
见识一下京东的秒杀系统,真“天花板”!
京东秒杀是京东最大的营销频道,近年来随着业务的高速发展,频道商品数量和用户流量都呈现出迅猛增长的态势。
同时业务方规划未来频道商品数量会增加 5 至 10 倍,对商品池扩容诉求较为强烈,这对我们现有的系统架构提出了挑战。
为了应对商品数量激增引起的风险,秒杀后台组在年初成立了秒杀商品池扩容技术优化专项,在 618 前按计划完成了千万级商品池扩容的架构升级。本文主要介绍秒杀商品池扩容专项的优化经验。
京东秒杀频道业务主要包括两部分:
一部分是频道核心服务,即直接面向终端用户提供频道服务。
另一部分是维护秒杀商品池数据,为商详、购物车等多端提供秒杀商品读服务,以展示“京东秒杀”的促销氛围标签,我们称为秒杀商品打标服务。
图 1:京东秒杀频道业务
秒杀系统是一个高并发大流量系统,使用缓存技术来提高系统性能。
在频道核心服务的历史业务迭代过程中,采用了在内存中全量缓存商品池数据的缓存方案。
这是因为频道业务中存在全量商品按照多维度排序的诉求,同时在频道发展初期商品数量不多,采用全量缓存的方式内存压力不大,开发成本较低。
由于秒杀商品存在时促销、库存有限的特点,对数据更新的实时性要求较高,我们通过 ZK 通知的方式实现商品数据更新。
原系统架构如图 2 所示:
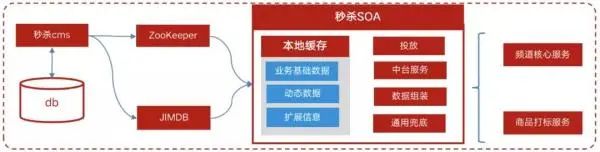
图 2:京东秒杀原系统架构图
秒杀 CMS 系统在商品录入或更新时,以活动的维度将商品数据推动到 JIMDB(京东内部分布式缓存与高速键值存储服务,类似于 Redis)中,同时通过 ZooKeeper 发送通知。
秒杀 SOA 系统监听通知后从 JIMDB 中获取最新的数据,更新本地缓存,以提供频道核心服务和商品打标服务。
1
在以往大促期间,当商品池数量激增时,观察到系统的堆内存消耗过快,同时 Minor GC 垃圾回收效果有限,Minor GC 回收后堆内存低点不断抬高,堆内存呈持续增长的态势,并且会规律性地定期猛增。
Full GC 较为频繁,对 CPU 利用率的影响较大,接口性能毛刺现象严重。
