
Python 爬虫:单线程、多线程和协程的爬虫性能对比
↑ 关注 + 星标 ,每天学Python新技能
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
后台回复【大礼包】送你Python自学大礼包
单线程、多线程和协程的爬虫性能对比
大家好,我是安果!
今天我要给大家分享的是如何爬取豆瓣上深圳近期即将上映的电影影讯,并分别用普通的单线程、多线程和协程来爬取,从而对比单线程、多线程和协程在网络爬虫中的性能。
具体要爬的网址是:https://movie.douban.com/cinema/later/shenzhen/
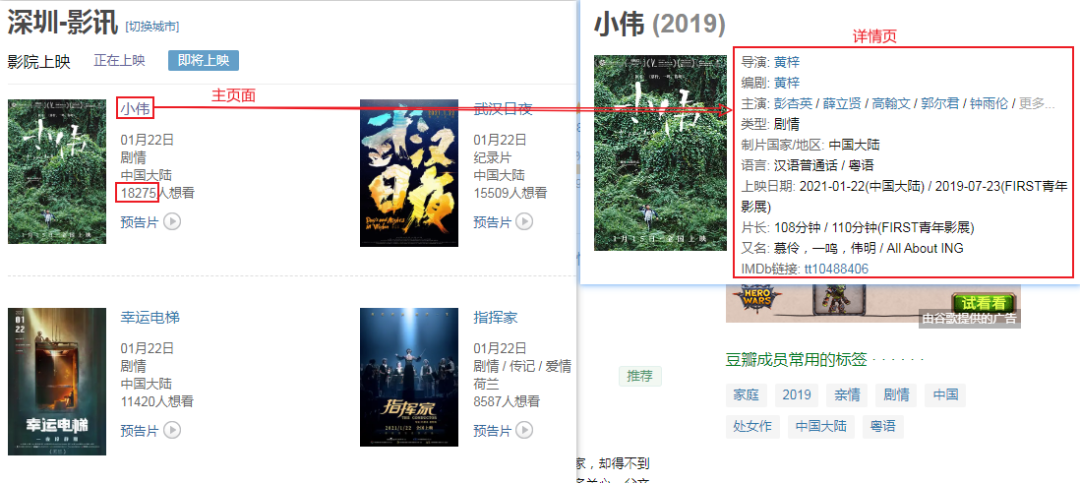
除了要爬入口页以外还需爬取每个电影的详情页,具体要爬取的结构信息如下:
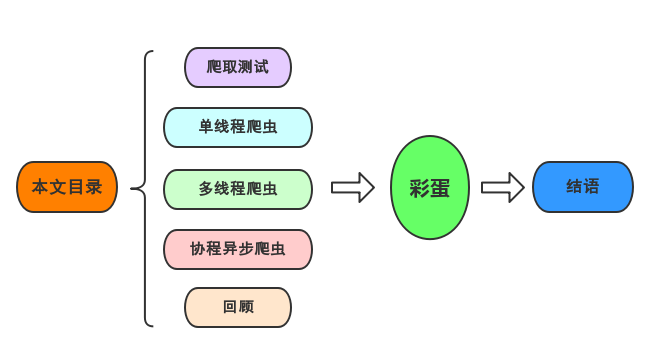
爬取测试
下面我演示使用xpath解析数据。
入口页数据读取:
import requests
from lxml import etree
import pandas as pd
import re
main_url = "https://movie.douban.com/cinema/later/shenzhen/"
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(main_url, headers=headers)
r
结果:
<Response [200]>
检查一下所需数据的xpath:
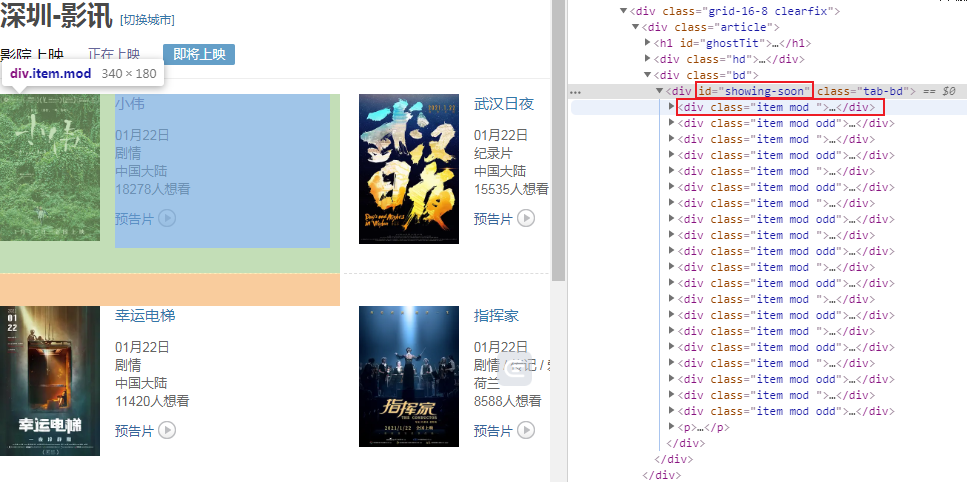
可以看到每个电影信息都位于id为showing-soon下面的div里面,再分别分析内部的电影名称、url和想看人数所处的位置,于是可以写出如下代码:
html = etree.HTML(r.text)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
main_df
结果:

然后再选择一个详情页的url进行测试,我选择了熊出没·狂野大陆这部电影,因为文本数据相对最复杂,也最具备代表性:
url = main_df.at[17, "url"]
url
结果:
'https://movie.douban.com/subject/34825886/'
分析详情页结构:
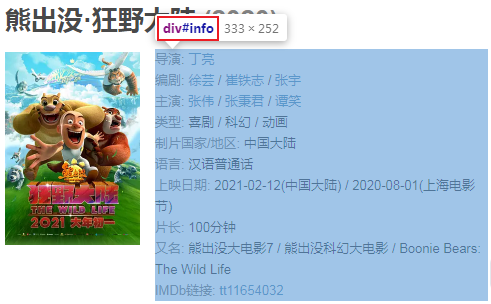
文本信息都在这个位置中,下面我们直接提取这个div下面的所有文本节点:
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
movie_infos = html.xpath("//div[@id='info']//text()")
print(movie_infos)
结果:
