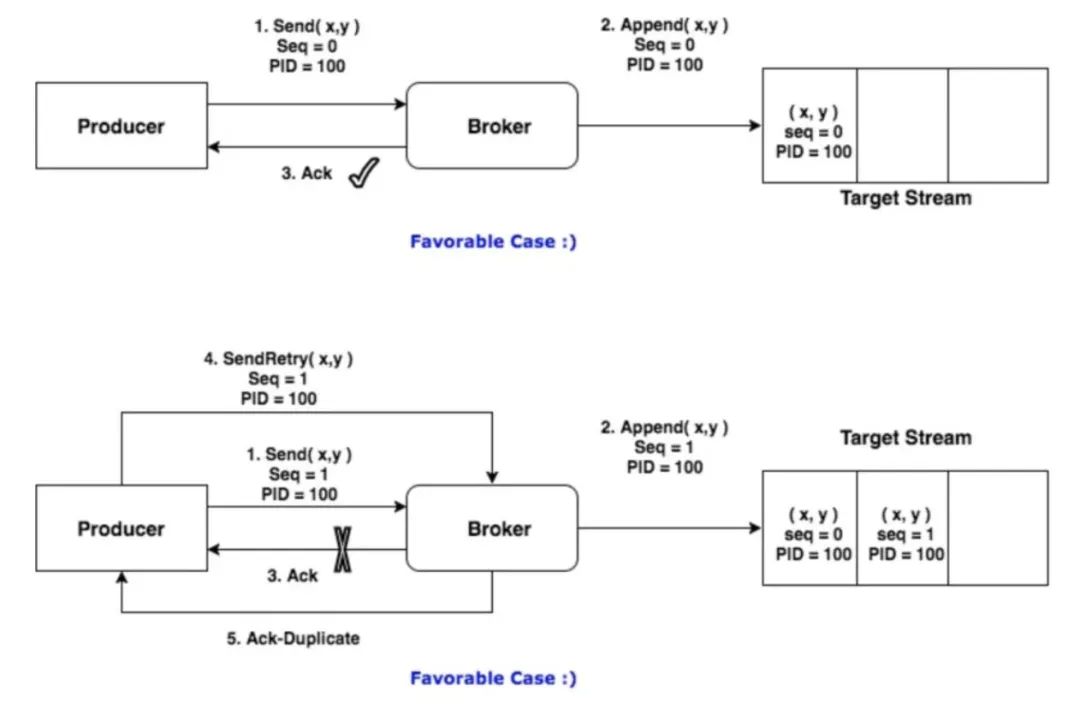
序列号(sequence number),Producer发送的每条消息(更准确地说是每一个消息批次,即ProducerBatch)都会带有此序列号,从0开始单调递增。Broker根据它来判断写入的消息是否可接受。
Broker会为每个TopicPartition组合维护PID和序列号。对每条接收到的消息,都会检查它的序列号是否比Broker所维护的值严格+1,只有这样才是合法的,其他情况都会丢弃。
如下图所示,加上PID和sequence number之后,Broker就会检测到有两条PID = 100且seq = 1的消息写入了Partition,并忽略掉重发的那一条,成功避免了重复。
Kafka的幂等性实现了对于单个Producer会话、单个TopicPartition级别的不重不漏,也就是最细粒度的保证。如果Producer重启(PID发生变化),或者写入是跨Topic、跨Partition的,单纯的幂等性就会失效,需要更高级别的事务性来解决了。当然事务性的原理更加复杂(需要专门的协调组件TransactionCoordinator做协调),下面不考虑事务性,看看幂等性在代码级别多了哪些实现。
Producer端的处理逻辑
首先列举出涉及到的各个组件。
KafkaProducer:即Producer实例;
Sender:KafkaProducer内置的发送消息到Broker的线程;
RecordAccumulator:消息批次ProducerBatch的累加器(缓存),当它满了就会唤醒Sender线程发送消息;
TransactionManager:如果启用了幂等性和/或事务性,Producer内的该组件就会记录PID、各个TopicPartition的序列号和事务状态等信息。
讲解Kafka消息生产全流程的文章数不胜数,本文就不再全部讲一遍,只是重点看看Producer一端和幂等性强相关的那些逻辑。
当客户端调用KafkaProducer.send()方法时,消息实际上是以批次形式(即ProducerBatch)存入了RecordAccumulator中,并且这些ProducerBatch都还没有PID和序列号标记。在Sender线程的run()方法中,会调用maybeWaitForProducerId()方法来为没有PID的Producer产生一个PID,其代码如下。
private void maybeWaitForProducerId() {
while (!transactionManager.hasProducerId() && !transactionManager.hasError()) {
try {
Node node = awaitLeastLoadedNodeReady(requestTimeout);
if (node != null) {
ClientResponse response = sendAndAwaitInitProducerIdRequest(node);
InitProducerIdResponse initProducerIdResponse = (InitProducerIdResponse) response.responseBody();
Errors error = initProducerIdResponse.error();
if (error == Errors.NONE) {
ProducerIdAndEpoch producerIdAndEpoch = new ProducerIdAndEpoch(
initProducerIdResponse.producerId(), initProducerIdResponse.epoch());
transactionManager.setProducerIdAndEpoch(producerIdAndEpoch);
return;
} else if (error.exception() instanceof RetriableException) {
log.debug("Retriable error from InitProducerId response", error.message());
} else {
transactionManager.transitionToFatalError(error.exception());
break;
}
} else {
log.debug("Could not find an available broker to send InitProducerIdRequest to. " +
"We will back off and try again.");
}
} catch (UnsupportedVersionException e) {
transactionManager.transitionToFatalError(e);
break;
} catch (IOException e) {
log.debug("Broker {} disconnected while awaiting InitProducerId response", e);
}
log.trace("Retry InitProducerIdRequest in {}ms.", retryBackoffMs);
time.sleep(retryBackoffMs);
metadata.requestUpdate();
}
}
