
那些年,面试被虐过的红黑树
背景
上周,一位同学去面试了,过程大致如下:
面试官:java开发,三年了,熟悉哪些java集合?
同学:ArrayList、HashMap、TreeMap、LinkedList.....(回答了挺多的)。
面试官:说说HashMap在JDK7和JDK8的区别。
同学:主要区别有四点:
1、实现方式:JDK7 中使用数组+链表来实现,JDK8使用的数组+链表+红黑树
2、新节点插入到链表的顺序不同:JDK7插入在头部,JDK8插入在尾部
3、JDK8 的hash算法有所简化
4、扩容机制有所优化
(此时,同学的心里想,幸好我背过老田的面试小抄java集合部分)
面试官:既然,你知道JDK8引入了红黑树,我这里有黑笔和红笔,你在这个墙壁上收画一颗红黑树(小会议室是玻璃墙)。
同学:(尼玛,这个我不会呀,他肯定还会问红黑的特点,红黑树和平和二叉树有什么区别,红黑旋转,增加、删除...,咽了咽口水说)额....这个不太会。
世间都是套路,还以为问完区别就差不多了,或者顶多再问问HashMap为什么线程不安全、HashMap如何扩容之类的问题。你有过类似的经历吗?
今天我们就来研究研究面试官难为这位同学的红黑树。其实,说到红黑树,我们搞java开发的多多少少还是知道些,对很大部分朋友来说是熟悉而又陌生的家伙。熟悉是因为很多人可能学过,也看过不少红黑树的文章,同时我们都直接或者间接的使用过。陌生是因为红黑树,在设计和实现上的复杂性让很多人望而生畏,就和Spring源码一样。
其实,总得来说,红黑树的定义还是比较简单,但你必须知道一些基本的知识,比如什么是树?树怎么遍历?二叉树?平衡二叉树?...
红黑树无非就是在插入和删除的过程中自平衡规则多了点,不过也不是想象中的那么可怕,今天我们就来搞定它。

树
生活中的树

数据结构中的树
树结构是一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合。
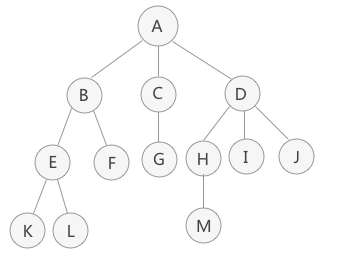
可以看出,和我们生活中的树就是一毛一样的,只是看起来一个是正着一个是倒着。倒着知识为了便于理解。
上图中的树是使用树结构存储的集合 {A,B,C,D,E,F,G,H,I,J,K,L,M} 的示意图。对于数据 A 来说,和数据 B、C、D 有关系;对于数据 B 来说,和 E、F 有关系。这就是“一对多”的关系。
树的节点
「结点」:使用树结构存储的每一个数据元素都被称为“结点”。例如,图 中,数据元素 A 就是一个结点;
「父结点(双亲结点)、子结点和兄弟结点」:对于图 中的结点 A、B、C、D 来说,A 是 B、C、D 结点的父结点(也称为“双亲结点”),而 B、C、D 都是 A 结点的子结点(也称“孩子结点”)。对于 B、C、D 来说,它们都有相同的父结点,所以它们互为兄弟结点。
「树根结点」(简称“「根结点」”):每一个非空树都有且只有一个被称为根的结点。图 中,结点A就是整棵树的根结点。