['\n ', '导演', ': ', '丁亮', '\n ', '编剧', ': ', '徐芸', ' / ', '崔铁志', ' / ', '张宇', '\n ', '主演', ': ', '张伟', ' / ', '张秉君', ' / ', '谭笑', '\n ', '类型:', ' ', '喜剧', ' / ', '科幻', ' / ', '动画', '\n \n ', '制片国家/地区:', ' 中国大陆', '\n ', '语言:', ' 汉语普通话', '\n ', '上映日期:', ' ', '2021-02-12(中国大陆)', ' / ', '2020-08-01(上海电影节)', '\n ', '片长:', ' ', '100分钟', '\n ', '又名:', ' 熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life', '\n ', 'IMDb链接:', ' ', 'tt11654032', '\n\n']
为了阅读方便,拼接一下:
movie_info_txt = "".join(movie_infos)
print(movie_info_txt)
结果:
导演: 丁亮
编剧: 徐芸 / 崔铁志 / 张宇
主演: 张伟 / 张秉君 / 谭笑
类型: 喜剧 / 科幻 / 动画
制片国家/地区: 中国大陆
语言: 汉语普通话
上映日期: 2021-02-12(中国大陆) / 2020-08-01(上海电影节)
片长: 100分钟
又名: 熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life
IMDb链接: tt11654032
接下来就简单了:
row = {}
for line in re.split("[\n ]*\n[\n ]*", movie_info_txt):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row
结果:
{'导演': '丁亮',
'编剧': '徐芸 / 崔铁志 / 张宇',
'主演': '张伟 / 张秉君 / 谭笑',
'类型': '喜剧 / 科幻 / 动画',
'制片国家/地区': '中国大陆',
'语言': '汉语普通话',
'上映日期': '2021-02-12(中国大陆) / 2020-08-01(上海电影节)',
'片长': '100分钟',
'又名': '熊出没大电影7 / 熊出没科幻大电影 / Boonie Bears: The Wild Life',
'IMDb链接': 'tt11654032'}
可以看到成功的切割出了每一项。
下面根据上面的测试基础,我们完善整体的爬虫代码:
单线程爬虫
import requests
from lxml import etree
import pandas as pd
import re
main_url = "https://movie.douban.com/cinema/later/shenzhen/"
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(main_url, headers=headers)
html = etree.HTML(r.text)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
print(url)
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
r = requests.get(url, headers=headers)
