
10+小故事揭秘高频「操作系统面试题」

提纲
1、为什么有了进程,还要有线程呢?
进程如果在执行的过程被阻塞,那这个进程将被挂起,这时候进程中有些等待的资源得不到执行:
进程在同一时间只能做一件事儿
2、简单说下你对并发和并行的理解?
并发
在一个时间段中多个程序都启动运行在同一个处理机中
并行
假设目前A,B两个进程,两个进程分别由不同的 CPU 管理执行,两个进程不抢占 CPU 资源且可以同时运行,这叫做并行。


3、同步、异步、阻塞、非阻塞的概念
首先大家应该知道同步异步,阻塞非阻塞是两个不同层面的问题,一个是operation层面,一个是kernal层面。同步异步最大的区别在于是否需要底层的响应再执行。阻塞非阻塞最大的区别在于是否立即给出响应。
小Q去钓鱼,抛完线后就傻傻的看着有没有动静,有则拉杆(同步阻塞)
小Q去钓鱼,拿鱼网捞一下,有没有鱼立即知道,不用等,直接就捞(同步非阻塞)
小Q去钓鱼,这个鱼缸比较牛皮,扔了后自己就打王者荣耀去了,因为鱼上钩了这个鱼缸带的报警器会通知我。这样实现异步(异步非阻塞)
4、进程和线程的相关题
进程:进程是系统进行资源分配和调度的一个独立单位,是系统中的并发执行的单位。
线程:线程是进程的一个实体,也是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,有时又被称为轻量级进程。
进程是资源分配的最小单位,而线程是 ** CPU 调度**的最小单位;
创建进程或撤销进程,系统都要为之分配或回收资源,操作系统开销远大于创建或撤销线程时的开销;
不同进程地址空间相互独立,同一进程内的线程共享同一地址空间。一个进程的线程在另一个进程内是不可见的;
进程间不会相互影响,而一个线程挂掉将可能导致整个进程挂掉;
如果以多进程的方式运行,那么允许多个任务同时运行
如果以多线程的方式运行,那么允许将单个任务分成不同的部分运行
为了防止进程/线程之间产生冲突和允许进程之间的共享资源,需要提供一种协调机制。
多线程与多进程的基本概念
貌似我们一提到高并发,分布式,就不得不想起多线程,那么多线程一定比单线程效率高?
多线程与多进程的应用场景
更加高效的内存共享。多进程下内存共享不便
较轻的上下文切换。因为不用切换地址空间,CR3寄存器和清空TLB
各个进程有自己内存空间,所以具有更强的容错性,不至于一个集成crash导致系统崩溃
具有更好的多核可伸缩性,因为进程将地址空间,页表等进行了隔离,在多核的系统上可伸缩性更强
尽量使用池化技术,也就是线程池,从而不用频繁的创建,销毁线程
减少线程之间的同步和通信
通过Huge Page的方式避免产生大量的缺页异常
避免需要频繁共享写的数据
5、进程的状态转换
可运行状态
英文名词为TASK_RUNNING,其实这个状态虽然是RUNING,实际上并不一定会占有 CPU ,可能修改TASK_RUNABLE会更妥当。TASK_RUNGING根据是否在在 CPU 上运行分为RUNGING和READY两种状态。处于READY状态的进程随时可以运行,只不过因为此时 CPU 资源受限,调度器没选中运行

可中断睡眠状态与不可中断睡眠状态
我们知道进程不可能一直处于可运行的状态。假设A进程需要读取磁盘中的文件,这样的系统调用消耗时间较长,进程需要等待较长的时间才能执行后面的命令,而且等待的时间还是不可估算的,这样的话进程还占用 CPU 就不友好了,因此内核就会将其更改为其他的状态并从 CPU 可运行的队列移除。
等待的事情发生且继续运行的条件满足
收到了没有被屏蔽的信号
处于此状态的进程,收到信号会返回EINTR给用户空间。开发者通过检测返回值的方式进行后续逻辑处理

那么TASK_UNINTERRUPTIBLE状态会出现多久呢?
sysctl kernel.hung_task_timeout_secs
睡眠进程和等待队列
TASK_STOPPED状态于TASK_TRACED状态
TASK_STOPPED状态属于比较特殊的状态,可以通过SIGCONT信号回复进程的执行

TASK_TRACED是被跟踪的状态,进程会停下来等待跟踪它的进程对它进行进一步的操作
EXIT_ZOMBIE状态与EXIT_DEAD状态
当进程储于这两种的任意一种,就可以宣布"死亡" 。

