
手把手教你用Python玩转时序数据,从采样、预测到聚类

本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处 本文约1800字,建议阅读5分钟
如果你有朝一日碰到了时序数据,该怎么用Python搞定它呢?
时序数据采样
数据集
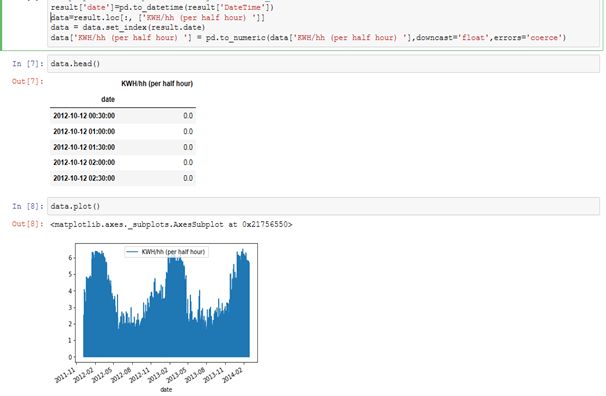
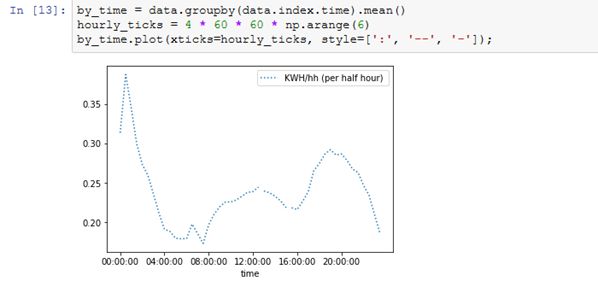
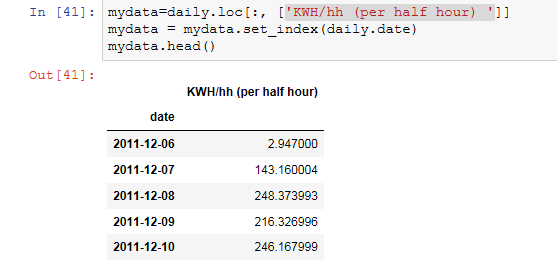
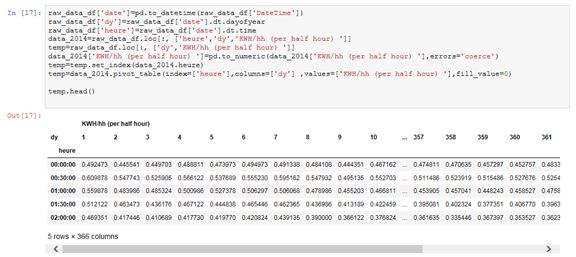
重采样
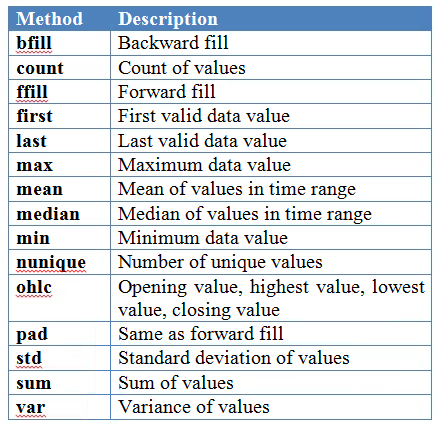
data.resample() 用来重采样数据帧里的电量(kWh)那一列。
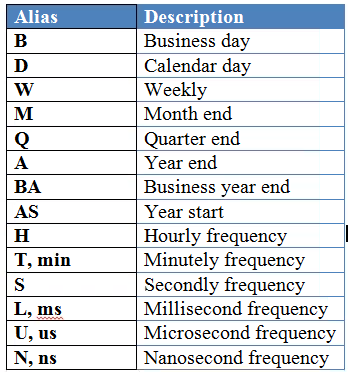
The ‘W’ 表示我们要把采样周期变为每周(week)。
sum()用来求得这段时间里的电量之和。
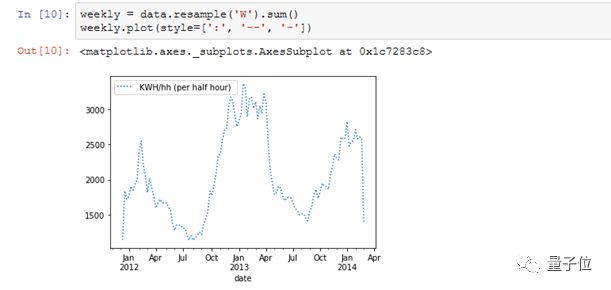
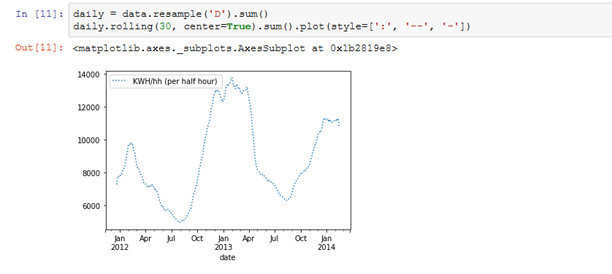
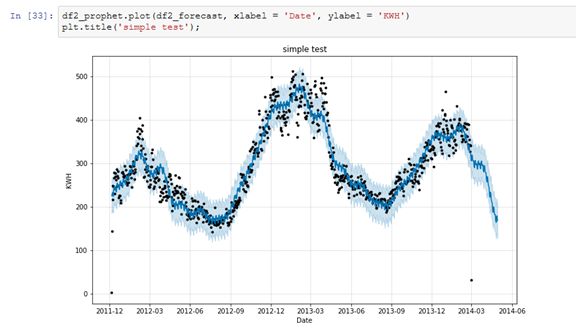
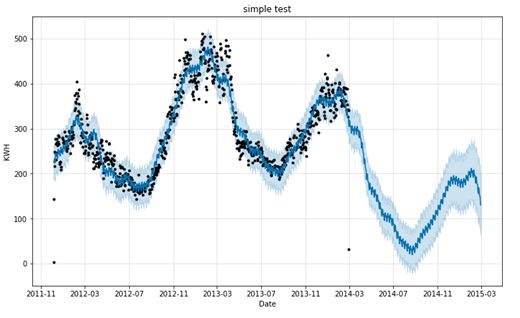
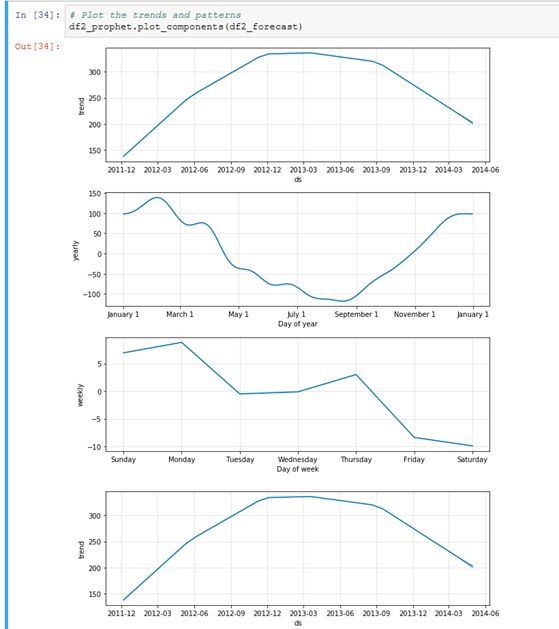
用Prophet建模