html = etree.HTML(r.text)
row = {}
row["电影名称"] = name
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["想看人数"] = int(like_num[:like_num.find("人")])
# row["url"] = url
# row["图片地址"] = imgurl
# print(row)
result.append(row)
df = pd.DataFrame(result)
df.sort_values("想看人数", ascending=False, inplace=True)
df.to_csv("shenzhen_movie.csv", index=False)
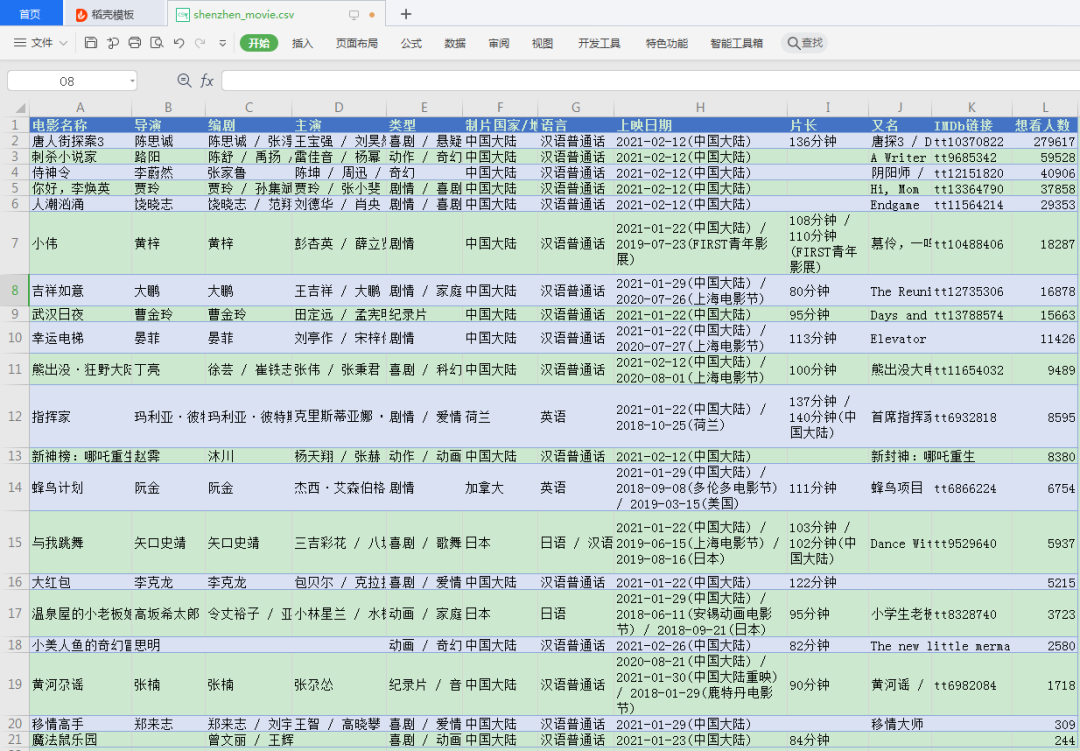
结果:
https://movie.douban.com/subject/26752564/
https://movie.douban.com/subject/35172699/
https://movie.douban.com/subject/34992142/
https://movie.douban.com/subject/30349667/
https://movie.douban.com/subject/30283209/
https://movie.douban.com/subject/33457717/
https://movie.douban.com/subject/30487738/
https://movie.douban.com/subject/35068230/
https://movie.douban.com/subject/27039358/
https://movie.douban.com/subject/30205667/
https://movie.douban.com/subject/30476403/
https://movie.douban.com/subject/30154423/
https://movie.douban.com/subject/27619748/
https://movie.douban.com/subject/26826330/
https://movie.douban.com/subject/26935283/
https://movie.douban.com/subject/34841067/
https://movie.douban.com/subject/34880302/
https://movie.douban.com/subject/34825886/
https://movie.douban.com/subject/34779692/
https://movie.douban.com/subject/35154209/
爬到的文件:
整体耗时:
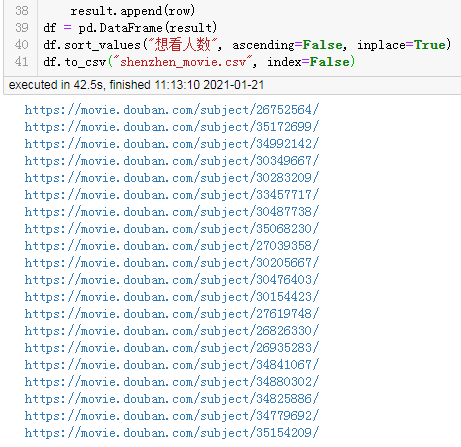
42.5 秒
多线程爬虫
单线程的爬取耗时还是挺长的,下面看看使用多线程的爬取效率:
import requests
from lxml import etree
import pandas as pd
import re
