
Python 进程、线程和协程实战指归
1. 前言
使用线程是为了并行还是加速?
为什么我使用多线程之后,处理速度并没有预期的快,甚至更慢了?
我应该选择多进程处理还是多线程处理?
协程和线程有什么不同?
什么情况下使用协程?
计算密集型任务:任务包含大量计算,CPU占用率高
IO密集型任务:任务包含频繁的、持续的网络IO和磁盘IO
混合型任务:既有计算也有IO
2. 线程
2.1 线程的最大意义在于并行
请写一段代码,提示用户从键盘输入任意字符,然后等待用户输入。如果用户在10秒钟完成输入(按回车键),则显示输入内容并结束程序;否则,不再等待用户输入,而是直接提示超时并结束程序。
import os, time
import threading
def monitor(pid):
time.sleep(10)
print('\n超时退出!')
os._exit(0)
m = threading.Thread(target=monitor, args=(os.getpid(), ))
m.setDaemon(True)
m.start()
s = input('请输入>>>')
print('接收到键盘输入:%s'%s)
print('程序正常结束。')
2.2 使用线程处理IO密集型任务
import time
import requests
import threading
urls = ['https://www.baidu.com', 'https://cn.bing.com']
def get_html(n):
for i in range(n):
url = urls[i%2]
resp = requests.get(url)
#print(resp.ok, url)
t0 = time.time()
get_html(100) # 请求100次
t1 = time.time()
print('1个线程请求100次,耗时%0.3f秒钟'%(t1-t0))
for n_thread in (2,5,10,20,50):
t0 = time.time()
ths = list()
for i in range(n_thread):
ths.append(threading.Thread(target=get_html, args=(100//n_thread,)))
ths[-1].setDaemon(True)
ths[-1].start()
for i in range(n_thread):
ths[i].join()
t1 = time.time()
print('%d个线程请求100次,耗时%0.3f秒钟'%(n_thread, t1-t0))
1个线程请求100次,耗时30.089秒钟
2个线程请求100次,耗时15.087秒钟
5个线程请求100次,耗时7.803秒钟
10个线程请求100次,耗时4.112秒钟
20个线程请求100次,耗时3.160秒钟
50个线程请求100次,耗时3.564秒钟
2.3 使用线程处理计算密集型任务

低端增强算法(也有人叫做伽马矫正)其实很简单:对于[0,255]区间内的灰度值v0,指定矫正系数y,使用下面的公式,即可达到矫正后的灰度值v1,其中y一般选择2或者3,上图右就是y为3的效果。
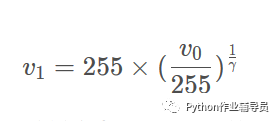
import time
import cv2
import numpy as np
import threading
def gamma_adjust_np(im, gamma, out_file):
"""伽马增强函数:使用广播和矢量化计算"""
out = (np.power(im.astype(np.float32)/255, 1/gamma)*255).astype(np.uint8)
cv2.imwrite(out_file, out)
def gamma_adjust_py(im, gamma, out_file):
"""伽马增强函数:使用循环逐像素计算"""
rows, cols = im.shape
out = im.astype(np.float32)
for i in range(rows):
for j in range(cols):
out[i,j] = pow(out[i,j]/255, 1/3)*255
cv2.imwrite(out_file, out.astype(np.uint8))
im = cv2.imread('river.jpg', cv2.IMREAD_GRAYSCALE)
rows, cols = im.shape
print('照片分辨率为%dx%d'%(cols, rows))
t0 = time.time()
gamma_adjust_np(im, 3, 'river_3.jpg')
t1 = time.time()
print('借助NumPy广播特性,耗时%0.3f秒钟'%(t1-t0))
t0 = time.time()
im_3 = gamma_adjust_py(im, 3, 'river_3_cycle.jpg')
t1 = time.time()
print('单线程逐像素处理,耗时%0.3f秒钟'%(t1-t0))
t0 = time.time()
th_1 = threading.Thread(target=gamma_adjust_py, args=(im[:rows//2], 3, 'river_3_1.jpg'))
th_1.setDaemon(True)
th_1.start()
th_2 = threading.Thread(target=gamma_adjust_py, args=(im[rows//2:], 3, 'river_3_2.jpg'))
th_2.setDaemon(True)
th_2.start()
th_1.join()
th_2.join()
t1 = time.time()
print('启用两个线程逐像素处理,耗时%0.3f秒钟'%(t1-t0))
运行结果如下:
照片分辨率为4088x2752
借助NumPy广播特性,耗时0.381秒钟
单线程逐像素处理,耗时34.228秒钟
启用两个线程逐像素处理,耗时36.087秒钟
2.4 线程池
>>> from concurrent.futures import ThreadPoolExecutor
>>> def pow2(x):
return x*x
>>> with ThreadPoolExecutor(max_workers=4) as pool: # 4个线程的线程池
result = pool.map(pow2, range(10)) # 使用4个线程分别计算0~9的平方
>>> list(result) # result是一个生成器,转成列表才可以直观地看到计算结果
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> from concurrent.futures import ThreadPoolExecutor
>>> def pow2(x):
return x*x
>>> def pow3(x):
return x*x*x
>>> def save_result(task): # 保存线程计算结果
global result
result.append(task.result())
