
高并发系统三大利器之缓存
引言
随着互联网的高速发展,市面上也出现了越来越多的网站和app。我们判断一个软件是否好用,用户体验就是一个重要的衡量标准。比如说我们经常用的微信,打开一个页面要十几秒,发个语音要几分钟对方才能收到。相信这样的软件大家肯定是都不愿意用的。软件要做到用户体验好,响应速度快,缓存就是必不可少的一个神器。缓存又分进程内缓存和分布式缓存两种:分布式缓存如redis、memcached等,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine等。
缓存特征
缓存作为一个数据数据模型对象,那么它有一些什么样的特征呢?下面我们分别来介绍下这些特征。
命中率
命中率=命中数/(命中数+没有命中数)当某个请求能够通过访问缓存而得到响应时,称为缓存命中。缓存命中率越高,缓存的利用率也就越高。
最大空间
缓存中可以容纳最大元素的数量。当缓存存放的数据超过最大空间时,就需要根据淘汰算法来淘汰部分数据存放新到达的数据。
淘汰算法
缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存淘汰算法来处理,设计适合自身数据特征的淘汰算法能够有效提升缓存命中率。常见的淘汰算法有:
FIFO(first in first out)
「先进先出」。最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。「适用于保证高频数据有效性场景,优先保障最新数据可用」。
LFU(less frequently used)
「最少使用」,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的 hitCount(命中次数)。「适用于保证高频数据有效性场景」。
LRU(least recently used)
「最近最少使用」,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。「比较适用于热点数据场景,优先保证热点数据的有效性。」
进程缓存
为什么需要引入本地缓存,本地缓存的应用场景有哪些?
本地缓存的话是我们的应用和缓存都在同一个进程里面,获取缓存数据的时候纯内存操作,没有额外的网络开销,速度非常快。它适用于缓存一些应用中基本不会变化的数据,比如(国家、省份、城市等)。
项目中一般如何使用、怎么样加载、怎么样更新?
进程缓存的话,一般可以在应用启动的时候,把需要的数据加载到系统中。更新缓存的话可以采取定时更新(实时性不高)。具体实现的话就是在应用中起一个定时任务(「ScheduledExecutorService」、「TimerTask」等),让它每隔多久去加载变更(数据变更之后可以修改数据库最后修改的时间,每次查询变更数据的时候都可以根据这个最后变更时间加上半小时大于当前时间的数据)的数据重新到缓存里面来。如果觉得这个比较麻烦的话,还可以直接全部全量更新(就跟项目启动加载数据一样)。这种方式的话,对数据更新可能会有点延迟。可能这台机器看到的是更新后的数据,那台机器看到的数据还是老的(机器发布时间可能不一样)。所以这种方式比较适用于对数据实时性要求不高的数据。如果对实时性有要求的话可以通过广播订阅mq消息。如果有数据更新mq会把更新数据推送到每一台机器,这种方式的话实时性会比前一种「定时更新」的方法会好。但是实现起来会比较复杂。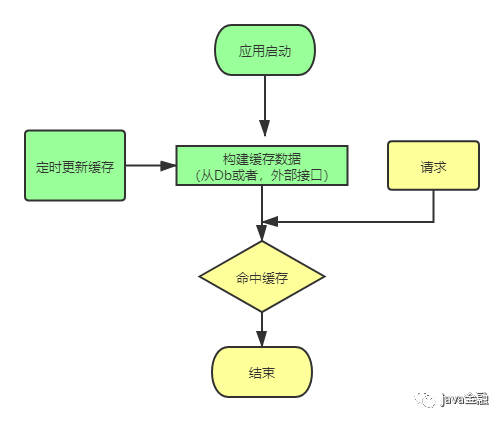
本地缓存有哪些实现方式?
