
图匹配 科普
参考 https://www.renfei.org/blog/bipartite-matching.html
匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。
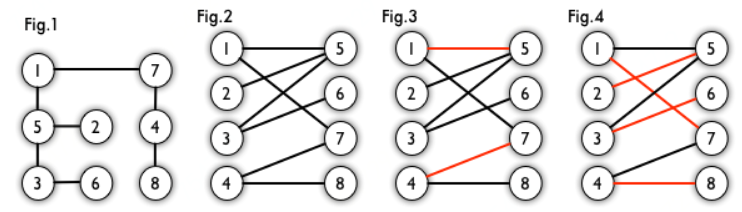
例如,图 3、图 4 中红色的边就是图 2 的匹配,如图3中,1-5边和4-7边没有公共顶点。
我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。
例如,图 3 中 1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。
图 4 是一个最大匹配,它包含 4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。
图 4 是一个完美匹配。
显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。
但并非每个图都存在完美匹配。
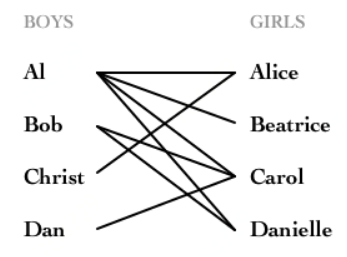
举例来说:如下图所示,如果在某一对男孩和女孩之间存在相连的边,就意味着他们彼此喜欢。是否可能让所有男孩和女孩两两配对,使得每对儿都互相喜欢呢?
图论中,这就是完美匹配问题。
如果换一个说法:最多有多少互相喜欢的男孩/女孩可以配对儿?这就是最大匹配问题。
基本概念讲完了。
求解最大匹配问题的一个算法是匈牙利算法,下面讲的概念都为这个算法服务。
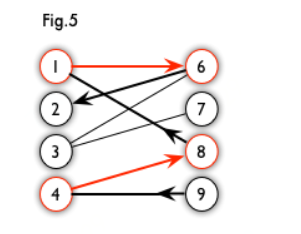
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。
例如,图 5 中的一条增广路,如图 6 所示(图中的匹配点均用红色标出):
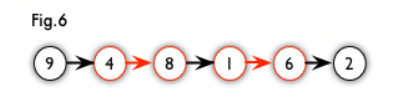
增广路有一个重要特点:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。
只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。
我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)。匈牙利算法正是这么做的。
匈牙利树一般由 BFS 构造(类似于 BFS 树)。从一个未匹配点出发运行 BFS(唯一的限制是,必须走交替路),直到不能再扩展为止。例如,由图 7,可以得到如图 8 的一棵 BFS 树:
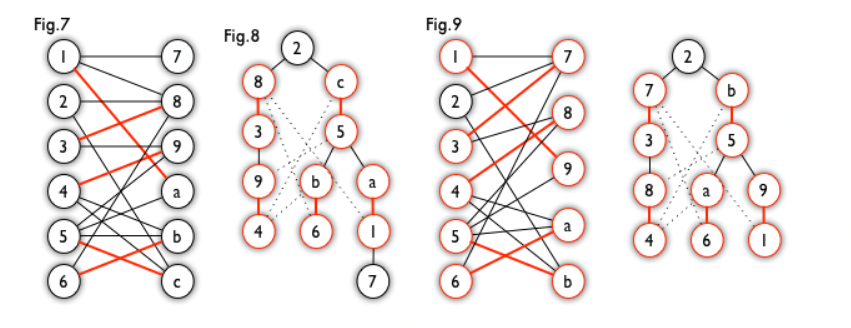
这棵树存在一个叶子节点为非匹配点(7 号),但是匈牙利树要求所有叶子节点均为匹配点,因此这不是一棵匈牙利树。如果原图中根本不含 7 号节点,那么从 2 号节点出发就会得到一棵匈牙利树。这种情况如图 9 所示(顺便说一句,图 8 中根节点 2 到非匹配叶子节点 7 显然是一条增广路,沿这条增广路扩充后将得到一个完美匹配)。