
3个python小工具,Linux服务器性能直线飞起!!!

文 | ssw
来源:Python 技术「ID: pythonall」


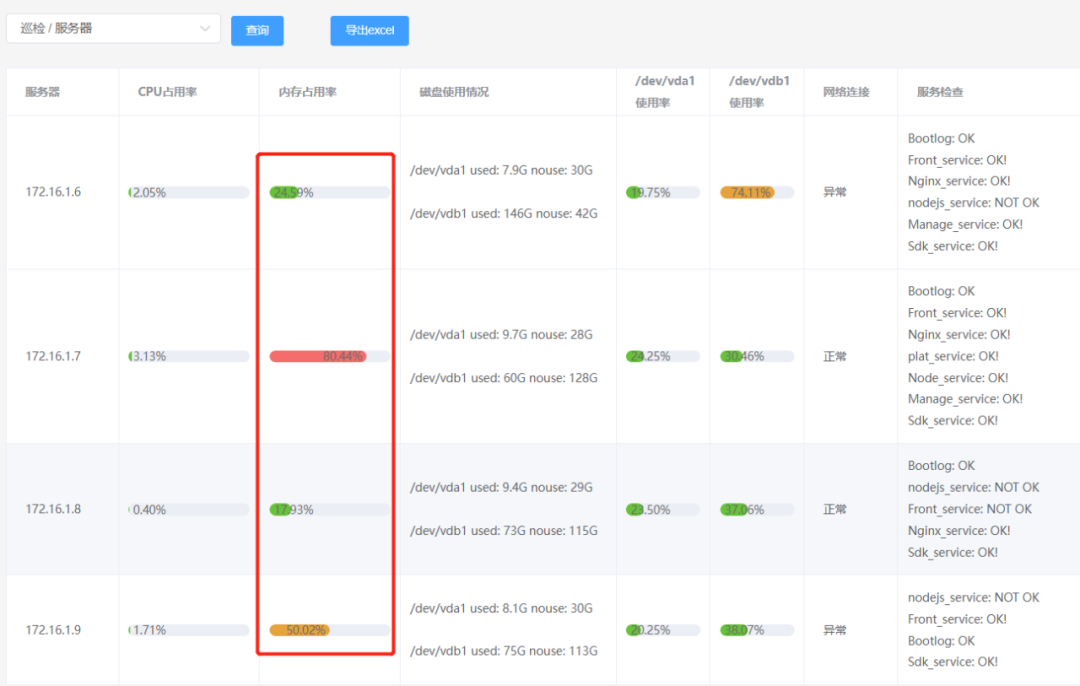
由于工作需要,服务器每周需巡检一次。除了内存、cpu、磁盘、网络连接等数据外,还有不同的服务。
为加快巡检速度和知晓服务器状况,我使用了multiprocessing.dummy多线程、pampy模式匹配和一个elementUI组件,这些工具确能帮忙处理实际问题:
一行代码实现并行 原本二十多台服务器巡检用 shell需3分钟完成,用multiprocessing.dummy模块后只需十几秒pampy模式匹配
搭配正则,匹配出2块磁盘的使用率,方便前端页面展示。数据是从真实服务器上获取的。
import re
from pampy import match
disk_usage = 'diskname: /dev/vda1 used: 35G nouse: 59G USAGE: 35.35% diskname: /dev/vdb1 used: 278G nouse: 190G USAGE: 56.39%'
re_regular = re.compile('diskname: (/\\w+/\\w+).*USAGE: (.*)% diskname: (/\\w+/\\w+).*USAGE: (.*)%')
m= match(disk_usage, re_regular, lambda a,b,c,d: b+','+d)
print(m)
结果如下:35.35,56.39
匹配好后,这2个值很方便就能在前端页面进行展示了

使用 elementUI的progress进度条展示内存百分比
这是elementUI官网的进度条组件
这是使用它的效果:
下面详细介绍这3点:
1. 一行代码实现并行
在某台服务器上做免密钥登录,能直连到其它服务器执行shell脚本,之前的巡检是通过shell脚本执行的:
#登录不同的ip,依次执行/home/ssw/目录下的检查脚本
for ip in `cat /home/ssw/iplist`;do ssh user@$ip "/bin/sh /home/ssw/weekly_check.sh";done
因为是串行执行,经常等到花儿都谢了。于是改用python去执行这些shell命令:cpu、内存、磁盘的检查命令都一样,不同的服务只需定义一个字典,根据ip添加相关命令。再pool.map()一行实现多线程
# -*- coding: utf-8 -*-
import paramiko
import json
from datetime import datetime
import traceback
from pprint import pprint
from multiprocessing.dummy import Pool as ThreadPool
def weekly_check(ip):
#基础巡检指标
cmds_dict = {'cpu_usage':'TIME_INTERVAL=5;LAST_CPU_INFO=$(cat /proc/stat | grep -w cpu | awk \'{print $2,$3,$4,$5,$6,$7,$8}\');LAST_SYS_IDLE=$(echo $LAST_CPU_INFO | awk \'{print $4}\');LAST_TOTAL_CPU_T=$(echo $LAST_CPU_INFO | awk \'{print $1+$2+$3+$4+$5+$6+$7}\');sleep ${TIME_INTERVAL};NEXT_CPU_INFO=$(cat /proc/stat | grep -w cpu | awk \'{print $2,$3,$4,$5,$6,$7,$8}\');NEXT_SYS_IDLE=$(echo $NEXT_CPU_INFO | awk \'{print $4}\');NEXT_TOTAL_CPU_T=$(echo $NEXT_CPU_INFO | awk \'{print $1+$2+$3+$4+$5+$6+$7}\');SYSTEM_IDLE=`echo ${NEXT_SYS_IDLE} ${LAST_SYS_IDLE} | awk \'{print $1-$2}\'`;TOTAL_TIME=`echo ${NEXT_TOTAL_CPU_T} ${LAST_TOTAL_CPU_T} | awk \'{print $1-$2}\'`;CPU_USAGE=`echo ${SYSTEM_IDLE} ${TOTAL_TIME} | awk \'{printf "%.2f", 100-$1/$2*100}\'`;echo ${CPU_USAGE}',