常见本地缓存有以下几种实现方式: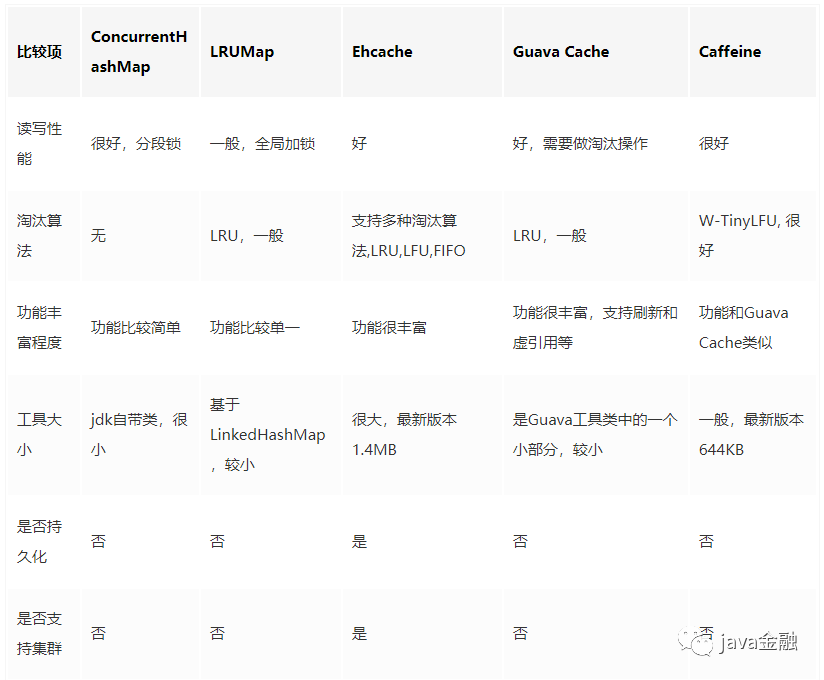 从上述表格我们看出性能最佳的是
从上述表格我们看出性能最佳的是Caffeine。关于这个本地缓存的话我还是强烈推荐的,里面提供了丰富的api,以及各种各样的淘汰算法。如需了解更加详细的话可以看下以前写的这个篇文章《本地缓存性能之王Caffeine》。
本地缓存缺点
本地缓存与业务系统耦合在一起,应用之间无法直接共享缓存的内容。需要每个应用节点单独的维护自己的缓存。每个节点都需要一份一样的缓存,对服务器内存造成一种浪费。本地缓存机器重启、或者宕机都会丢失。
分布式缓存
分布式缓存是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。常见的分布式缓存有 redis、MemCache等。
分布式缓存的应用
在高并发的环境下,比如春节抢票大战,一到放票的时间节点,分分钟大量用户以及黄牛的各种抢票软件流量进入12306,这时候如果每个用户的访问都去数据库实时查询票的库存,大量读的请求涌入到数据库,瞬间Db就会被打爆,cpu直接上升100%,服务马上就要宕机或者假死。即使进行了分库分表也是无法避免的。为了减轻db的压力以及提高系统的响应速度。一般都会在数据库前面加上一层缓存,甚至可能还会有多级缓存。
缓存常见问题
缓存雪崩
指大量缓存同一时间段集体失效,或者缓存整体不能提供服务,导致大量的请求全部到达数据库
对数据CPU和内存造成巨大压力,严重的会造成数据库宕机。因此而形成的一系列连锁反应造成整个系统奔溃。解决这个问题可以从以下方面入手:
保证缓存的高可用。使用redis的集群模式,即使个别 redis节点下线,缓存还是可以用。一般稍微大点的公司还可能会在多个机房部署Redis。这样即使某个机房突然停电,或者光纤又被挖断了,这时候缓存还是可以使用。使用多级缓存。不同级别缓存时间过时时间不一样,即使某个级别缓存过期了,还有其他缓存级别
兜底。比如我们Redis缓存过期了,我们还有本地缓存。这样的话即使没有命中redis,有可能会命中本地缓存。缓存永不过期。Redis中保存的key永久不失效,这样的话就不会出现大量缓存同时失效的问题,但是这种做法会浪费更多的存储空间,一般应该也不会推荐这种做法。 使用随机过期时间。为每一个key都合理的设计一个过期时间,这样可以避免大量的key在同一时刻集体失效。 异步重建缓存。这样的话需要维护每个 key的过期时间,定时去轮询这些key的过期时间。例如一个key的value设置的过期时间是30min,那我们可以为这个key设置它自己的一个过期时间为20min。所以当这个key到了20min的时候我们就可以重新去构建这个key的缓存,同时也更新这个key的一个过期时间。
缓存穿透
指查询一个不存在的数据,每次通过接口或者去查询数据库都查不到这个数据,比如黑客的恶意攻击,比如知道一个订单号后,然后就伪造一些不存在的订单号,然后并发来请求你这个订单详情。这些订单号在缓存中都查询不到,然后会导致把这些查询请求全部打到数据库或者SOA接口。这样的话就会导致数据库宕机或者你的服务大量超时。这种查询不存在的数据就是缓存击穿。解决这个问题可以从以下方面入手:
缓存空值,对于这些不存在的请求,仍然给它缓存一个空的结果,这种方式简单粗暴,但是如果后续这个请求有新值了需要把原来缓存的空值删除掉(所以一般过期时间可以稍微设置的比较短)。 通过布隆过滤器。查询缓存之前先去布隆过滤器查询下这个数据是否存在。如果数据不存在,然后直接返回空。这样的话也会减少底层系统的查询压力。 缓存没有直接返回。这种方式的话要根据自己的实际业务来进行选择。比如固定的数据,一些省份信息或者城市信息,可以全部缓存起来。这样的话数据有变化的情况,缓存也需要跟着变化。实现起来可能比较复杂。
