
Pandas数据分析小技巧系列 第三集
三步加星标
你好!我是 zhenguo
今天是 Pandas数据分析小技巧系列 第三集,涉及如何获取数据最多的3个分类,以及如何使用count统计词条出现次数。
前两集在这里:
小技巧 10:如何快速拿到数据最多的 3 个分类?
读入数据:
df = pd.read_csv("IMDB-Movie-Data.csv")
df
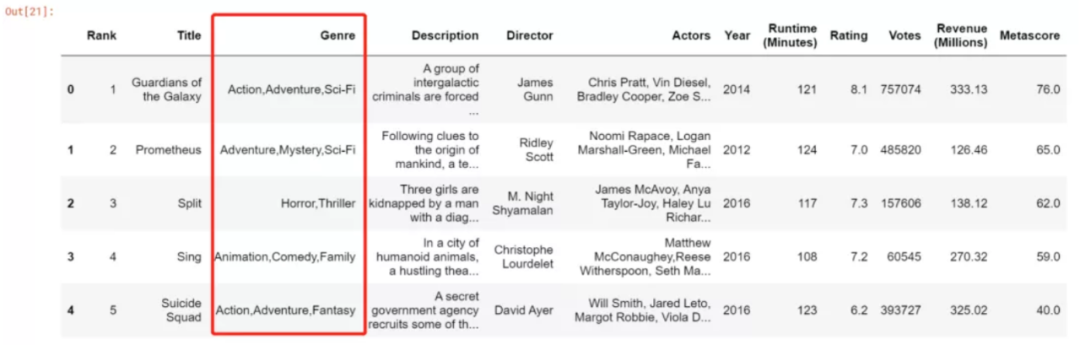
1000 行数据,genre 取值的频次统计如下:
vc = df["genre"].value_counts()
vc
打印结果:
Action,Adventure,Sci-Fi 50
Drama 48
Comedy,Drama,Romance 35
Comedy 32
Drama,Romance 31
..
Adventure,Comedy,Fantasy 1
Biography,History,Thriller 1
Action,Horror 1
Mystery,Thriller,Western 1
Animation,Fantasy 1
Name: genre, Length: 207, dtype: int64
筛选出 top3 的 index:
top_genre = vc[0:3].index
print(top_genre)
打印结果:
Index(['Action,Adventure,Sci-Fi', 'Drama', \
'Comedy,Drama,Romance'], dtype='object')
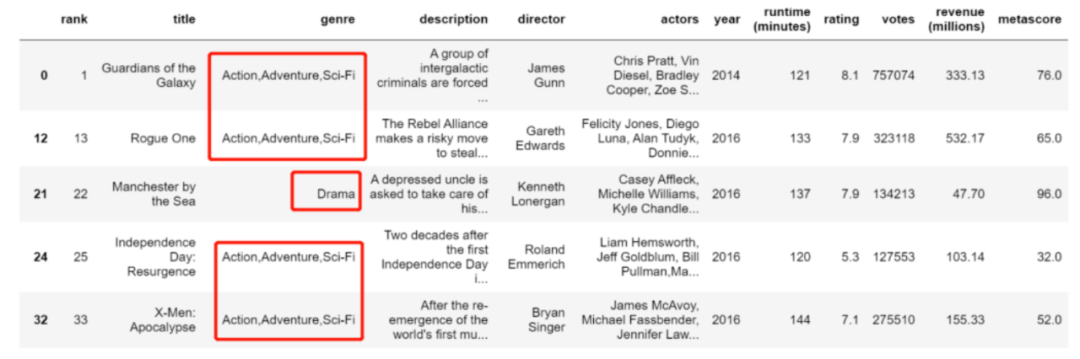
使用得到的 top3 的 index ,结合 isin,选择出相应的 df
df_top = df[df["genre"].isin(top_genre)]
df_top
结果:
小技巧11:如何使用 count 统计词条出现次数?
读入 IMDB-Movie-Data 数据集,1000行数据:
df = pd.read_csv("../input/imdb-data/IMDB-Movie-Data.csv")
df['Title']
打印 Title 列:
0 Guardians of the Galaxy
1 Prometheus
2 Split
3 Sing
4 Suicide Squad
...