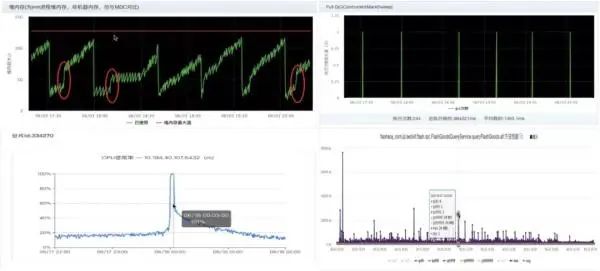
图 3:系统异常监控
通过 JVM 堆内存变化图可以看到:
堆空间增长很快,且 Minor GC 无法回收新增的堆空间。
堆空间呈现有规律的上升,且会定期猛增,推测和定时任务有关。
Full GC后,内存回收率高,排除内存泄漏。
Full GC 对 CPU 利用率影响较大。
频繁 GC 对系统的稳定性和接口的性能造成严重的影响分析堆对象增长情况,通过 jmap -histo 指令在发生 Full GC 前后打印 JVM 堆中的对象,如图 4、图 5 所示:
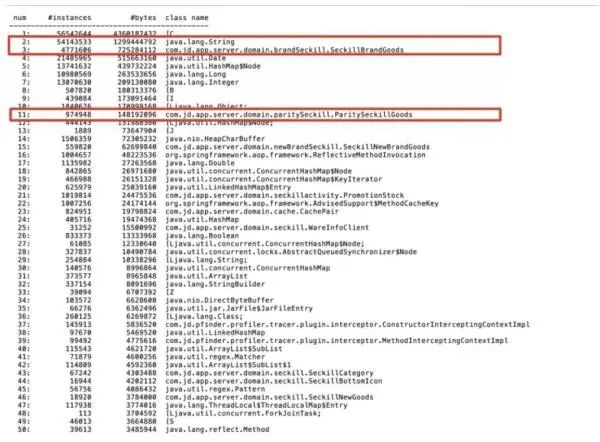
图 4:发生 Full GC 前堆内存对象
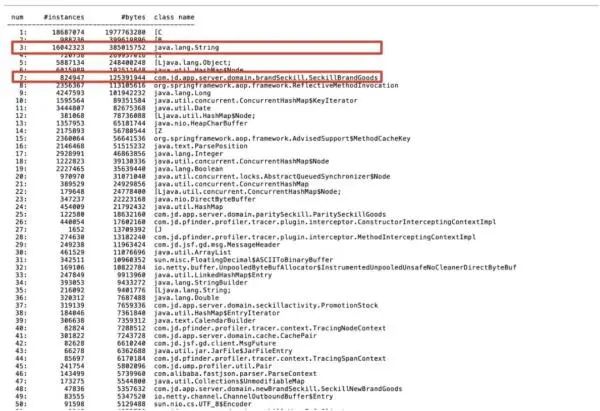
图 5:发生 Full GC 后堆内存对象
从 Full GC 前后堆中对象分布情况分析,以品类秒杀为例,在 Full GC 后堆中不到 100 万商品对象,占内存 125M 左右,和品类秒杀实际有效商品数量大致相当, String 对象共占约 385M 左右。
而在发生 Full GC 前,堆中品类秒杀商品数量达到了接近 500 万,占用内存达到了 700M,另外 String 对象占用内存达到 1.2G。
结合系统架构分析,可以确定是在商品的覆盖更新过程中,旧对象未被回收而不断进入老年代,老年代内存占用越来越高,最终导致堆内存不足而产生 Full GC。
堆对象中的 String 对象也是这种更新方式的副产品,这是因为商品数据在 JIMDB 中以 String 方式存储,在更新时会从 JIMDB 中拉取到本地反序列化后得到对象列表。
可以从图 6 所示问题代码中看到产生大 String 对象的原因:
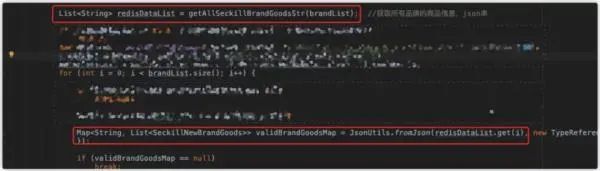
图 6:问题代码
对于上述的全量更新场景,旧对象和临时产生的 String 对象满足垃圾回收的条件,为什么没有在 Minor GC 阶段被回收?
