
面试官:HashSet如何保证元素不重复?

来源 | Java面试真题解析(ID:aimianshi666)
本文已收录《Java常见面试题》系列,开源地址:https://gitee.com/mydb/interview
HashSet 实现了 Set 接口,由哈希表(实际是 HashMap)提供支持。HashSet 不保证集合的迭代顺序,但允许插入 null 值。也就是说 HashSet 不能保证元素插入顺序和迭代顺序相同。HashSet 具备去重的特性,也就是说它可以将集合中的重复元素自动过滤掉,保存存储在 HashSet 中的元素都是唯一的。
1.HashSet 基本用法
HashSet 基本操作方法有:add(添加)、remove(删除)、contains(判断某个元素是否存在)和 size(集合数量)。这些方法的性能都是固定操作时间,如果哈希函数是将元素分散在桶中的正确位置。HashSet 基本使用如下:
// 创建 HashSet 集合
HashSet strSet = new HashSet<>();
// 给 HashSet 添加数据
strSet.add("Java");
strSet.add("MySQL");
strSet.add("Redis");
// 循环打印 HashSet 中的所有元素
strSet.forEach(s -> System.out.println(s));
2.HashSet 无序性
HashSet 不能保证插入元素的顺序和循环输出元素的顺序一定相同,也就是说 HashSet 其实是无序的集合,具体代码示例如下:
HashSet mapSet = new HashSet<>();
mapSet.add("深圳");
mapSet.add("北京");
mapSet.add("西安");
// 循环打印 HashSet 中的所有元素
mapSet.forEach(m -> System.out.println(m));
以上程序的执行结果如下: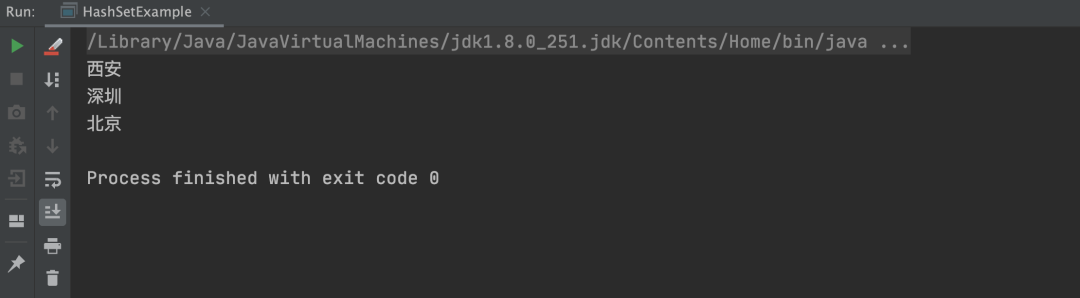 从上述代码和执行结果可以看出,HashSet 插入的顺序是:深圳 -> 北京 -> 西安,而循环打印的顺序却是:西安 -> 深圳 -> 北京,所以 HashSet 是无序的,不能保证插入和迭代的顺序一致。
从上述代码和执行结果可以看出,HashSet 插入的顺序是:深圳 -> 北京 -> 西安,而循环打印的顺序却是:西安 -> 深圳 -> 北京,所以 HashSet 是无序的,不能保证插入和迭代的顺序一致。
PS:如果要保证插入顺序和迭代顺序一致,可使用 LinkedHashSet 来替换 HashSet。
3.HashSet 错误用法
有人说 HashSet 只能保证基础数据类型不重复,却不能保证自定义对象不重复?这样说对吗?我们通过以下示例来说明此问题。
3.1 HashSet 与基本数据类型
使用 HashSet 存储基本数据类型,实现代码如下:
HashSet longSet = new HashSet<>();
longSet.add(666l);
longSet.add(777l);
longSet.add(999l);
longSet.add(666l);
// 循环打印 HashSet 中的所有元素
longSet.forEach(l -> System.out.println(l));
以上程序的执行结果如下: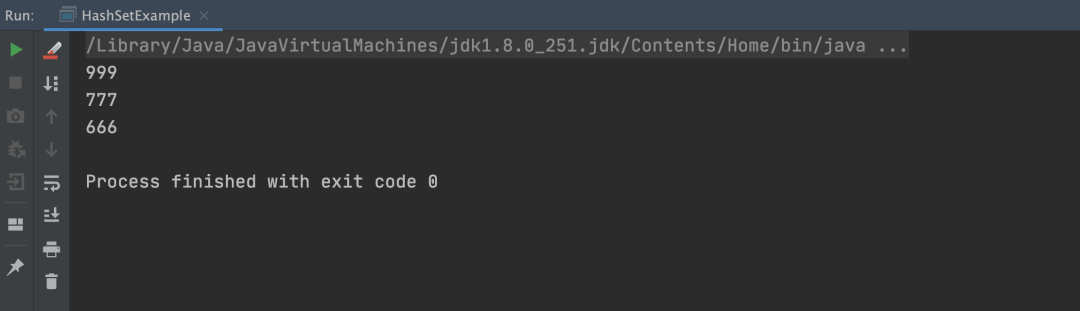 从上述结果可以看出,使用 HashSet 可以保证基础数据类型不重复。
从上述结果可以看出,使用 HashSet 可以保证基础数据类型不重复。
3.2 HashSet 与自定义对象类型
接下来,将自定义对象存储到 HashSet 中,实现代码如下:
public class HashSetExample {
public static void main(String[] args) {
HashSet personSet = new HashSet<>();
personSet.add(new Person("曹操", "123"));
personSet.add(new Person("孙权", "123"));