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
def fetch_content(url):
print(url)
headers = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get(url, headers=headers)
return r.text
url = "https://movie.douban.com/cinema/later/shenzhen/"
init_page = fetch_content(url)
html = etree.HTML(init_page)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
max_workers = main_df.shape[0]
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_tasks = [executor.submit(fetch_content, url) for url in main_df.url]
wait(future_tasks, return_when=ALL_COMPLETED)
pages = [future.result() for future in future_tasks]
result = []
for url, html_text in zip(main_df.url, pages):
html = etree.HTML(html_text)
row = {}
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["url"] = url
result.append(row)
detail_df = pd.DataFrame(result)
df = main_df.merge(detail_df, on="url")
df.drop(columns=["url"], inplace=True)
df.sort_values("想看人数", ascending=False, inplace=True)
df.to_csv("shenzhen_movie2.csv", index=False)
df
结果:
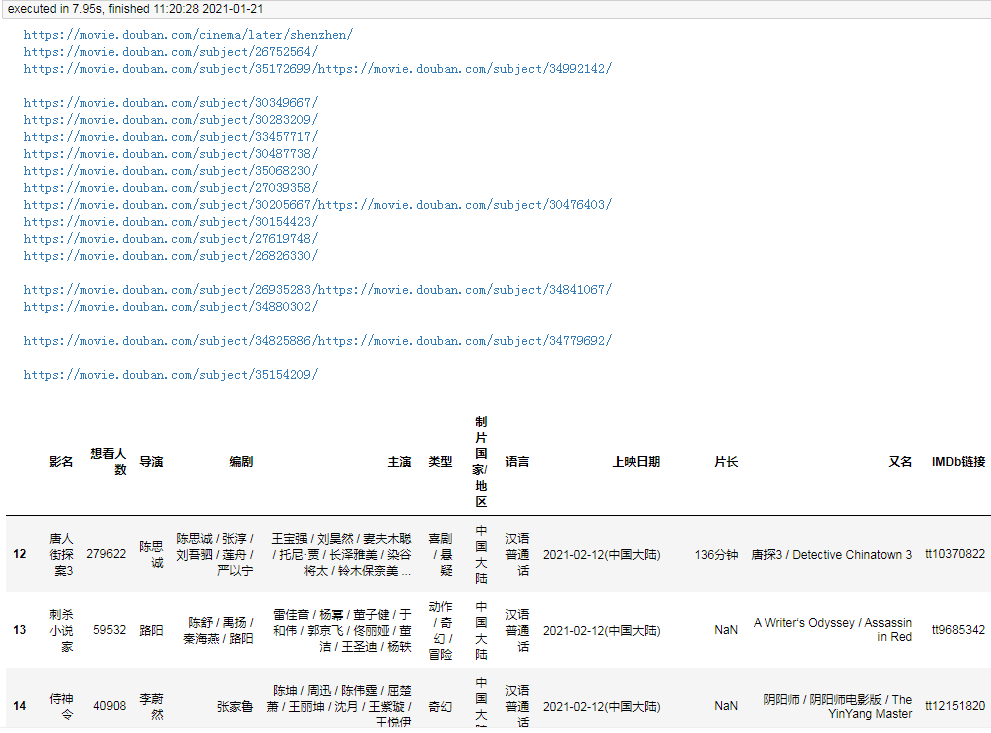
耗时 8 秒
由于每个子页面都是单独的线程爬取,每个线程几乎都是同时在工作,所以最终耗时仅取决于爬取最慢的子页面
协程异步爬虫
由于我在jupyter中运行,为了使协程能够直接在jupyter中直接运行,所以我在代码中增加了下面两行代码,在普通编辑器里面可以去掉:
import nest_asyncio
nest_asyncio.apply()
这个问题是因为jupyter所依赖的高版本Tornado存在bug,将Tornado退回到低版本也可以解决这个问题。
下面我使用协程来完成这个需求的爬取:
import aiohttp
from lxml import etree
import pandas as pd
import re
import asyncio
import nest_asyncio
nest_asyncio.apply()