'mem_usage':'MEM_USAGE=`/usr/bin/free | awk \'/Mem/{printf("RAM Usage: %.2f%\\n"), $3/$2*100}\' | awk \'{print $3}\'`;echo ${MEM_USAGE}',
'disk_status':'DISK_STATUS=`df -h | grep "^/dev/vd" | awk \'{printf "diskname: %-10s used: %-5s nouse: %-5s USAGE: %.2f%\\n",$1,$3,$4,$3/$2*100}\'`;echo ${DISK_STATUS}',
'network': 'if ping -c 5 www.baidu.com &>/dev/null;then echo "Network: OK";else echo "Network: NOT OK";fi',
'boot_log': 'B=`cat /var/log/boot.log`;if [ "$B" = "" ];then echo "Bootlog: OK";else echo"Bootlog: NOT OK";fi',
}
if ip == '172.16.1.21':
cmds_dict['mysql'] = 'mysql_pid=`ps -ef | grep mysql | grep -v grep | awk \'{print $2}\'`;if [ "${mysql_pid}" = "" ];then echo "Mysql_service: NOT OK";else echo "Mysql_service: OK! pid is ${mysql_pid}";fi'
elif ip == '172.16.1.22':
cmds_dict['es'] = 'es_pid=`ps -ef | grep elasticsearch | grep -v grep | awk \'{print $2}\'`;if [ "${es_pid}" = "" ];then echo "Es_service: NOT OK";else echo "Es_service: OK pid is ${es_pid}";fi'
elif ip == '172.16.1.23':
cmds_dict['redis_cluster'] = 'NUM=` ps -ef | grep redis | grep -v grep |awk \'{print $2}\' | wc -l`;echo "the running redis-cluster node is $NUM"'
try:
#创建ssh客户端
client = paramiko.SSHClient()
#免密钥登录
private_key = paramiko.RSAKey.from_private_key_file('/home/ssw/.ssh/id_rsa')
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
client.connect(
hostname=ip,
username='ssw',
port=22,
pkey=private_key,
timeout=30
)
#新建一个空字典存储输出结果
result = {}
for k,v in cmds_dict.items():
stdin, stdout, stderr = client.exec_command(v)
if not stderr.read():
result['ip'] = ip
result[k] = stdout.read().decode('utf-8').strip()
else:
pass
except Exception as e:
pprint(ip+" error:"+str(e))
pprint(traceback.format_exc())
finally:
client.close()
return result
if __name__ == '__main__':
ip_list = ['172.16.1.21','172.16.1.22','172.16.1.23']
pool = ThreadPool(8)
ret = pool.map(weekly_check,ip_list)
pool.close()
pool.join()
#结果写入excel
with open('/home/ssw/game_server_%s.xlsx' % datetime.now().__format__('%m-%d'),'w') as f:
f.write(json.dumps(ret))
有些服务器有2块磁盘,有些只有1块,这是执行脚本后输出的部分数据,格式如下:
[{'cpu_usage': '11.67',
'disk_status': 'diskname: /dev/vda1 used: 35G nouse: 59G USAGE: 35.35% '
