
为什么就查了一行数据,执行那么慢?
微信公众号【欢少的成长之路】
今天主要介绍一下查了一行数据,为什么慢到人发慌。剖析一下MySQL的底层运行流程!
案例
登录校验
我不知道大家有没有遇到过这种情况。一个APP客户端在登录用户的时候,明明只查了一条数据,为什么那么慢呢?如何优化这类问题?如何解决这类问题呢?我们接下来分析一下!
分析之前先解决一下预备性问题。如下图,执行了SQL语句,按正常结论的话,应该是扫描全表的数量的。那这里为啥是3行呢?
explain SELECT * FROM `t_vip` where vipIphone='18360520588'

where提取
3行是因为where的缘故。介绍一下where后面SQL的那些事情。
Index Key
用于确定SQL查询在索引中的连续范围(起始范围+结束范围)的查询条件,被称之为Index Key。由于一个范围,至少包含一个起始与一个终止,因此Index Key也被拆分为Index First Key 和 Index Last Key,分别用于定位索引查找的起始,以及索引查询的终止条件。体现在Key Length。

Index First Key
用于确定索引查询的起始范围。
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,
1)若存在并且条件是=、>=,则将对应的条件加入Index First Key之中,继续读取索引的下一个键值,使用同样的提取规则;
2)若存在并且条件是>,则将对应的条件加入Index First Key中,同时终止Index First Key的提取;
3)若不存在,同样终止Index First Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index First Key为(b >= 2, c > 1)。由于c的条件为 >,提取结束,不包括d。
Index Last Key
Index Last Key的功能与Index First Key正好相反,用于确定索引查询的终止范围。
提取规则:从索引的第一个键值开始,检查其在where条件中是否存在,
1)若存在并且条件是=、<=,则将对应条件加入到Index Last Key中,继续提取索引的下一个键值,使用同样的提取规则;
2)若存在并且条件是 < ,则将条件加入到Index Last Key中,同时终止提取;
3)若不存在,同样终止Index Last Key的提取。
针对上面的SQL,应用这个提取规则,提取出来的Index Last Key为(b < 8),由于是 < 符号,因此提取b之后结束。
Index Filter
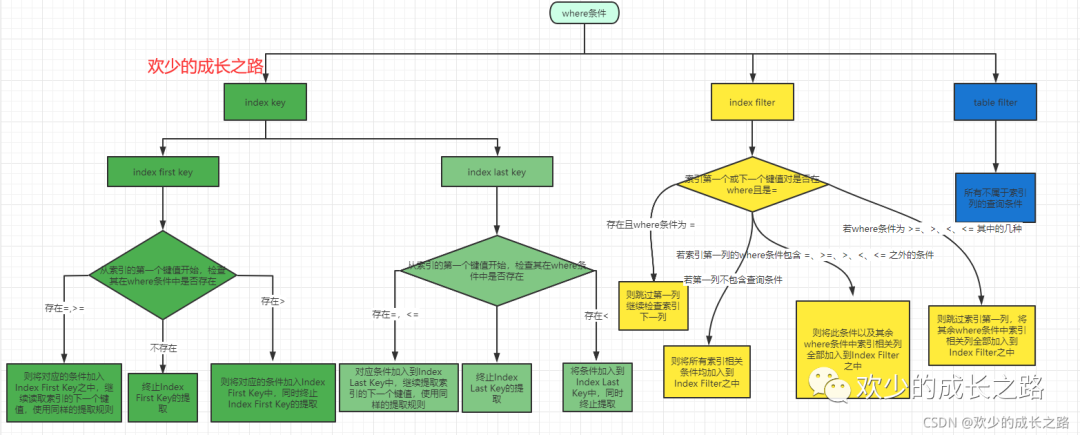
在完成Index Key的提取之后,我们根据where条件固定了索引的查询范围,但是此范围中的项,并不都是满足查询条件的项。在上面的SQL用例中,(3,1,1),(6,4,4)均属于范围中,但是又均不满足SQL的查询条件
Index Filter的提取规则:同样从索引列的第一列开始,检查其在where条件中是否存在
1)若存在并且where条件仅为 =,则跳过第一列继续检查索引下一列,下一索引列采取与索引第一列同样的提取规则;
2)若where条件为 >=、>、<、<= 其中的几种,则跳过索引第一列,将其余where条件中索引相关列全部加入到Index Filter之中;
3)若索引第一列的where条件包含 =、>=、>、<、<= 之外的条件,则将此条件以及其余where条件中索引相关列全部加入到Index Filter之中;
Table Filter
Table Filter是最简单,最易懂,也是提取最为方便的。提取规则:所有不属于索引列的查询条件,均归为Table Filter之中。
同样,针对上面的用例SQL,Table Filter就为 e != ‘a’。
小结
SQL语句中的where条件,使用以上的提取规则,最终都会被提取到Index Key (First Key & Last Key),Index Filter与Table Filter之中。