「叶子结点」:如果结点没有任何子结点,那么此结点称为叶子结点(叶结点)。例如图 中,结点 K、L、F、G、M、I、J 都是这棵树的叶子结点。
树根的判断依据:如果一个结点没有父结点,那么这个结点就是整棵树的根结点。
子树
子树:如图 中,整棵树的根结点为结点 A,而如果单看结点 B、E、F、K、L 组成的部分来说,也是棵树,而且节点 B 为这棵树的根结点。所以称 B、E、F、K、L 这几个结点组成的树为整棵树的子树;同样,结点 E、K、L 构成的也是一棵子树,根结点为 E。
注意:单个结点也是一棵树,只不过根结点就是它本身。图 1中,结点 K、L、F 等都是树,且都是整棵树的子树。
知道了子树的概念后,树也可以这样定义:树是由根结点和若干棵子树构成的。
空树
空树:如果集合本身为空,那么构成的树就被称为空树。空树中没有结点。
二叉树
二叉树指的是每个节点最多只能有两个子数的有序树。通常左边的子树称为左子树 ,右边的子树称为右子树 。
二叉树简单的示意图如下:

左子树与右子树
通常左边的子树称为左子树 ,右边的子树称为右子树 。这里说的有序树强调的是二叉树的左子树和右子树的次序不能随意颠倒。
java中的定义
public class Node {
T data;
Node left;
Node right;
}
C++中的定义
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
排序二叉树
所谓排序二叉树,顾名思义,排序二叉树是有顺序的,它是一种特殊结构的二叉树,我们可以对树中所有节点进行排序和检索。
性质
若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值; 具有递归性,排序二叉树的左子树、右子树也是排序二叉树。
排序二叉树简单示意图:
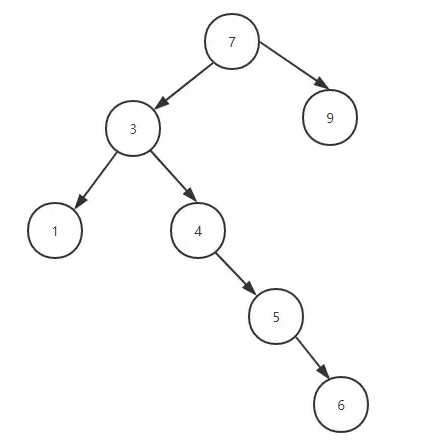
排序二叉树退化成链表
排序二叉树的左子树上所有节点的值小于根节点的值,右子树上所有节点的值大于根节点的值,当我们插入一组元素正好是有序的时候,这时会让排序二叉树退化成链表。
正常情况下,排序二叉树是如下图这样的:
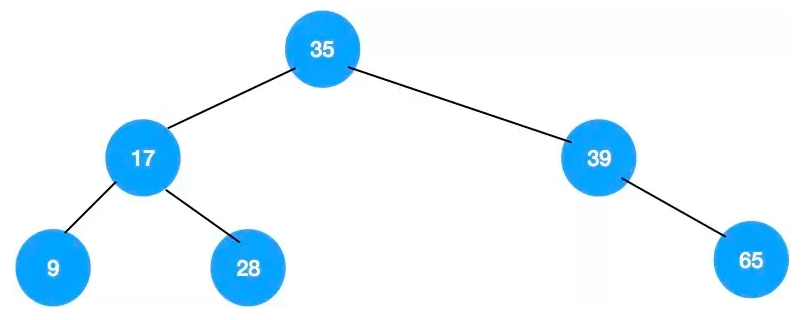
但是,当插入的一组元素正好是有序的时候,排序二叉树就变成了下边这样了,就变成了普通的链表结构,如下图所示:
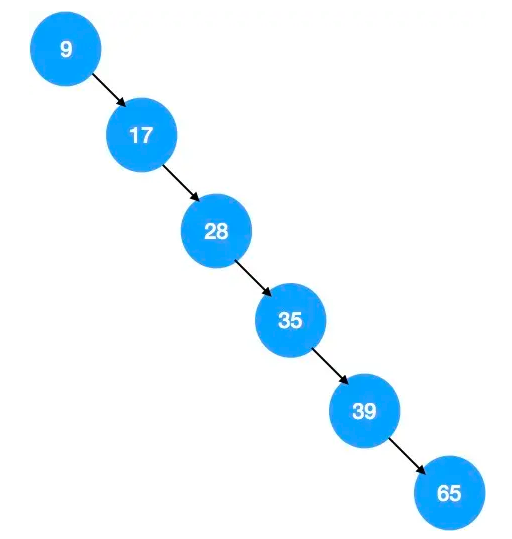
正常情况下的排序二叉树检索效率类似于二分查找,二分查找的时间复杂度为 O(log n),但是如果排序二叉树退化成链表结构,那么检索效率就变成了线性的 O(n) 的,这样相对于 O(log n) 来说,检索效率肯定是要差不少的。
思考,二分查找和正常的排序二叉树的时间复杂度都是 O(log n),那么为什么是O(log n) ?