缓存击穿
是指缓存里面的一个热点key(拼多多的五菱宏光神车的秒杀)在某个时间点过期。针对于这一个key有大量并发请求过来然后都会同时去数据库请求数据,瞬间对数据库造成巨大的压力。这个的话可以用缓存雪崩的几种解决方法来避免:
缓存永不过期。Redis中保存的key永久不失效,这样的话就不会出现大量缓存同时失效的问题,但是这种做法会浪费更多的存储空间,一般应该也不会推荐这种做法。 异步重建缓存。这样的话需要维护每个 key的过期时间,定时去轮询这些key的过期时间。例如一个key的value设置的过期时间是30min,那我们可以为这个key设置它自己的一个过期时间为20min。所以当这个key到了20min的时候我们就可以重新去构建这个key的缓存,同时也更新这个key的一个过期时间。互斥锁重建缓存。这种情况的话只能针对于同一个 key的情况下,比如你有100个并发请求都要来取A的缓存,这时候我们可以借助redis分布式锁来构建缓存,让只有一个请求可以去查询DB其他99个(没有获取到锁)都在外面等着,等A查询到数据并且把缓存构建好之后其他99个请求都只需要从缓存取就好了。原理就跟我们java的DCL(double checked locking)思想有点类似。
缓存更新
我们一般的缓存更新主要有以下几种更新策略:
先更新缓存,再更新数据库 先更新数据库,再更新缓存 先删除缓存,再更新数据库 先更新数据源库,再删除缓存
至于选择哪种更新策略的话,没有绝对的选择,可以根据自己的业务情况来选择适合自己的不过一般推荐的话是选择 「先更新数据源库,再删除缓存」。关于这几种更新的介绍可以推荐大家看下博客园大佬孤独烟写的《分布式之数据库和缓存双写一致性方案解析》这一篇文章,看完文章评论也可以去看看,评论跟内容一样精彩。
总结
如果想要真正的设计好一个缓存,我们还是必须要掌握很多的知识,对于不同场景,缓存有各自不同的用法。比如实际工作中我们对于订单详情的一个缓存。我们可能会根据订单的状态来来构建缓存。我们就以机票订单为例,已出行、或者已经取消的订单我们基本上是不会去管的(订单状态已经终止了),这种的话数据基本也不会变了,所以对于这种订单我们设置的过期时间是不是就可以久一点,比如7天或者30天。对于未出行即将起飞的订单,这时候顾客是不是就会频繁的去刷新订单看看,看看有没有晚点什么的,或者登机口是在哪。对于这种实时性要求比较高的订单我们过期时间还是要设置的比较短的,如果是需要更改订单的状态查询的时候可以直接不走缓存,直接查询master库。毕竟这种更改订单状态的操作还是比较有限的。大多数情况都是用来展示的。展示的话是可以允许实时性要求没那么高。总的来说需要开具体的业务,没有通用的方案。看你的业务需求的容忍度,毕竟脱离了业务来谈技术都是耍流氓,是业务驱动技术。
结束
由于自己才疏学浅,难免会有纰漏,假如你发现了错误的地方,还望留言给我指出来,我会对其加以修正。 如果你觉得文章还不错,你的转发、分享、赞赏、点赞、留言就是对我最大的鼓励。 感谢您的阅读,十分欢迎并感谢您的关注。
站在巨人的肩膀上摘苹果:
https://juejin.im/post/6844903665845665805
https://tech.meituan.com/2017/03/17/cache-about.html
https://www.cnblogs.com/rjzheng/p/9041659.html#!comments

往期回顾