personSet.add(new Person("曹操", "123"));
// 循环打印 HashSet 中的所有元素
personSet.forEach(p -> System.out.println(p));
}
}
@Getter
@Setter
@ToString
class Person {
private String name;
private String password;
public Person(String name, String password) {
this.name = name;
this.password = password;
}
}
以上程序的执行结果如下: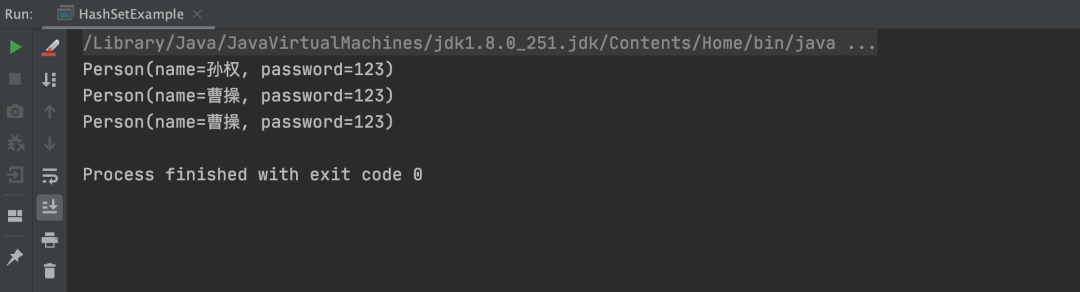 从上述结果可以看出,自定义对象类型确实没有被去重,那也就是说 HashSet 不能实现自定义对象类型的去重咯?其实并不是,HashSet 去重功能是依赖元素的 hashCode 和 equals 方法判断的,通过这两个方法返回的都是 true 那就是相同对象,否则就是不同对象。而前面的 Long 类型元素之所以能实现去重,正是因为 Long 类型中已经重写了 hashCode 和 equals 方法,具体实现源码如下:
从上述结果可以看出,自定义对象类型确实没有被去重,那也就是说 HashSet 不能实现自定义对象类型的去重咯?其实并不是,HashSet 去重功能是依赖元素的 hashCode 和 equals 方法判断的,通过这两个方法返回的都是 true 那就是相同对象,否则就是不同对象。而前面的 Long 类型元素之所以能实现去重,正是因为 Long 类型中已经重写了 hashCode 和 equals 方法,具体实现源码如下:
@Override
public int hashCode() {
return Long.hashCode(value);
}
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}
//省略其他源码......
更多关于 hashCode 和 equals 的内容,详见:https://mp.weixin.qq.com/s/40zaEJEkQYM3Awk2EwIrWA
那么,想让 HashSet 支持自定义对象去重,只需要在自定义对象中重写 hashCode 和 equals 方法即可,具体实现代码如下:
@Setter
@Getter
@ToString
class Person {
private String name;
private String password;
public Person(String name, String password) {
this.name = name;
this.password = password;
}
@Override
public boolean equals(Object o) {
if (this == o) return true; // 引用相等返回 true
// 如果等于 null,或者对象类型不同返回 false
if (o == null || getClass() != o.getClass()) return false;
// 强转为自定义 Person 类型
Person persion = (Person) o;
// 如果 name 和 password 都相等,就返回 true
return Objects.equals(name, persion.name) &&
Objects.equals(password, persion.password);
}
@Override
public int hashCode() {
// 对比 name 和 password 是否相等
return Objects.hash(name, password);
}
}
重新运行以上代码,执行结果如下图所示: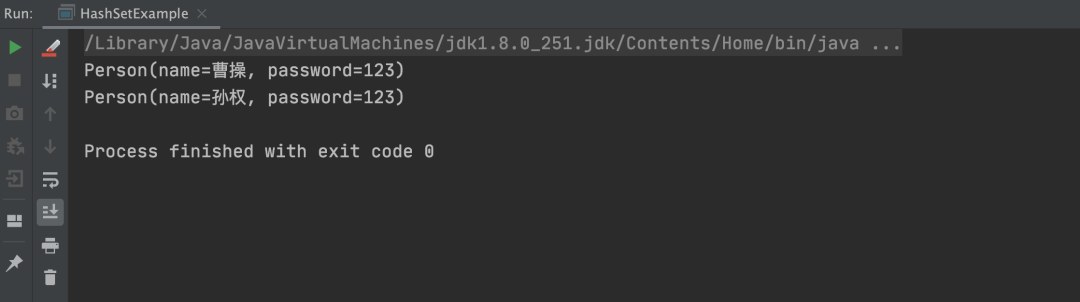 从上述结果可以看出,之前的重复项“曹操”已经被去重了。
从上述结果可以看出,之前的重复项“曹操”已经被去重了。
4.HashSet 如何保证元素不重复?