其流程是:调用awaitLeastLoadedNodeReady()方法获取到当前连接数最少的Broker节点,并调用sendAndAwaitInitProducerIdRequest()方法向该节点发送一个InitProducerIdRequest请求。如果响应正常,会返回两个值,一是PID,二是Producer的纪元值(epoch)。后者用于在事务性开启时判断当前Producer是否过期,与幂等性无关。最后调用TransactionManager.setProducerIdAndEpoch()方法,将PID和纪元值保存在TransactionManager实例中。如果未分配成功,会隔一段时间继续重试。
PID的产生由专门的ProducerIdManager组件来管理,并且是与ZooKeeper交互的。原理比较简单,源码就不贴了。
接下来,Sender.run()还会调用sendProducerData()方法正式取出RecordAccumulator中缓存的消息,最终包装成ProduceRequest,即生产消息的请求,并向Broker发送出去。以下是sendProducerData()调用的RecordAccumulator.drain()方法的代码,其中有不少与幂等性相关的逻辑。
public Map> drain(Cluster cluster,
Set
nodes,
int maxSize,
long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
Map 在生产一个批次之前,drain()方法执行了很多重判断:
该批次没有在等待重试的间隔中;
该批次允许被发送到对应的TopicPartition;
PID和纪元值有效;
该批次的前面没有未发送成功的批次。TransactionManager.hasUnresolvedSequence()用于判断之前的序列号对应的消息状态是否已确定(即有没有乱序风险);
该TopicPartition没有数据在发送。如果有批次是in-flight的,并且它的序列号与本批次的不同,说明本批次是重试的,需要等待in-flight的数据发送完成。
如果通过了上面的判断,才会继续执行下去。若当前批次没有序列号,表示它是第一次发送。此时就会将PID、纪元值、序列号写入该ProducerBatch,并调用TransactionManager.incrementSequenceNumber()增加维护的序列号的值,最后将其标记为in-flight,即待发送。
Broker端的处理逻辑
简述一下Broker端涉及到的数据结构。
BatchMetadata:存储批次的元数据,包括该批次中最后一条消息的序列号、offset,以及消息的偏移量(条数)等信息。
ProducerIdEntry:以队列的形式维护单个PID对应的最新BatchMetadata,序列号小的在前,大的在后,并且容量固定为5。
ProducerStateManager:管理所有TopicPartition的ProducerIdEntry。
Producer端的ProduceRequest请求发出后,由Broker通过KafkaApis.handleProduceRequest()方法处理,最终落盘时,会来到Log.append()方法。来看看它是怎么校验PID和序列号的。
private def analyzeAndValidateProducerState(records: MemoryRecords, isFromClient: Boolean):
(mutable.Map[Long, ProducerAppendInfo], List[CompletedTxn], Option[BatchMetadata]) = {
val updatedProducers = mutable.Map.empty[Long, ProducerAppendInfo]
val completedTxns = ListBuffer.empty[CompletedTxn]
for (batch <- records.batches.asScala if batch.hasProducerId) {
val maybeLastEntry = producerStateManager.lastEntry(batch.producerId)
if (isFromClient)
maybeLastEntry.flatMap(_.duplicateOf(batch)).foreach { duplicate =>
return (updatedProducers, completedTxns.toList, Some(duplicate))
}
val maybeCompletedTxn = updateProducers(batch, updatedProducers, isFromClient = isFromClient)
maybeCompletedTxn.foreach(completedTxns += _)
}
(updatedProducers, completedTxns.toList, None)
}
可见,如果这个批次有PID,就会从ProducerStateManager维护的对应BatchMetadata中寻找是否有重复的(亦即该批次是否为重复发送)。对应的实现如下。
def duplicateOf(batch: RecordBatch): Option[BatchMetadata] = {
if (batch.producerEpoch() != producerEpoch)
None
else
batchWithSequenceRange(batch.baseSequence(), batch.lastSequence())
}