为了解决排序二叉树在特殊情况下会退化成链表的问题(链表的检索效率是 O(n) 相对正常二叉树来说要差不少),所以有人发明了平衡二叉树和红黑树类似的平衡树。
平衡二叉树
平衡二叉树,又被称为AVL(Adelson-Velsky and Landis)树 。
定义:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
两个条件:
平衡二叉树必须是排序二叉树,也就是说平衡二叉树他的左子树所有节点的值必须小于根节点的值,它的右子树上所有节点的值必须大于它的根节点的值。 左子树和右子树的深度之差的绝对值不超过1。
红黑树
哈哈哈,这回,终于轮我倒了。
红黑树(如上图,引用自维基百科)是一种 自平衡 的二叉树,所谓的自平衡是指在插入和删除的过程中,红黑树会采取一定的策略对树的组织形式进行调整,以尽可能的减少树的高度,从而节省查找的时间。
红黑树的特性如下:
结点是红色或黑色 根结点始终是黑色 叶子结点(NIL 结点)都是黑色 红色结点的两个直接孩子结点都是黑色(即从叶子到根的所有路径上不存在两个连续的红色结点) 从任一结点到每个叶子的所有简单路径都包含相同数目的黑色结点
很多人,估计也就是在面试抱佛jio的时候,背背红黑树的这五个特性罢了。
以上性质保证了红黑树在满足平衡二叉树特征的前提下,还可以做到 从根到叶子的最长路径最多不会超过最短路径的两倍 ,这主要是考虑两个极端的情况,由性质 4 和 5 我们可以知道在一棵红黑树上从根到叶子的最短路径全部由黑色结点构成,而最长结点则由红黑结点交错构成(始终按照一红一黑的顺序组织),又因为最短路径和最长路径的黑色结点数目是一致的,所以最长路径上的结点数是最短路径的两倍。
自平衡策略
对于一棵红黑树的操作最基本的无外乎增删改查,其中查和改都不会改变树的结构,所以与普通平衡二叉树操作无异。剩下的就是增删操作,插入和删除都会破坏树的结构,不过借助一定的平衡策略能够让树重新满足定义。平衡策略可以简单概括为三种:左旋转 、右旋转 ,以及 变色 。在插入或删除结点之后,只要我们沿着结点到根的路径上执行这三种操作,就可以最终让树重新满足定义。
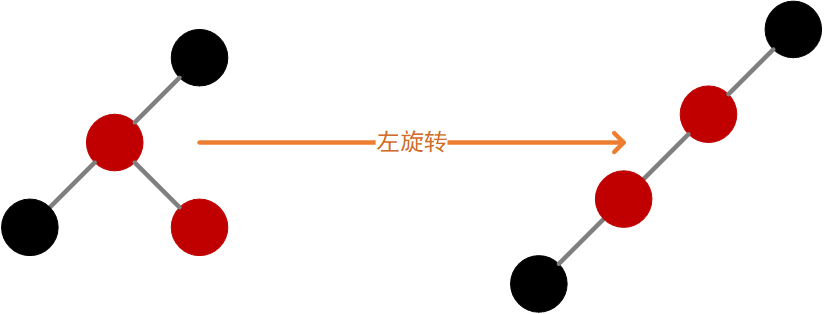
「左旋转」
对于当前结点而言,如果右子结点为红色,左子结点为黑色,则执行左旋转,如下图:
「右旋转」