我们知道大多数情况下,对象在新生代 Eden 区中分配,对象进入老年代有以下几种情况:
①大对象直接进入年老代:大对象即需要大量连续内存空间的 Java 对象,如长字符串及数组。
大对象会导致内存剩余空间足够时,就提前触发垃圾收集以获取足够的连续空间来安置,同时大对象的频繁复制也会影响性能。
虚拟机提供了一个 -XX:PretenureSizeThreshold 参数,使大于该阈值的对象直接在老年代分配。为避免临时 String 对象直接进入老年代的情况,我们显式关闭了该功能。
②长期存活的对象将进入年老代:虚拟机给每个对象定义了一个对象年龄计数器,在对象在 Eden 创建并经过第一次 Minor GC 后仍然存活,并能被 Suivivor 容纳的话,将会被移动到 Survivor 空间,并对象年龄设置为 1。
每经历一次 Minor GC,年龄增加 1 岁,当到达阈值时(可以通过参数 -XX: MaxTenuringThreshold 设置,CMS 垃圾回收器默认值为 6),将会晋升老年代。上述分析情况,临时 String 对象不会存活过 6 次 Minor GC。
③动态对象年龄判定:为了更好地适应不同程序内存状况,虚拟机并不硬性要求对象年龄达到 MaxTenuringThreshold 才能晋升老年代。
如果在 Survivor 空间中小于等于某个年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入年老代。
通过上述分析,我们发现临时 String 对象最有可能触发了动态对象年龄判定机制而进入老年代。
打印虚拟机 GC 信息,并添加-XX: +PrintTenuringDistribution参数来打印发生 GC 时新生代的对象年龄信息,得到图 7 所示 GC 日志信息:
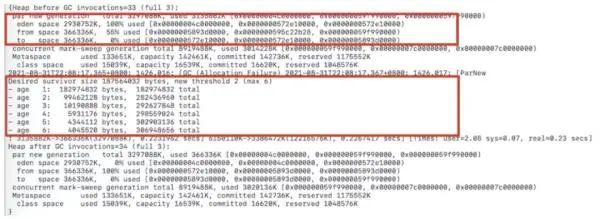
图 7:GC 日志
从 GC 日志可以看到,Survivor 空间大小为 358M,Survivor 区的目标使用率默认是 50%,Desired Survivor size 是 179M,age <= 2 的对象大小总和为 269M。
因此虽然设定的晋升阈值是 6,虚拟机动态计算晋升阈值为 2,最终导致 age 大于等于 2 的对象都进入老年代。
我们尝试从优化 JVM 参数的方式解决问题,效果并不理想。做过的尝试有:
增大年轻代的空间来减少对象进入老年代,结果适得其反,STW 更加频繁,CPU 利用率波动也更大。
改用 G1 垃圾收集器,效果不明显,CPU 利用率波动也更大。
显式设置晋升老年代的阈值(MaxTenuringThreshold),试图推迟对象进入老年代的速度,无任何效果。
上述问题分析的结论对我们的启示是:如果在新生代中频繁产生朝生夕死的大对象,会触发虚拟机的动态对象年龄判定机制,降低对象进入老年代的门槛,导致堆内存增长过快。
2
①双缓存区定时散列更新
通过上面的分析可以发现,为了防止堆内存增长过快,需要控制商品数据更新的粒度和频次。
原有的商品更新方案是商品数据按照活动的维度全量覆盖更新,每个商品的状态变化都会触发更新操作。