我们只要了解了 HashSet 执行添加元素的流程,就能知道为什么 HashSet 能保证元素不重复了?HashSet 添加元素的执行流程是:当把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现,会将对象插入到相应的位置中。但是如果发现有相同 hashcode 值的对象,这时会调用对象的 equals() 方法来检查对象是否真的相同,如果相同,则 HashSet 就不会让重复的对象加入到 HashSet 中,这样就保证了元素的不重复。
为了更清楚的了解 HashSet 的添加流程,我们可以尝试阅读 HashSet 的具体实现源码,HashSet 添加方法的实现源码如下(以下源码基于 JDK 8):
// hashmap 中 put() 返回 null 时,表示操作成功
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
从上述源码可以看出 HashSet 中的 add 方法,实际调用的是 HashMap 中的 put,那么我们继续看 HashMap 中的 put 实现:
// 返回值:如果插入位置没有元素则返回 null,否则返回上一个元素
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
从上述源码可以看出,HashMap 中的 put() 方法又调用了 putVal() 方法,putVal() 的源码如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab;
Node p;
int n, i;
//如果哈希表为空,调用 resize() 创建一个哈希表,并用变量 n 记录哈希表长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/**
* 如果指定参数 hash 在表中没有对应的桶,即为没有碰撞
* Hash函数,(n - 1) & hash 计算 key 将被放置的槽位
* (n - 1) & hash 本质上是 hash % n 位运算更快
*/
if ((p = tab[i = (n - 1) & hash]) == null)
// 直接将键值对插入到 map 中即可
tab[i] = newNode(hash, key, value, null);
else {// 桶中已经存在元素
Node e;
K k;
// 比较桶中第一个元素(数组中的结点)的 hash 值相等,key 相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给 e,用 e 来记录
e = p;
// 当前桶中无该键值对,且桶是红黑树结构,按照红黑树结构插入
else if (p instanceof TreeNode)
e = ((TreeNode) p).putTreeVal(this, tab, hash, key, value);
// 当前桶中无该键值对,且桶是链表结构,按照链表结构插入到尾部
else {
for (int binCount = 0; ; ++binCount) {
// 遍历到链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 检查链表长度是否达到阈值,达到将该槽位节点组织形式转为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 链表节点的与 put 操作
// 相同时,不做重复操作,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 找到或新建一个 key 和 hashCode 与插入元素相等的键值对,进行 put 操作
if (e != null) { // existing mapping for key
// 记录 e 的 value
V oldValue = e.value;
/**
* onlyIfAbsent 为 false 或旧值为 null 时,允许替换旧值
* 否则无需替换
*/
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 更新结构化修改信息
++modCount;
// 键值对数目超过阈值时,进行 rehash
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
从上述源码可以看出,当将一个键值对放入 HashMap 时,首先根据 key 的 hashCode() 返回值决定该 Entry 的存储位置。如果有两个 key 的 hash 值相同,则会判断这两个元素 key 的 equals() 是否相同,如果相同就返回 true,说明是重复键值对,那么 HashSet 中 add() 方法的返回值会是 false,表示 HashSet 添加元素失败。因此,如果向 HashSet 中添加一个已经存在的元素,新添加的集合元素不会覆盖已有元素,从而保证了元素的不重复。如果不是重复元素,put 方法最终会返回 null,传递到 HashSet 的 add 方法就是添加成功。
总结
HashSet 底层是由 HashMap 实现的,它可以实现重复元素的去重功能,如果存储的是自定义对象必须重写 hashCode 和 equals 方法。HashSet 保证元素不重复是利用 HashMap 的 put 方法实现的,在存储之前先根据 key 的 hashCode 和 equals 判断是否已存在,如果存在就不在重复插入了,这样就保证了元素的不重复。
卒然临之而不惊,无故加之而不怒。
博主:80 后程序员。爱好:读书、写作和慢跑。
公众号:Java面试真题解析
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。