
kafka消费者分组消费的再平衡策略
一,Kafka消费模式
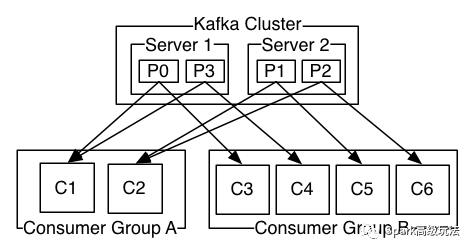
从kafka消费消息,kafka客户端提供两种模式: 分区消费,分组消费。
分区消费对应的就是我们的DirectKafkaInputDStream
分组消费对应的就是我们的KafkaInputDStream
消费者数目跟分区数目的关系:
1),一个消费者可以消费一个到全部分区数据
2),分组消费,同一个分组内所有消费者消费一份完整的数据,此时一个分区数据只能被一个消费者消费,而一个消费者可以消费多个分区数据
3),同一个消费组内,消费者数目大于分区数目后,消费者会有空余=分区数-消费者数
二,分组消费的再平衡策略
当一个group中,有consumer加入或者离开时,会触发partitions均衡partition.assignment.strategy,决定了partition分配给消费者的分配策略,有两种分配策略:
1,org.apache.kafka.clients.consumer.RangeAssignor
默认采用的是这种再平衡方式,这种方式分配只是针对消费者订阅的topic的单个topic所有分区再分配,Consumer Rebalance的算法如下:
1),将目标Topic下的所有Partirtion排序,存于TP
2),对某Consumer Group下所有Consumer按照名字根据字典排序,存于CG,第i个Consumer记为Ci
3),N=size(TP)/size(CG)
4),R=size(TP)%size(CG)
5),Ci获取的分区起始位置=N*i+min(i,R)
6),Ci获取的分区总数=N+(if (i+ 1 > R) 0 else 1)
2,org.apache.kafka.clients.consumer.RoundRobinAssignor
这种分配策略是针对消费者消费的所有topic的所有分区进行分配。当有新的消费者加入或者有消费者退出,就会触发rebalance。这种方式有两点要求
A),在实例化每个消费者时给每个topic指定相同的流数
B),每个消费者实例订阅的topic必须相同
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();topicCountMap.put(topic, new Integer(1));Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
其中,topic对应的value就是流数目。对应的kafka源码是在
在kafka.consumer.ZookeeperConsumerConnector的consume方法里,根据这个参数构建了相同数目的KafkaStream。
这种策略的具体分配步骤:
1),对所有topic的所有分区按照topic+partition转string之后的hash进行排序
2),对消费者按字典进行排序
3),然后轮训的方式将分区分配给消费者
3,举例对比
举个例子,比如有两个消费者(c0,c1),两个topic(t0,t1),每个topic有三个分区p(0-2),
那么采用RangeAssignor,结果为:
* C0: [t0p0, t0p1, t1p0, t1p1]
* C1: [t0p2, t1p2]
采用RoundRobinAssignor,结果为:
* C0: [t0p0, t0p2, t1p1]
* C1: [t0p1, t1p0, t1p2]
三,本节源码设计的重要概念及zookeeper相关目录
1,本节涉及的zookeeper目录
A),消费者目录,获取子节点就可以获取所有的消费者
/consumers/group.id/ids/
B),topic的目录,可以获取topic,分区及副本信息
/brokers/topics/topicName
值:
{"version":1,"partitions":{"0":[5,6],"2":[1,4],"27":[0,4],"1":[7,0]}}
partitions对应值的key是分区id,value是Broker id列表。
C),分区所属的消费者线程关系
/consumers/groupId/owners/topic/partitionid
值就是消费者线程id,也就是在A向获取的消费者后加了一个id值。
2,涉及的概念
A),消费者ID
val consumerIdString = {var consumerUuid : String = nullconfig.consumerId match {case Some(consumerId) // for testing only=> consumerUuid = consumerIdcase None // generate unique consumerId automatically=> val uuid = UUID.randomUUID()consumerUuid = "%s-%d-%s".format(InetAddress.getLocalHost.getHostName, System.currentTimeMillis,uuid.getMostSignificantBits().toHexString.substring(0,8))}config.groupId + "_" + consumerUuid}
B),消费者线程ID
主要是在消费者id的基础上,根据消费者构建指定的topic的Stream数目,递增加了个数字的值
for ((topic, nConsumers) <- topicCountMap) {val consumerSet = new mutable.HashSet[ConsumerThreadId]assert(nConsumers >= 1)for (i <- 0 until nConsumers)consumerSet += ConsumerThreadId(consumerIdString, i) //ConusmerId的结尾加上一个常量区别 owners 目录下可以看到consumerThreadIdsPerTopicMap.put(topic, consumerSet)}
ConsumerThreadId
"%s-%d".format(consumer, threadId)C),TopicAndPartition
带topic名字的表示每个分区,重点关注其toString方法,在比较的时候用到了。
TopicAndPartition(topic: String, partition: Int)override def toString = "[%s,%d]".format(topic, partition)四,源码解析
1,AssignmentContext
主要作用是根据指定的消费组,消费者,topic信息,从zookeeper上获取相关数据并解析得到,两种分配策略要用的四个数据结构。解析过程请结合zookeeper的相关目录及节点的数据类型和kafka源码自行阅读。
class AssignmentContext(group: String, val consumerId: String, excludeInternalTopics: Boolean, zkClient: ZkClient) {//(topic,ConsumerThreadIdSet) //指定一个消费者,根据每个topic指定的streams数目,构建相同数目的流val myTopicThreadIds: collection.Map[String, collection.Set[ConsumerThreadId]] = {val myTopicCount = TopicCount.constructTopicCount(group, consumerId, zkClient, excludeInternalTopics)myTopicCount.getConsumerThreadIdsPerTopic}//(topic 分区) /brokers/topics/topicname 值val partitionsForTopic: collection.Map[String, Seq[Int]] =ZkUtils.getPartitionsForTopics(zkClient, myTopicThreadIds.keySet.toSeq)//(topic,ConsumerThreadId(当前消费者id)) ///consumers/Groupid/ids 子节点val consumersForTopic: collection.Map[String, List[ConsumerThreadId]] =ZkUtils.getConsumersPerTopic(zkClient, group, excludeInternalTopics)///consumers/Groupid/ids的所有的子节点val consumers: Seq[String] = ZkUtils.getConsumersInGroup(zkClient, group).sorted}2,RangeAssignorclass RangeAssignor() extends PartitionAssignor with Logging {def assign(ctx: AssignmentContext) = {val partitionOwnershipDecision = collection.mutable.Map[TopicAndPartition, ConsumerThreadId]()for ((topic, consumerThreadIdSet) <- ctx.myTopicThreadIds) {val curConsumers = ctx.consumersForTopic(topic) //当前topic的所有消费者val curPartitions: Seq[Int] = ctx.partitionsForTopic(topic) //当前topic的所有分区//val nPartsPerConsumer = curPartitions.size / curConsumers.sizeval nConsumersWithExtraPart = curPartitions.size % curConsumers.sizeinfo("Consumer " + ctx.consumerId + " rebalancing the following partitions: " + curPartitions +" for topic " + topic + " with consumers: " + curConsumers)for (consumerThreadId <- consumerThreadIdSet) {val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //获取当前消费者线程的在集合中的位置assert(myConsumerPosition >= 0)//获取分区的起始位置val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)//获取当前消费者消费的分区数目val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)/*** Range-partition the sorted partitions to consumers for better locality.* The first few consumers pick up an extra partition, if any.*/if (nParts <= 0)warn("No broker partitions consumed by consumer thread " + consumerThreadId + " for topic " + topic)else {//将分区关系描述写入partitionOwnershipDecisionfor (i <- startPart until startPart + nParts) {val partition = curPartitions(i)info(consumerThreadId + " attempting to claim partition " + partition)// record the partition ownership decisionpartitionOwnershipDecision += (TopicAndPartition(topic, partition) -> consumerThreadId)}}}}partitionOwnershipDecision}}
3,RoundRobinAssignor
class RoundRobinAssignor() extends PartitionAssignor with Logging {def assign(ctx: AssignmentContext) = {val partitionOwnershipDecision = collection.mutable.Map[TopicAndPartition, ConsumerThreadId]()// check conditions (a) and (b) topic, List[ConsumerThreadId]val (headTopic, headThreadIdSet) = (ctx.consumersForTopic.head._1, ctx.consumersForTopic.head._2.toSet)//测试输出ctx.consumersForTopic.foreach { case (topic, threadIds) =>val threadIdSet = threadIds.toSetrequire(threadIdSet == headThreadIdSet,"Round-robin assignment is allowed only if all consumers in the group subscribe to the same topics, " +"AND if the stream counts across topics are identical for a given consumer instance.\n" +"Topic %s has the following available consumer streams: %s\n".format(topic, threadIdSet) +"Topic %s has the following available consumer streams: %s\n".format(headTopic, headThreadIdSet))}//为传入的集合创建一个循环迭代器,传入之前排序是按照字典排序val threadAssignor = Utils.circularIterator(headThreadIdSet.toSeq.sorted)info("Starting round-robin assignment with consumers " + ctx.consumers)//TopicAndPartition 按照字符串的hash排序val allTopicPartitions = ctx.partitionsForTopic.flatMap { case(topic, partitions) =>info("Consumer %s rebalancing the following partitions for topic %s: %s".format(ctx.consumerId, topic, partitions))partitions.map(partition => {TopicAndPartition(topic, partition) //toString = "[%s,%d]".format(topic, partition)})}.toSeq.sortWith((topicPartition1, topicPartition2) => {/** Randomize the order by taking the hashcode to reduce the likelihood of all partitions of a given topic ending* up on one consumer (if it has a high enough stream count).*///按照hash值进行排序topicPartition1.toString.hashCode < topicPartition2.toString.hashCode})//过滤得到当前消费者的线程idallTopicPartitions.foreach(topicPartition => {val threadId = threadAssignor.next()if (threadId.consumer == ctx.consumerId)partitionOwnershipDecision += (topicPartition -> threadId)})//返回得到结果partitionOwnershipDecision}}
五,总结
本文主要是讲解分组消费的两种将分区分配给消费者线程的分配策略。结合前面两篇
<Kafka源码系列之Consumer高级API性能分析>和<Kafka源码系列之源码解析SimpleConsumer的消费过程>,大家应该会对kafka的java 消费者客户端的实现及性能优缺点有彻底的了解了。
分组,分区两种种模型其实跟kafka集群并没有关系,是我们java客户端实现的区别。生产中可以根据自己的需要选择两种消费模型。建议流量不是很大,也没过分的性能需求,选择分组消费,这样同分组多消费者的话相当于实现了同分组的消费者故障转移。