'diskname: /dev/vdb1 used: 243G nouse: 225G USAGE: 49.29%',
'es': 'Es_service: OK pid is 20488',
'ip': '172.16.1.21',
'mem_usage': '27.13%',
'network': 'Network: OK'},
{'cpu_usage': '3.14',
'disk_status': 'diskname: /dev/vda1 used: 23G nouse: 445G USAGE: 4.67%',
'ip': '172.16.1.22',
'mem_usage': '12.86%',
'network': 'Network: OK',
'rabbitmq': 'Rabbitmq_service: OK pid is 1392'},
]
2. 数据写入mysql(用到pampy)
创建数据库
create table weekly_check
(
id int not null auto_increment,
project varchar(30),
ip varchar(30),
cpu varchar(30),
mem varchar(30),
disk LONGTEXT,
network varchar(60),
vda1 varchar(20),
vdb1 varchar(20),
service LONGTEXT,
create_time timestamp null default current_timestamp,
primary key (id)
);
写入mysql
pampy在这里的作用,主要是找出2块磁盘的使用率,作为数据插入到"vda1","vdb1"字段
import json,pymysql
import re
from pampy import match, HEAD, TAIL, _
#前面巡检的部分数据
data = [{'cpu_usage': '11.67',
'disk_status': 'diskname: /dev/vda1 used: 35G nouse: 59G USAGE: 35.35% '
'diskname: /dev/vdb1 used: 243G nouse: 225G USAGE: 49.29%',
'es': 'Es_service: OK pid is 20488',
'ip': '172.16.1.21',
'mem_usage': '27.13%',
'network': 'Network: OK',
'service': {'boot_log': 'Bootlog: OK',
'front_service': 'Front_service: OK! pid is 16608',
'nodejs_service': 'nodejs_service: NOT OK'}
},
{'cpu_usage': '3.14',
'disk_status': 'diskname: /dev/vda1 used: 23G nouse: 445G USAGE: 4.67%',
'ip': '172.16.1.22',
'mem_usage': '12.86%',
'network': 'Network: OK',
'rabbitmq': 'Rabbitmq_service: OK pid is 1392',
'service': {'mysql': 'mysql: OK'}
}
]
def conn_mysql(sql,value):
dbparam = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '1024',
'database': 'alerts',
'charset': 'utf8'
}
conn = pymysql.connect(**dbparam)
cursor = conn.cursor()
try:
cursor.execute(sql,value)
conn.commit()
except Exception as e:
print('入库失败', e)
conn.rollback()
finally:
cursor.close()
conn.close()
for info in data:
sql = "insert into weekly_check(project,ip,cpu,mem,disk,network,vda1,vdb1,service) values (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
disk_status = info['disk_status']
#多个“服务”用字符串拼接,举个🌰“nginx is ok”和"tomcat is ok"
service = ''