995 Secret in Their Eyes
996 Hostel: Part II
997 Step Up 2: The Streets
998 Search Party
999 Nine Lives
Name: Title, Length: 1000, dtype: object
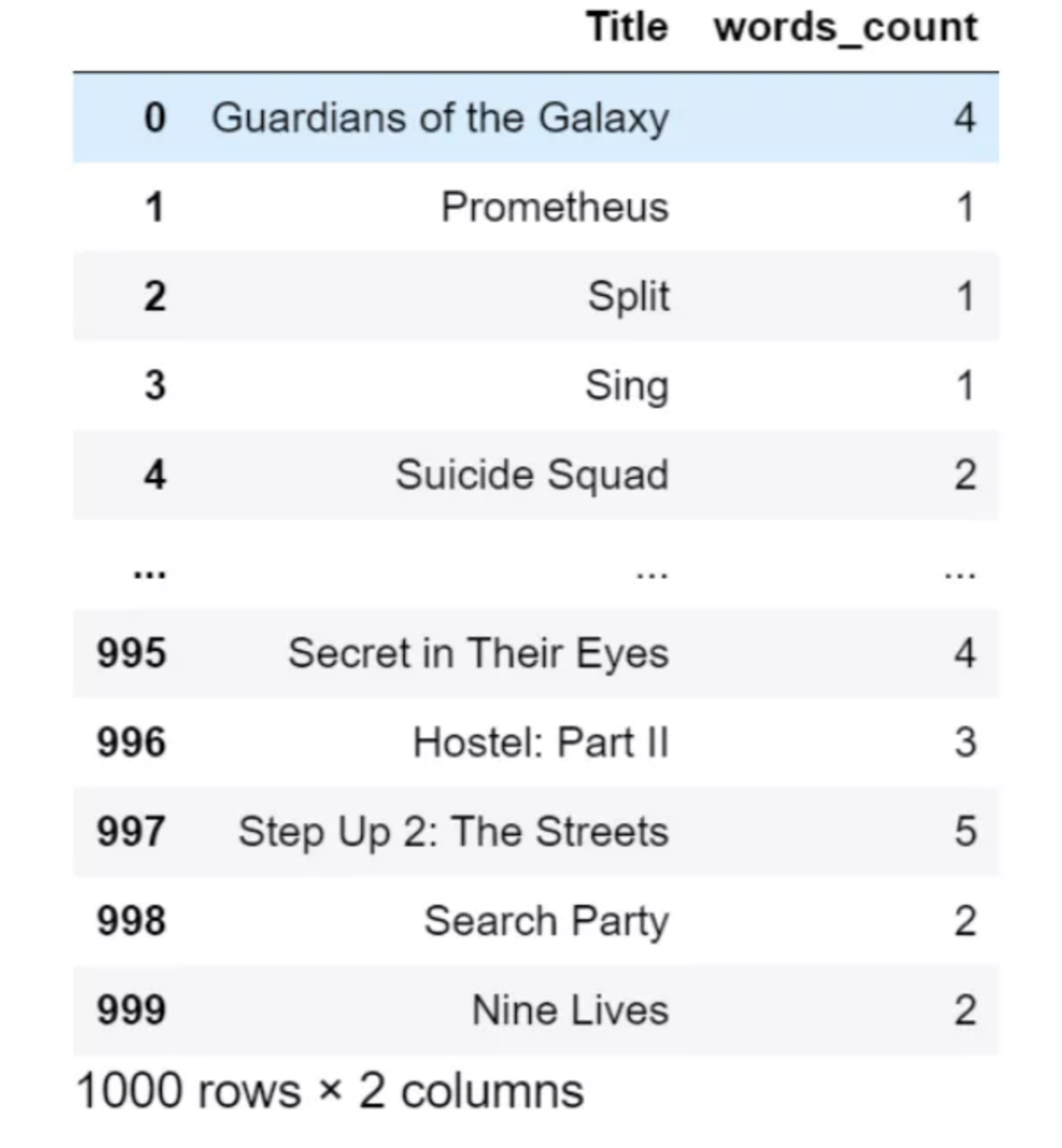
标题是由几个单词组成,用空格分隔。
df["words_count"] = df["Title"].str.count(" ") + 1
df[["Title","words_count"]]
如果你没有 IMDB-Movie-Data 数据集,可以微信联系我下载,备注:电影
评论