async def fetch_content(url):
print(url)
header = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
async with aiohttp.ClientSession(
headers=header, connector=aiohttp.TCPConnector(ssl=False)
) as session:
async with session.get(url) as response:
return await response.text()
async def main():
url = "https://movie.douban.com/cinema/later/shenzhen/"
init_page = await fetch_content(url)
html = etree.HTML(init_page)
all_movies = html.xpath("//div[@id='showing-soon']/div")
result = []
for e in all_movies:
# imgurl, = e.xpath(".//img/@src")
name, = e.xpath(".//div[@class='intro']/h3/a/text()")
url, = e.xpath(".//div[@class='intro']/h3/a/@href")
# date, movie_type, pos = e.xpath(".//div[@class='intro']/ul/li[@class='dt']/text()")
like_num, = e.xpath(
".//div[@class='intro']/ul/li[@class='dt last']/span/text()")
result.append((name, int(like_num[:like_num.find("人")]), url))
main_df = pd.DataFrame(result, columns=["影名", "想看人数", "url"])
tasks = [fetch_content(url) for url in main_df.url]
pages = await asyncio.gather(*tasks)
result = []
for url, html_text in zip(main_df.url, pages):
html = etree.HTML(html_text)
row = {}
for line in re.split("[\n ]*\n[\n ]*", "".join(html.xpath("//div[@id='info']//text()")).strip()):
line = line.strip()
arr = line.split(": ", maxsplit=1)
if len(arr) != 2:
continue
k, v = arr
row[k] = v
row["url"] = url
result.append(row)
detail_df = pd.DataFrame(result)
df = main_df.merge(detail_df, on="url")