我们希望数据更新能控制在更小的范围,同时能够控制数据更新的频率,最终设计出双缓存区定时散列更新方案,如图 8 所示。
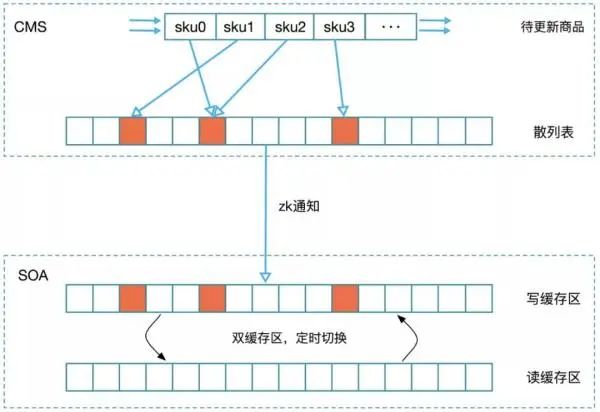
图 8:双缓存区定时散列更新示意图
该方案的实现是将活动下的商品以 SKU 维度散列到不同的桶中,更新的操作以桶的粒度进行。
同时为了控制数据更新的频率,我们在 SOA 端设计了双缓存区定时切量的方式。
在 CMS 商品数据更新时,会映射到需要更新的桶,并实时通知 SOA 端;在 SOA 端收到 ZK 通知后,会在读缓存区标记需要更新的桶,但不会实时的更新数据。
在达到定时时间后,会自动切换读写缓存区,此时会读取读缓存区中标记的待更新桶,从 JIMDB 中获取桶对应的商品列表,完成数据的细粒度分段更新。
该方案散列份数和定时时间可以根据具体业务情况进行调整,在性能和实时性上取得平衡,在上线后取得了较好的优化效果。
②引入本地 LRU 缓存
双缓存区定时散列更新的方案虽然在系统性能上得到了提升,但依然无法支持千万级商品的扩容。
为了彻底摆脱机器内存对商品池容量的限制,我们启动了秒杀架构的全面升级,核心思路是引入本地 LRU 缓存组件,实现冷数据淘汰,以控制内存中缓存商品的总数量在安全区间。
系统拆分:原系统存在的问题是,频道核心服务和商品打标服务共用相同的基础数据,存在系统耦合的问题。
从商品池角度分析,频道核心服务商品池是秒杀商品池的子集。从业务角度分析,频道核心服务业务逻辑复杂,调用链路长,响应时间长,商品打标服务逻辑简单,调用链路短,响应时间短。
将频道核心服务和商品打标服务进行拆分,独立部署,实现资源隔离,这样可以根据业务特点做针对性优化。
频道核心服务可以减少内存中商品缓存的数量,商品打标服务可以升级商品缓存方案,另外也可以规避架构升级过程中对频道核心服务的影响。
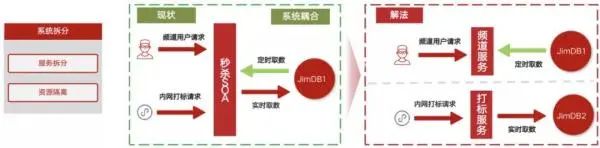
图 9:系统拆分
缓存方案优化:频道核心服务历史逻辑复杂,且直接面向终端用户,升级难度大。
在扩容专项一期中的主要优化点是拆分出频道核心服务商品池,去除非频道展示商品,以减少商品缓存数量。一期优化主要聚焦于秒杀打标服务的缓存方案升级。
在原有的系统架构中秒杀商品池全量缓存在内存中,这会导致商品数量激增时,JVM 堆内存资源紧张,商品池的容量受到限制,且无法水平扩容。
商品以活动的维度进行存储和更新,会导致大 key 的问题,在进行覆盖更新时会在内存中产生临时的大对象,不利于 JVM 垃圾回收表现。
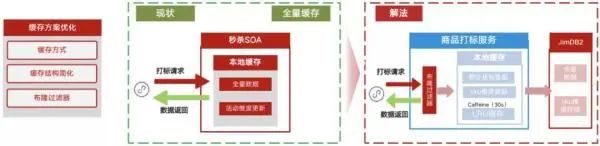
图 10:缓存方案升级
对于拆封后的商品打标服务,缓存方案优化的总体思路是实现冷热数据的拆分。
升级后的商品打标服务不再使用本地全量缓存,而是使用 JIMDB 全量缓存+本地 LRU 缓存组件的方式。
对缓存组件的要求是在缓存数据达到预设商品数量上限时,实现冷数据的清退,同时具有较高的缓存命中率和读写性能。
在对比常用的缓存框架 Caffeine 和 Guava Cache 后最终采用 Caffeine 缓存。