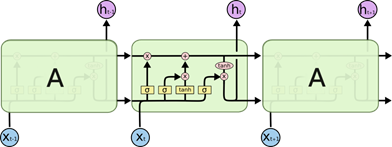
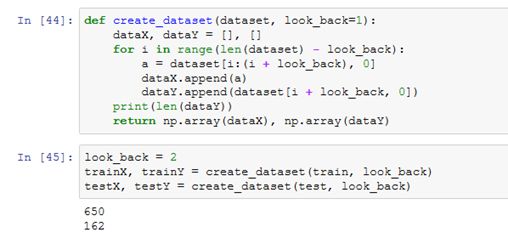
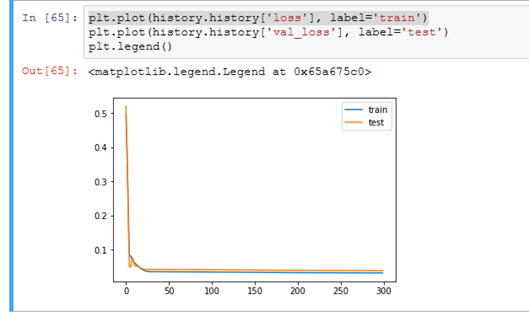
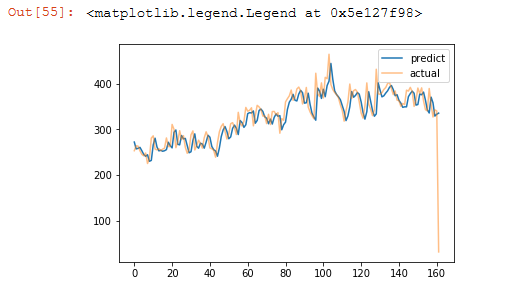
LSTM预测




聚类
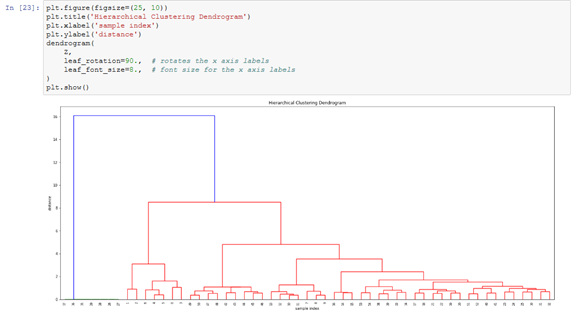
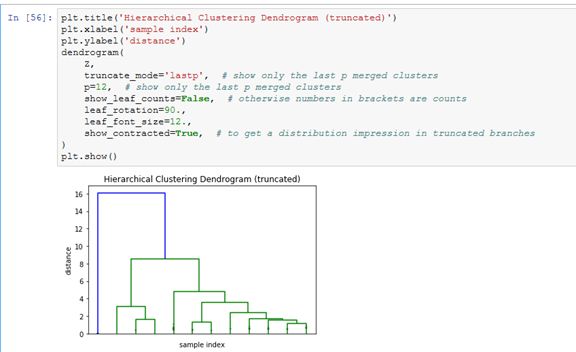
连接和树形图

传送门
https://towardsdatascience.com/playing-with-time-series-data-in-python-959e2485bff8
编辑:王菁
校对:林亦霖
评论