def batchWithSequenceRange(firstSeq: Int, lastSeq: Int): Option[BatchMetadata] = {
val duplicate = batchMetadata.filter { case(metadata) =>
firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq
}
duplicate.headOption
}
如果此批次的第一条消息的序列号和最后一条消息的序列号和缓存中的完全相同,表示它是重复发送。当该批次不是重发时,才会继续调用updateProducers()方法更新BatchMetadata信息。
校验序列号的逻辑则位于ProducerAppendInfo.checkSequence()方法。
private def checkSequence(producerEpoch: Short, firstSeq: Int, lastSeq: Int): Unit = {
if (producerEpoch != currentEntry.producerEpoch) {
if (firstSeq != 0) {
if (currentEntry.producerEpoch != RecordBatch.NO_PRODUCER_EPOCH) {
throw new OutOfOrderSequenceException(s"Invalid sequence number for new epoch: $producerEpoch " +
s"(request epoch), $firstSeq (seq. number)")
} else {
throw new UnknownProducerIdException(s"Found no record of producerId=$producerId on the broker. It is possible " +
s"that the last message with the producerId=$producerId has been removed due to hitting the retention limit.")
}
}
} else if (currentEntry.lastSeq == RecordBatch.NO_SEQUENCE && firstSeq != 0) {
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: found $firstSeq " +
s"(incoming seq. number), but expected 0")
} else if (isDuplicate(firstSeq, lastSeq)) {
throw new DuplicateSequenceException(s"Duplicate sequence number for producerId $producerId: (incomingBatch.firstSeq, " +
s"incomingBatch.lastSeq): ($firstSeq, $lastSeq).")
} else if (!inSequence(firstSeq, lastSeq)) {
throw new OutOfOrderSequenceException(s"Out of order sequence number for producerId $producerId: $firstSeq " +
s"(incoming seq. number), ${currentEntry.lastSeq} (current end sequence number)")
}
}
private def isDuplicate(firstSeq: Int, lastSeq: Int): Boolean = {
((lastSeq != 0 && currentEntry.firstSeq != Int.MaxValue && lastSeq < currentEntry.firstSeq)
|| currentEntry.batchWithSequenceRange(firstSeq, lastSeq).isDefined)
}
private def inSequence(firstSeq: Int, lastSeq: Int): Boolean = {
firstSeq == currentEntry.lastSeq + 1L || (firstSeq == 0 && currentEntry.lastSeq == Int.MaxValue)
}
可见,如果Producer的纪元值发生过变化,那么写入的批次序列号一定要是0(因为Producer不再是原来的那个了)。当维护的最近一条序列号为-1时,表示此PID对应的Producer还未生产过消息,写入的批次序列号也必须是0。最后一个合法条件就是序列号是严格+1,当其达到整形最大值时,就回滚到0重新开始计。
特别注意,由于ProducerIdEntry只能固定缓存5个BatchMetadata,所以在开启幂等性时,Producer的max.in.flight.requests.per.connection参数不能设为大于5的值。显然,若设为大于5的话,有可能会造成某一批次的元数据被挤出缓存,如果该批次又发生重试,就会因为永远找不到其对应的BatchMetadata而达到最大重试次数,效率大大降低。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)