对于当前结点而言,如果左子、左孙子结点均为红色,则执行右旋转,如下图:

「变色」
对于当前结点而言,如果左、右子结点均为红色,则执行变色,如下图:

插入操作
红黑树作为平衡二叉树的一种,同样需要借助于查找操作定位插入点,不过红黑树约定 新插入的结点一律为红色 ,这主要也是为了简化树的自平衡过程。对于一棵空树而言,插入结点为红色会增加一次变色操作,但是对于其余的情况,如果插入的结点是一个黑色结点,那么必然会破坏性质 5,而插入一个红色结点有可能会破坏性质 4,但是此时我们可以通过简单的策略对树进行调整以重新满足定义。
我们约定 X 为插入的结点,P 为 X 的父结点,G 为 X 的祖父结点,U 为 X 的叔叔结点。
下面遵从上述策略分场景对插入过程进行探讨:
1.新插入结点 X 是根结点。
此时新插入结点为红色,违背性质 2,只需将其变为黑色即可。
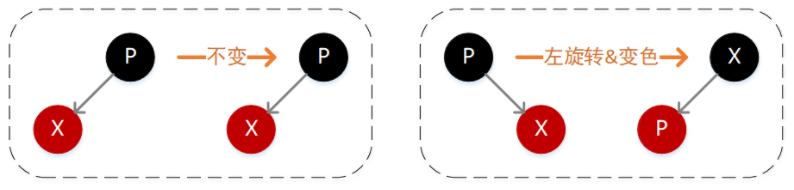
2.新插入结点 X 的父结点 P 是黑色
此时需要依据新插入结点 X 值相对于父结点 P 的大小分为两种情况,如果小于则将 X 简单插入到 P 的左子位置即可(下图左),如果 X 的值大于 P,则需要将 X 插入到 P 的右子结点位置,然后执行一次左旋转即可(下图右)。
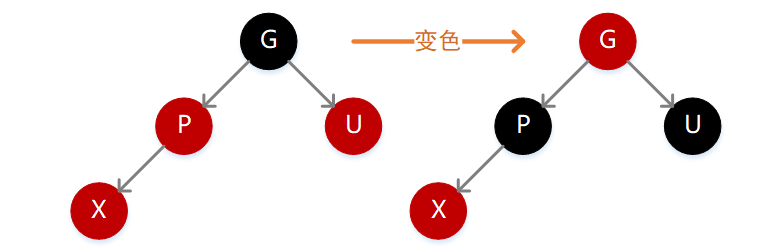
3.父结点 P 为红色,同时存在叔叔结点 U 也为红色
因为 P 为红色,按照性质 4 则 G 必定为黑色,如果 X 的值小于 P,则需要在 P 的左子位置插入(如下图),插入后不满足性质 4,此时只需要执行一次变色操作,将 P、G、U 的颜色反转一下即可,因为 G 变为红色,所以路径长度减 1,但是因为 P 和 U 都变为了黑色,所以路径长度又加 1,最终长度不变,但此时 G 变为了红色,所以需要继续向上递归。
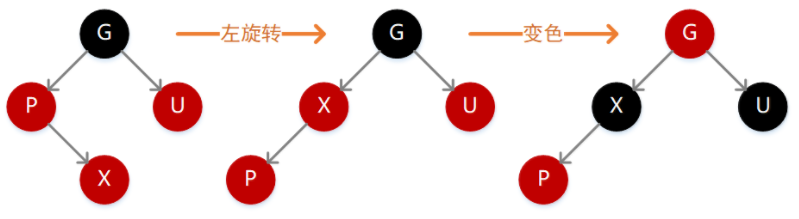
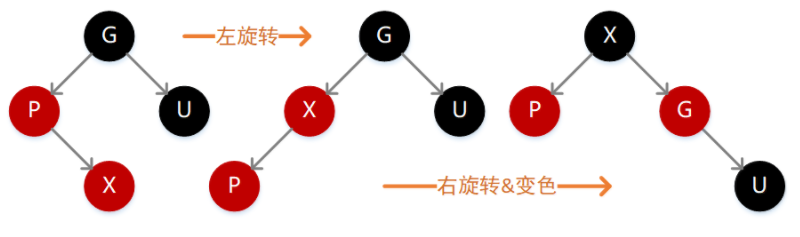
如果 X 的值大于 P,则需要在 P 的右子位置插入(如下图),插入后不满足性质 4,此时需要先执行左旋转变为上面这种情况,继续变色即可。
4.父结点 P 为红色,同时叔叔结点 U 为黑色或不存在