df.drop(columns=["url"], inplace=True)
df.sort_values("想看人数", ascending=False, inplace=True)
return df
df = asyncio.run(main())
df.to_csv("shenzhen_movie3.csv", index=False)
df
结果:

耗时仅 7 秒,相对比多线程更快一点
由于request库不支持协程,所以我使用了支持协程的aiohttp进行页面抓取
当然实际爬取的耗时还取绝于当时的网络,但整体来说,协程爬取会比多线程爬虫稍微快一些
回顾
今天我向你演示了,单线程爬虫、多线程爬虫和协程爬虫
可以看到,一般情况下协程爬虫速度最快,多线程爬虫略慢一点,单线程爬虫则必须上一个页面爬取完成才能继续爬取。
但协程爬虫相对来说并不是那么好编写,数据抓取无法使用request库,只能使用aiohttp
所以在实际编写爬虫时,我们一般都会使用多线程爬虫来提速,但必须注意的是网站都有ip访问频率限制,爬的过快可能会被封ip,所以一般我们在多线程提速的同时使用代理ip来并发的爬取数据
彩蛋:xpath+pandas解析表格并提取url
我们在深圳影讯的底部能够看到一个[查看全部即将上映的影片] (https://movie.douban.com/coming)的按钮,点进去能够看到一张完整近期上映电影的列表,发现这个列表是个table标签的数据:
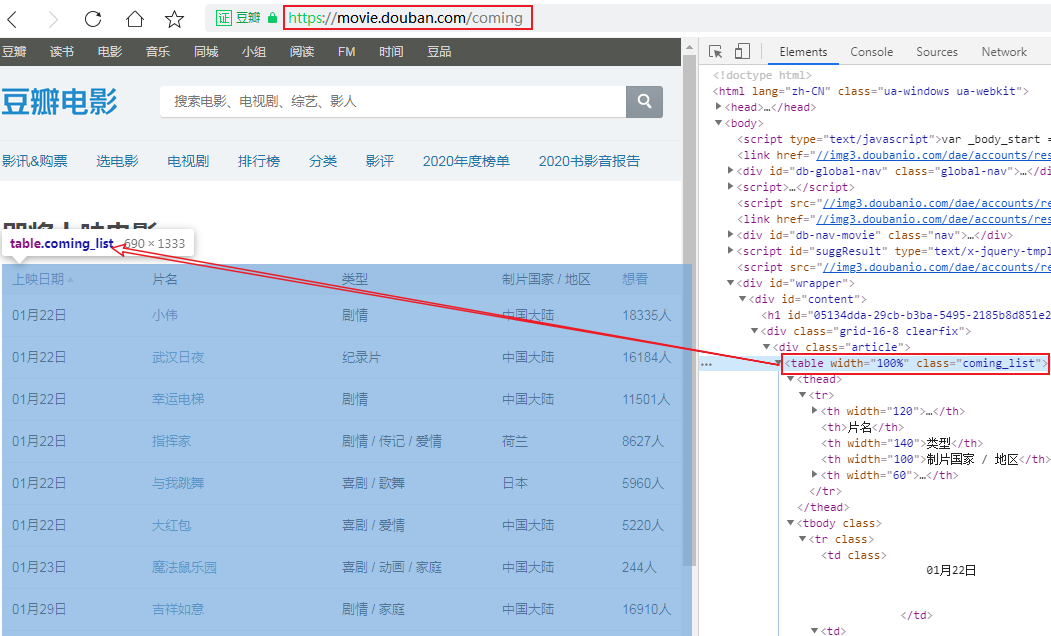
那就简单了,解析table我们可能压根就不需要用xpath,直接用pandas即可,但片名中包含的url地址还需解析,所以我采用xpath+pandas来解析这个网页,看看我的代码吧:
import pandas as pd
import requests
from lxml import etree
headers = {
"Accept-Encoding": "Gzip",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
r = requests.get("https://movie.douban.com/coming", headers=headers)
html = etree.HTML(r.text)
table_tag = html.xpath("//table")[0]
df, = pd.read_html(etree.tostring(table_tag))
urls = table_tag.xpath(".//td[2]/a/@href")
df["url"] = urls
df
结果
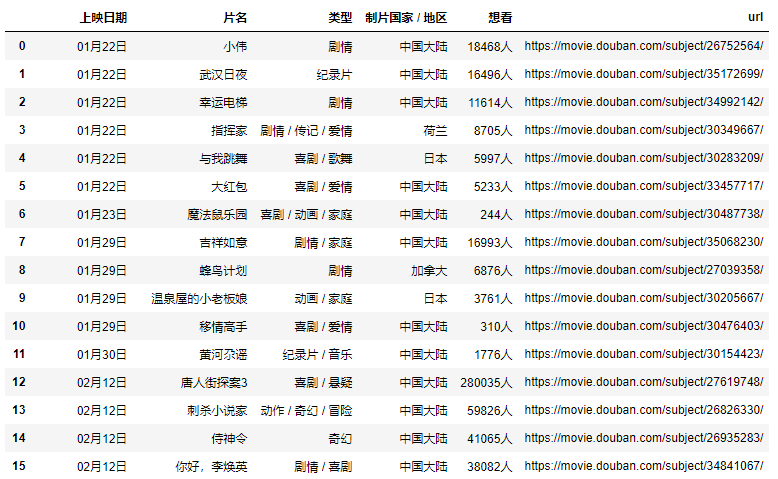 这样就能到了主页面的完整数据,再简单的处理一下即可
这样就能到了主页面的完整数据,再简单的处理一下即可
结语
感谢各位读者,有什么想法和收获欢迎留言评论噢!

送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,
这些资料都是视频,新人学起来非常友好。扫码加微信后备注「Python新手」方便我给你发送资料
推荐阅读
扫码回复「大礼包」后获取大礼