
3 个不常见但非常实用的Pandas 使用技巧

来源:DeepHub IMBA 本文共1000字,建议阅读5分钟 本文为你演示一些不常见,但是却非常有用的 Pandas 函数。
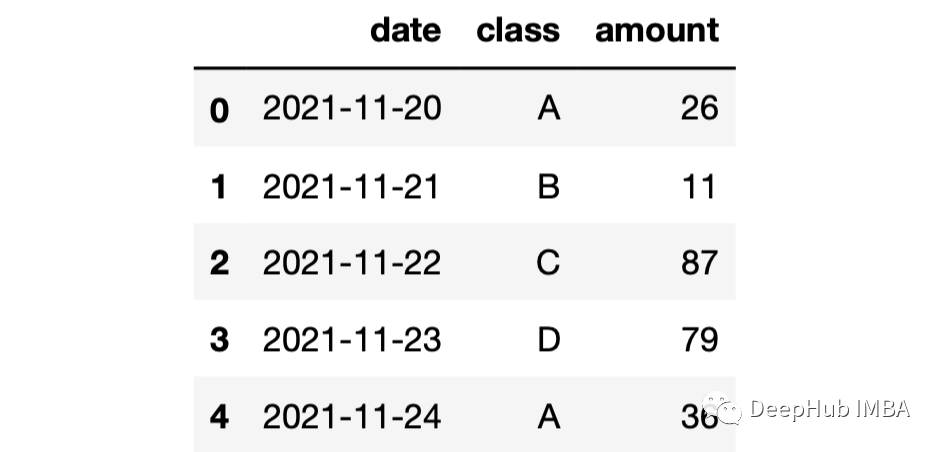
import numpy as npimport pandas as pddf = pd.DataFrame({"date": pd.date_range(start="2021-11-20", periods=100, freq="D"),"class": ["A","B","C","D"] * 25,"amount": np.random.randint(10, 100, size=100)})df.head()
1. To_period
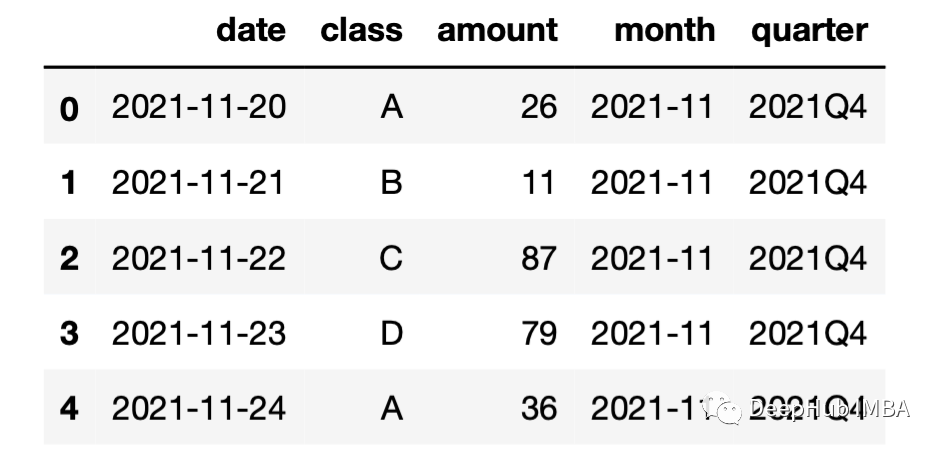
df["month"] = df["date"].dt.to_period("M")df["quarter"] = df["date"].dt.to_period("Q")df.head()
df["month"].value_counts()# output2021-12 312022-01 312022-02 272021-11 11Freq: M, Name: month, dtype: int64--------------------------df["quarter"].value_counts()# output2022Q1 582021Q4 42Freq: Q-DEC, Name: quarter, dtype: int64
2. Cumsum 和 groupby
df["cumulative_sum"] = df["amount"].cumsum()df.head()

df["class_cum_sum"] = df.groupby("class")["amount"].cumsum()让我们查看 A 类的结果。
df[df["class"]=="A"].head()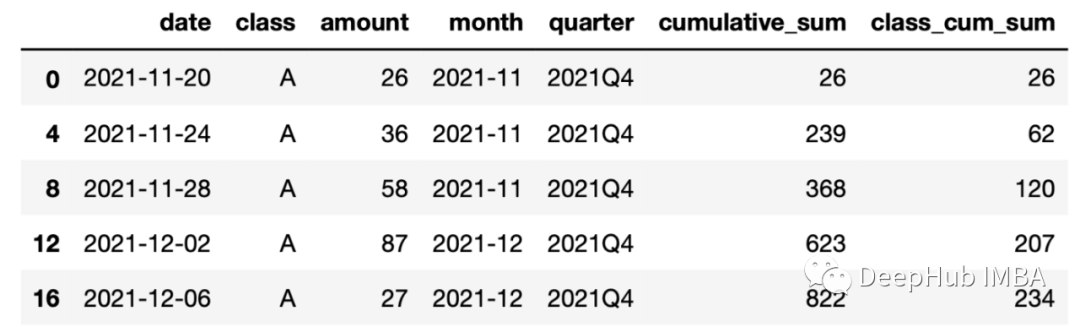
3. Category数据类型
df.dtypes# outputdate datetime64[ns]class objectamount int64month period[M]quarter period[Q-DEC]cumulative_sum int64class_cum_sum int64
= df["class"].astype("category")df.dtypes# outputdate datetime64[ns]class objectamount int64month period[M]quarter period[Q-DEC]cumulative_sum int64class_cum_sum int64class_category categorydtype: object
df.memory_usage()# outputIndex 128date 800class 800amount 800month 800quarter 800cumulative_sum 800class_cum_sum 800class_category 304dtype: int64
评论