因为 P 为红色,按照性质 4 则 G 必定为黑色,如果 X 的值小于 P,则需要在 P 的左子位置插入(如下图),插入后不满足性质 4,此时需要先执行一次右旋转,旋转之后仍然违背性质 4,同时左子树的高度减 1,这个时候需要再执行一次变色操作即可满足定义。
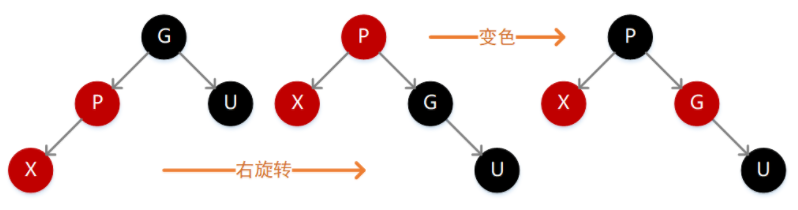
如果 X 的值大于 P,则需要在 P 的右子位置插入(如下图),插入后不满足性质 4,此时我们需要执行一次左旋转,然后就转换成了上面这种情况,继续右旋转、变色即可。
删除操作
红黑树作为平衡二叉树的一种,同样需要借助于查找操作定位删除点,在执行删除之前我们需要判断待删除结点有几个孩子结点,如果是 2 个的话我们需要从结点的左子树中寻找值最大的结点,或者从右子树中寻找值最小的结点,并用结点值替换掉待删除结点(只要目标结点值从树上消失即可,不要纠结具体删除的是哪个结点)。这两个结点有一个共性,即最多只有一个孩子结点(因为已经是自己所处范围内的最大和最小了嘛,一山不容二虎(鼠)),此时就将需求转变成删除只有一个孩子结点的结点,相对要简单了许多。
我们约定 X 为待删除的结点,P 为 X 的父结点,S 为 X 的孩子结点,B 为 X 的兄弟结点,BL 为 B 的左孩子结点,BR 为 B 的右孩子结点。
如果待删除结点 X 是一个红色结点,则直接删除即可,不会违反定义。 如果待删除结点 X 是一个黑色结点,且其孩子结点 S 是红色的,那么只需要将 X 替换成 S,同时将 S 由红变黑即可。 如果需要删除的结点 X 是黑色的,同时它的孩子结点 S 也是黑色的,这种情况需要进一步分场景讨论。
对于第三种情况我们首先将 X 替换成 S,并重命名其为 N,N 沿用 X 对于长辈和晚辈的称呼,需要清楚这里实际删除的是 X 结点,并且删除之后通过 N 的路径长度减 1。
1.N 是新的根
这种情况比较简单,不需要再做任何调整。
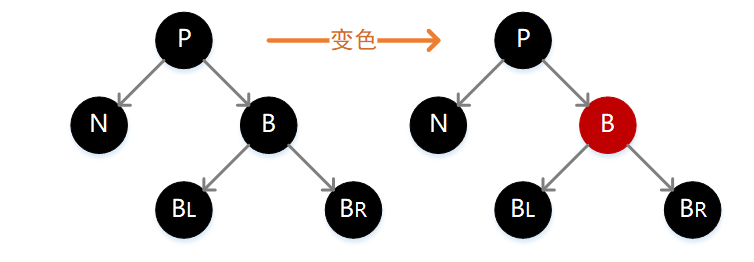
2.N 的父结点、兄弟结点 B,以及 B 的孩子结点均为黑色
如下图,此时只需要将 B 变为红色即可,这样所有通过 B 的路径减 1,与所有通过 N 的路径正好一致,但是此时通过 P 的路径都减少了 1 个长度,所以需要向上递归对结点 P 继续判定。
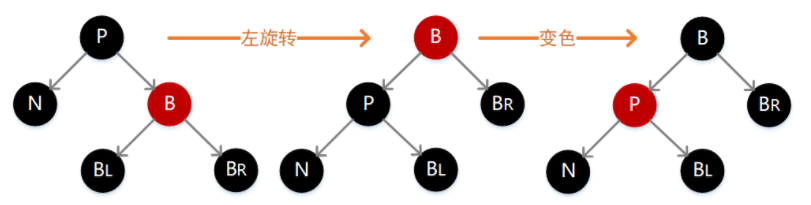
3.N 的兄弟结点 B 为红色,其余结点均为黑色