6、进程间的通信方式有哪些?
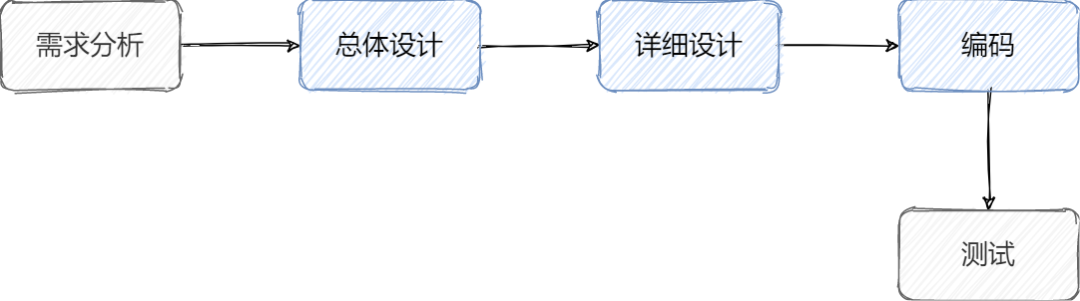
学习软件工程规范的时候,我们知道瀑布模型,在整个项目开发过程分为多个阶段,上一阶段的输出作为下一阶段的输入。各个阶段的具体内容如下图所示
最初我们在学习Linux基本命令使用的时候,我们经常通过多个命令的组合来完成我们的需求。比如说我们想知道如何查看进程或者端口是否在使用,会使用下面的这条命令 netstat -nlp | grep XXX
mkfifo test

echo "666" > test

cat < test
管道通信属于一股脑的输入,能不能稍微温柔点有规矩点的发送消息?
使用消息队列可以达到不错的效果,但是如果我们两个部门需要交换比较大的数据的时候,一发一收还是不能及时的感知数据。能不能更好的办法,双方能很快的分享内容数据,答:有的,共享内存
为了防止冲突,我们得有个约束或者说一种保护机制。使得同一份共享的资源只能一个进程使用,这里就出现了信号量机制。
从管道----消息队列-共享内存/信号量,有需要等待的管道机制,共享内存空间的进程通信方式,还有一种特殊的方式--信号
上面的几种方式都是单机情况下多个进程的通信方式,如果我想和相隔几千里的小姐姐通信怎么办?
分享了一下几种进程间通信方式,希望大家能知其然并知其所以然,机械式的记忆容易忘记哦。
管道
消息队列
共享内存
信号量
信号
套接字
7、进程的调度算法有哪些?
先来先服务调度算法

时间片轮转调度算法
短作业优先调度算法
最短剩余时间优先调度算法
高响应比优先调度算法
优先级调度算法
8、什么是死锁?