for k,v in info['service'].items():
# 多个“服务”用<br>换行符分割,前端可以识别它进行换行
service = service + v.split('pid')[0].strip() + '<br>'
# 网络连接。主要是为了方便前端显示,如果ok则直接显示“正常”
if info['network'] == 'Network: OK':
info['network'] = '正常'
else:
info['network'] = '异常'
# 磁盘字符串长度大于60说明有2块磁盘
if len(disk_status) > 60:
#取出两块磁盘vda1,vdb1的使用率
re_regular = re.compile('diskname: (/\w+/\w+).*USAGE: (.*)% diskname: (/\w+/\w+).*USAGE: (.*)%')
m = match(disk_status, re_regular, lambda a,b,c,d: b+','+d)
vda1,vdb1 = m.split(',')
disk_status = info['disk_status']
#去掉第一个USAGE
disk_status = re.sub('USAGE: .*% ', '', disk_status)
# 去掉第二个USAGE
disk_status = re.sub(' USAGE: .*%', '', disk_status)
#去掉第一个diskname,第二个diskname替换为换行符<br>
disk_status = disk_status.replace('diskname: ', '', 1).replace(' diskname: ', '<br><br>')
conn_mysql(sql, ('游戏',info['ip'], info['cpu_usage'], info['mem_usage'].strip('%'),\
disk_status,info['network'],vda1,vdb1,service))
else:
#只有一块磁盘vda1
re_regular = re.compile('diskname: (/\w+/\w+).*USAGE: (.*)%')
m = match(disk_status, re_regular, lambda a,b: b)
conn_mysql(sql, ('游戏',info['ip'], info['cpu_usage'], info['mem_usage'].strip('%'), info['disk_status'],info['network'],m,'无',service))
这样数据库就有了巡检数据

vue展示内存百分比
el-progress组件,使用率小于50%显示绿色,50%~75%显示橙色
<span v-if="item.prop === 'mem'"><el-progress :text-inside="true" :stroke-width="13"
:percentage="scope.row[item.prop]" status="success" v-if="scope.row[item.prop] < 50">
</el-progress>
</span>
<span v-if="item.prop === 'mem'"><el-progress :text-inside="true" :stroke-width="13"
:percentage="scope.row[item.prop]" status="warning" v-if="scope.row[item.prop] >= 50 && scope.row[item.prop] < 75">
</el-progress>
</span>
小结
很多模块和工具开箱即用,是节省时间的利器,可以用它搭个便车。
图书推荐:
点击小程序卡片,优惠购买
《硬件十万个为什么(开发流程篇)》内容简介:硬件产品开发是一项复杂的工程,涉及产品定义、成本控制、质量管理、进度管理、研发管理、生产管控、供应链管理和售后服务等多个环节。合理的流程可以化繁为简,提升沟通及合作效率,降低风险,确保项目按计划交付。
本书分为10个章节,分别对硬件产品开发过程中的各个关键环节进行了详细的介绍。每个环节都有相应的模板和说明,并且通过实际案例来说明流程的重要性和使用方法,旨在帮助硬件工程师和初创团队更快地熟悉和掌握开发流程。
留言就赠书:
留言第 8、18、38位可以分别获得赠书一本。
注意:仅限关注本公众号18天及以上且之前未获得过赠书的读者参与。
1、想领取赠书,加我微信,朋友圈不定期送书;
2、想咨询学习,加我微信,每次咨询仅9.9元;
3、更多需求(学习 代码 视频剪辑),都可以加我微信,欢迎咨询。
扫码即可加我微信
分享
收藏
点赞
在看