>>> result = list()
>>> with ThreadPoolExecutor(max_workers=3) as pool:
for i in range(10):
if i%2: # 奇数做平方运算
task = pool.submit(pow2, i)
else: # 偶数做立方运算
task = pool.submit(pow3, i)
task.add_done_callback(save_result) # 为每个线程指定结束后的回调函数
>>> result
[0, 1, 8, 9, 64, 25, 216, 49, 512, 81]
3. 进程
3.1 使用进程处理计算密集型任务
import time
import cv2
import numpy as np
import multiprocessing as mp
def gamma_adjust_py(im, gamma, out_file):
"""伽马增强函数:使用循环逐像素计算"""
rows, cols = im.shape
out = im.astype(np.float32)
for i in range(rows):
for j in range(cols):
out[i,j] = pow(out[i,j]/255, 1/3)*255
cv2.imwrite(out_file, out.astype(np.uint8))
if __name__ == '__main__':
mp.freeze_support()
im_fn = 'river.jpg'
im = cv2.imread(im_fn, cv2.IMREAD_GRAYSCALE)
rows, cols = im.shape
print('照片分辨率为%dx%d'%(cols, rows))
t0 = time.time()
pro_1 = mp.Process(target=gamma_adjust_py, args=(im[:rows//2], 3, 'river_3_1.jpg'))
pro_1.daemon = True
pro_1.start()
pro_2 = mp.Process(target=gamma_adjust_py, args=(im[rows//2:], 3, 'river_3_2.jpg'))
pro_2.daemon = True
pro_2.start()
pro_1.join()
pro_2.join()
t1 = time.time()
print('启用两个进程逐像素处理,耗时%0.3f秒钟'%(t1-t0))
照片分辨率为4088x2752
启用两个进程逐像素处理,耗时17.786秒钟
3.2 进程间通信示例
import os, time, random
import multiprocessing as mp
def sub_process_A(q):
"""A进程函数:生成数据"""
while True:
time.sleep(5*random.random()) # 在0-5秒之间随机延时
q.put(random.randint(10,100)) # 随机生成[10,100]之间的整数
def sub_process_B(q):
"""B进程函数:使用数据"""
words = ['哈哈,', '天哪!', 'My God!', '咦,天上掉馅饼了?']
while True:
print('%s捡到了%d块钱!'%(words[random.randint(0,3)], q.get()))
if __name__ == '__main__':
print('主进程(%s)开始,按回车键结束本程序'%os.getpid())
q = mp.Queue(10)
p_a = mp.Process(target=sub_process_A, args=(q,))
p_a.daemon = True
p_a.start()
p_b = mp.Process(target=sub_process_B, args=(q,))
p_b.daemon = True
p_b.start()
input()
3.3 进程池
apply_async(func[, args[, kwds[, callback]]]) :非阻塞式提交。即使进程池已满,也会接
受新的任务,不会阻塞主进程。新任务将处于等待状态。apply(func[, args[, kwds]]) :阻塞式提交。若进程池已满,则主进程阻塞,直至有空闲
进程可以使用。
import time
import multiprocessing as mp
def power(x, a=2):
"""进程函数:幂函数"""
time.sleep(1)
print('%d的%d次方等于%d'%(x, a, pow(x, a)))
def demo():
mpp = mp.Pool(processes=4)
for item in [2,3,4,5,6,7,8,9]:
mpp.apply_async(power, (item, )) # 非阻塞提交新任务
#mpp.apply(power, (item, )) # 阻塞提交新任务
mpp.close() # 关闭进程池,意味着不再接受新的任务
print('主进程走到这里,正在等待子进程结束')
mpp.join() # 等待所有子进程结束
print('程序结束')
if __name__ == '__main__':
demo()
4. 协程
4.1 协程和线程的区别
4.2 协程演进史
4.3 协程应用示例
import asyncio, random
async def rich(q, total):
"""任性的富豪,随机撒钱"""
while total > 0:
money = random.randint(10,100)
total -= money
await q.put(money) # 随机生成[10,100]之间的整数
print('富豪潇洒地抛了%d块钱'%money)
await asyncio.sleep(3*random.random()) # 在0-3秒之间随机延时
async def lucky(q, name):
"""随时可以捡到钱的幸运儿"""
while True:
money = await q.get()
q.task_done()
print('%s捡到了%d块钱!'%(name, money))
async def run():
q = asyncio.Queue(1)
producers = [asyncio.create_task(rich(q, 300))]
consumers = [asyncio.create_task(lucky(q, name)) for name in 'ABC']
await asyncio.gather(*producers,)
await q.join()
for c in consumers:
c.cancel()
if __name__ == '__main__':
asyncio.run(run())
富豪潇洒地抛了42块钱
A捡到了42块钱!
富豪潇洒地抛了97块钱
A捡到了97块钱!
富豪潇洒地抛了100块钱
B捡到了100块钱!
富豪潇洒地抛了35块钱
C捡到了35块钱!
富豪潇洒地抛了17块钱
A捡到了17块钱!
富豪抛完了手中的钱,转身离去