斥量 2 ,正在申请互斥量 1 。彼此占有对方正在申请的互斥量,结局就是谁也没办法拿到想要的互斥
量,于是死锁就发生了。


量。还是以刚才的例子为例,如果每个线程都按照先申请互斥量 1 ,再申请互斥量 2 的顺序执行,死锁
就不会发生。有些互斥量有明显的层级关系,但是也有一些互斥量原本就没有特定的层级关系,不过
没有关系,可以人为干预,让所有的线程必须遵循同样的顺序来申请互斥量
9、产生死锁的原因?
竞争资源
可剥夺资源:是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺, CPU 和主存均属于可剥夺性资源;
不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
进程推进顺序不当
10、死锁产生的必要条件?
要求各个资源互斥,如果这些资源都是可以共享的,那么多个进程直接共享即可,不会存在等待的尴尬场景
要求进程所占有的资源使用完后主动释放即可,其他的进程休想抢占这些资源。原因很简单,如果可以抢占,直接拿就好了,不会进入尴尬的等待场景
P1: P2:
request(R1) request(R2)
request(R2) request(R1)
P1: P2:
request(R1) request(R1)
request(R2) request(R2)
循环等待
要求存在一条进程资源的循环等待链,链中的每一个进程占有的资源同时被另一个进程所请求。 发生死锁时一定有循环等待(因为是死锁的必要条件),但是发生循环等待的时候不一定会发生死锁。这是因为,如果循环等待链中的 P1 和 链外的 P6 都占有某个进程 P2 请求的资源,那么 P2 完全可以选择不等待 P1 释放该资源,而是等待 P6 释放资源。这样就不会发生死锁了。
11、解决死锁的基本方法?
如果我们已经知道死锁形成的必要条件,逐一攻破即可。
破坏互斥
通过与锁完全不同的同步方式CAS,CAS提供原子性支持,实现各种无锁的数据结构,不仅可以避免互斥锁带来的开销也可避免死锁问题。
破坏不抢占
如果一个线程已经获取到了一些锁,那么在这个线程释放锁之前这些锁是不会被强制抢占的。但是为了防止死锁的发生,我们可以选择让线程在获取后续的锁失败时主动放弃自己已经持有的锁并在之后重试整个任务,这样其他等待这些锁的线程就可以继续执行了。这样就完美了吗?当然不
破坏环路等待
在实践的过程中,采用破坏环路等待的方式非常常见,这种技术叫做"锁排序"。很好理解,我们假设现在有个数组A,采用单向访问的方式(从前往后),依次访问并加锁,这样一来,线程只会向前单向等待锁释放,自然也就无法形成一个环路了。
12、怎么预防死锁?
13、怎么避免死锁?
银行家算法
安全序列
系统安全状态
14、怎么解除死锁?
资源剥夺:挂起某些死锁进程,并抢占它的资源,将这些资源分配给其他死锁进程(但应该防止被挂起的进程长时间得不到资源);
撤销进程:强制撤销部分、甚至全部死锁进程并剥夺这些进程的资源(撤销的原则可以按进程优先级和撤销进程代价的高低进行);
进程回退:让一个或多个进程回退到足以避免死锁的地步。进程回退时自愿释放资源而不是被剥夺。要求系统保持进程的历史信息,设置还原点。
15、什么是缓冲区溢出?有什么危害?
缓冲区溢出是指当计算机向缓冲区内填充数据时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上
一个两升的杯子,你如果想导入三升,怎么做?其他一生只好流出去,不是打湿了电脑就是那啥。
16、物理地址、逻辑地址、线性地址
物理地址:它是地址转换的最终地址,是内存单元真正的地址。如果采用了分页机制,那么线性地址会通过页目录和页表得方式转换为物理地址。如果没有启用则线性地址即为物理地址
逻辑地址:在编写c语言的时候,通过&操作符可以读取指针变量本省得值,这个值就是逻辑地址。实际上是当前进程得数据段得地址,和真实的物理地址没有关系。只有当在Intel实模式下,逻辑地址==物理地址。我们平时的应用程序都是通过和逻辑地址打交道,至于分页,分段机制对他们而言是透明得。逻辑地址也称作虚拟地址
线性地址:线性地址是逻辑地址到物理地址的中间层。我们编写的代码会存在一个逻辑地址或者是段中得偏移地址,通过相应的计算(加上基地址)生成线性地址。此时如果采用了分页机制,那么吸纳行地址再经过变换即产生物理地址。在Intelk 80386中地址空间容量为4G,各个进程地址空间隔离,意味着每个进程独享4G线性空间。多个进程难免出现进程之间的切换,线性空间随之切换。基于分页机制,对于4GB的线性地址一部分会被映射到物理内存,一部分映射到磁盘作为交换文件,一部分没有映射,通过下面加深一下印象
17、分页与分段的区别?
那么虚拟地址是怎么转换为物理地址的呢?

虚拟地址-----> 页号+偏移量
通过页表查询出虚拟页号,对应的物理页号
物理页号+偏移量-----> 物理内存地址

这样的方法,在32位的内存地址,页表需要多大的空间?

18 为什么使用多级页表
使用多级页表可以让页表在内存中离散存储。多级页表通过索引就可以定位到具体的项。举个例子,假设当前虚拟地址空间为4G,每个页的大小为4k,如果是一级页表的话,共有2……20个页表项,假设每个页表项需要4B,那么存放所有的页表项需要4M,那么为了随机访问,我们就需要连续的4M内存空间存放所有的页表项。这样一来,随着虚拟地址空间的增大,需要存放页表所需的连续空间也就越来多大。如果使用多级页表,我们只需要一页存放目录项,页表存放在内存其他位置即可,下面有例子进一步讲解
使用多级页表更加节省页表内存。理论上,使用一级页表,需要连续存储空间存放所有项。使用多级页表只需要给实际使用的的那些虚拟地址内存的请求分配内存
那使用多级页表有啥缺点?
19、页面置换算法有哪些?
先进先出置换算法(FIFO)
最佳置换算法(OPT)
最近最久未使用(LRU)算法
时钟(Clock)置换算法
20 书籍/视频学习推荐
Linux内核设计与实现
操作系统导论
现代操作系统
深入理解操作系统
B站 ----哈工大李志军老师讲解
https://www.bilibili.com/video/av17036347/
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️