如下图,此时需要执行一次左旋转,然后将 P 和 B 的颜色互换。调整前后各个结点的路径没有变化,但是因为之前经过 N 的路径长度少了一个单位,所以此时仍然不满足定义,需要按照后面的场景继续调整。
4.N 的父结点 P 为红色,兄弟结点 B,以及 B 的孩子结点均为黑色
如下图,此时我们只需要简单互换 P 和 B 的颜色,这种情况下对于不通过 N 的结点路径没有影响,但是却让通过 N 的结点路径加 1,正好弥补之前删除操作所带来的损失。
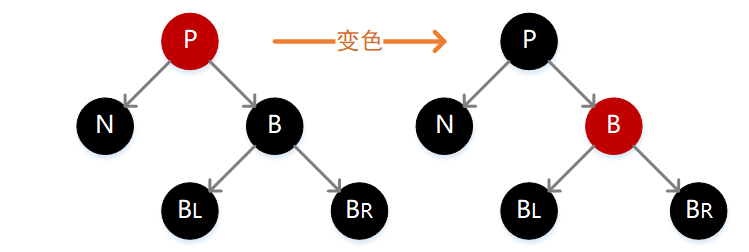
5.N 的兄弟结点 B 为黑色,B 的左孩子为红色,B 的右孩子为黑色
如下图,此时我们需要先执行一次右旋转操作,然后互换 B 与 BL 的颜色,操作之后通过所有结点的路径长度并没有发生变化,却让 N 有了一个新的黑色兄弟结点,并且该兄弟结点的右孩子为红色,从而可以按照接下去介绍的一种场景继续调整。
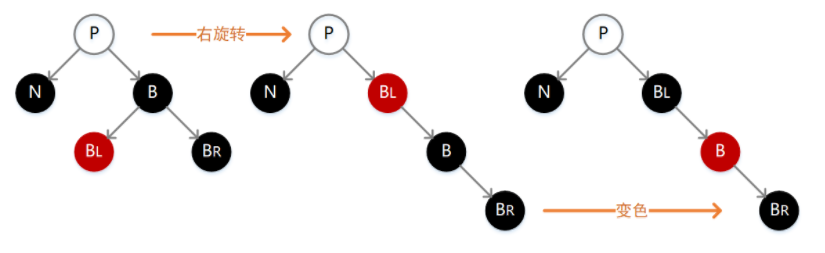
注:白色结点表示该结点既可以是黑色也可以是红色,后续图示亦是如此。
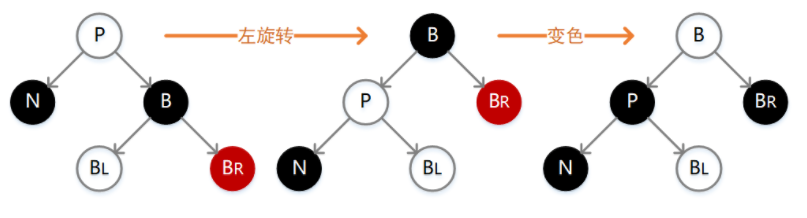
6.N 的兄弟结点 B 为黑色,B 的右孩子为红色
如下图,此时我们需要先执行一次左旋转,并互换 P 和 B 的颜色,同时将 B 的右孩子结点变为黑色。变更之后,除 N 外其余结点的路径长度未发生变化,但是经过 N 的路径上却增加了一个黑色结点,这刚好弥补之前删除操作所带来的损失。
总结
我们从树的概念说起,到二叉树、平衡二叉树,最后到红黑树。其实红黑树的主要难点在于插入和删除过程中的自平衡调整,其中插入过程的调整相对简单,删除的过程需要处理的情况要多一些,但不管是插入还是删除,都建议读者将所有的图放置在一起进行观察,能够发现其中承前启后的奥妙,本文鉴于篇幅就不再贴出长图。
参考:www.zhenchao.org
「强烈推荐这个网站」:
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
更直观的演示插入和删除的过程:
推荐阅读: SpringBoot开发秘籍 - 集成Graphql Query
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。