其优势有:
性能更优。Caffeine 的读写性能显著优于 Guava, 这是由于 Guava 中读写操作夹杂着过期时间的处理,一次 put 操作中有可能会触发淘汰操作,所以其读写性能会受到一定影响。
而 Caffeine 对这些事件的操作是异步的,将事件提交至队列,通过默认的 ForkJoinPool.commonPool() 或自己配置的线程池,进行取队列操作,再进行异步淘汰、过期操作。
高命中率,低内存占用。Guava 使用分段 LRU 算法,而 Caffeine 使用了一种结合 LRU、LFU 优点的算法:W-TinyLFU,可以使用较少的资源来记录访问频次,同时能够解决稀疏突发访问元素的问题。
升级后的架构图如图 11 所示:
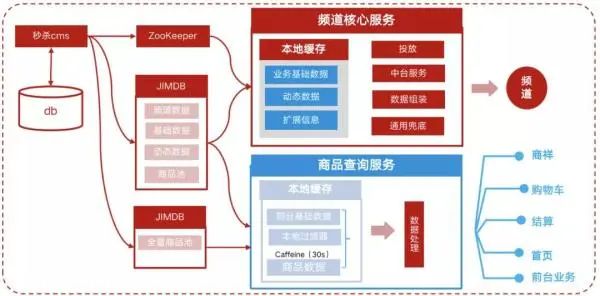
图 11:升级后架构图
频道核心服务和商品打标服务独立部署,资源隔离。秒杀 CMS 在商品录入和更新时,以 SKU 维度写入 JIMDB 中组成全量秒杀商品池。
商品打标服务通过 Caffeine 缓存的方式,设置写入写入 30s 过期,最大缓存 200w 商品数据,实现热数据缓存,过期数据和冷数据的淘汰。
③引入布隆过滤器
在非秒杀 SKU 查询处理上,为了避免缓存穿透问题(即单个无效商品的高频次查询,如果本地缓存中没有则每次请求都会访问到 JIMDB),我们对于非秒杀商品的查询结果,在本地缓存中存储一个空值标识,避免无效 SKU 请求每次都访问到 JIMDB。
商详、购物车等渠道商品池数量比秒杀商品池高几个数量级,秒杀查询服务请求 SKU 中存在大量的非秒杀商品,这会导致本地缓存的命中率降低,同时带来缓存雪崩的风险。
为了拦截大量非秒杀 SKU 的请求,我们引入过滤器机制。在本地过滤器的选择上,我们尝试使用所有有效商品 SkuId 组成的 Set 集合来生成本地过滤器,上线后观察到本地过滤器数据更新时会产生性能波动。
分析发现这种方式空间复杂度高,内存占用比较高。过滤器优化为布隆过滤器后,内存占用降低,性能得到进一步提升。
3
在完成架构升级后,经过单机压测、灰度验证、灰度上线、全量压测等过程严格验证了新系统的性能和结果准确性,在 618 大促前新系统全量平稳上线。
从近年来大促期间系统表现来看,优化效果显著,如图 12、图 13 所示,主要体现在以下几个方面。
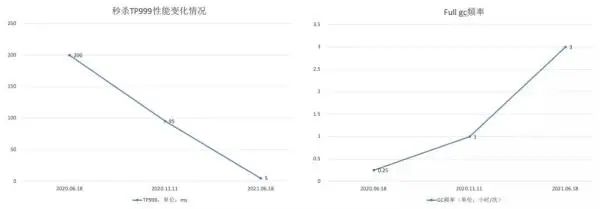
图 12:大促性能表现对比
业务支撑:秒杀商品池数量持续增长,由于架构的调整全量商品缓存在 JIMDB,新系统支持水平扩容,后续可支持更高数量级的商品,满足业务的长期规划。
性能优化:大促期间打标服务的接口 tp999 持续下降,618 大促接口性能提升 90%,同时从接口性能对比上看,接口性能的毛刺现象得到解决。
稳定性提升:GC 频率持续下降,系统稳定性得到提高。

图 13:接口性能监控对比
4
本次秒杀商品池扩容优化专项通过优化商品更新方式、系统拆分、优化缓存方案等方式,实现了系统架构升级,提升了频道的商品容量和性能,达到了预设目标。
⭐️如果喜欢本篇,欢迎「点赞、在看 」,下次见~