Index First Key,只是用来定位索引的起始范围,因此只在索引第一次Search Path(沿着索引B+树的根节点一直遍历,到索引正确的叶节点位置)时使用,一次判断即可;
Index Last Key,用来定位索引的终止范围,因此对于起始范围之后读到的每一条索引记录,均需要判断是否已经超过了Index Last Key的范围,若超过,则当前查询结束;
Index Filter,用于过滤索引查询范围中不满足查询条件的记录,因此对于索引范围中的每一条记录,均需要与Index Filter进行对比,若不满足Index Filter则直接丢弃,继续读取索引下一条记录;
Table Filter,则是最后一道where条件的防线,用于过滤通过前面索引的层层考验的记录,此时的记录已经满足了Index First Key与Index Last Key构成的范围,并且满足Index Filter的条件,回表读取了完整的记录,判断完整记录是否满足Table Filter中的查询条件,同样的,若不满足,跳过当前记录,继续读取索引的下一条记录,若满足,则返回记录,此记录满足了where的所有条件,可以返回给前端用户。
在MySQL 5.6之前,并不区分Index Filter与Table Filter,统统将Index First Key与Index Last Key范围内的索引记录,回表读取完整记录,然后返回给MySQL Server层进行过滤。
而在MySQL 5.6之后,Index Filter与Table Filter分离,Index Filter下降到InnoDB的索引层面进行过滤,减少了回表与返回MySQL Server层的记录交互开销,提高了SQL的执行效率
回到案例
介绍了大概where的提取规则,我们再回到案例的SQL进行验证。
一目了然可以发现where条件使用到了 vipIphone 字段。根据提取规则。这个是命中了index first key。
查询时间长
如果说一条SQL查询时间过于长的话就说明肯定是出现问题了。当我们执行explain的时候,也同样的命中了索引。执行时间也是很正常化 十几毫秒。那么为什有时那么慢?
一般第一种情况就是表被锁住了。排查思路就是先执行以下SQL看看当前语句处于什么状态。然后我们再针对每种状态,去分析它们产生的原因、如何复现,以及如何处理。
show processlist
等MDL锁
返回结果Waiting for table metadata lock。这个状态就表示现在有一个线程正在表请求或者持有 MDL 写锁,把 select 语句堵住了。下面我们复现以下
sessionA先对表t加了一个写锁。sessionB要准备执行对表t的读取操作。读取一个表是需要获取MDL读锁的。这样为了防止脏读。所以发现了锁等待现象。
唯一的解决方案就是把这个写锁释放掉。通过kill命令干掉写锁。这样读锁就恢复了。
等flush
另一个情况就是返回结果为Waiting for table flush。根据这个返回结果介绍两个关于flush的指令
flush tables t with read lock; -- flush表t
flush tables with read lock; -- flush所有表
这个结果就表示,在查询的时候刚好被MySQL的内部机制刷数据页碰撞了。但是这两个语句执行都是比较快的,应该不会阻塞查询那么长时间啊。唯一的可能就是一个修改的语句被flush阻塞了。刚好这个查询语句又被修改阻塞了。现在我们复现一下过程。
sessionA开始一个对表的睡眠操作。参数为秒级。因为这里是全表扫描。表里有10万数据。所以大概要睡眠10万秒
sessionB开启一个flush表B的操作。flush之前要对表t进行关闭。而表t又在sessionA中睡眠。session就被sessionA堵住了。
sessionC开始执行查询的操作。sessionA没有执行完毕,sessionB又被sessionA堵住了。sessionC在执行的时候又被sessionB堵住了。
等行锁
上文中,MDL读写锁已经描述完了。这里就介绍已经进来的场景。现在正在处理行锁。
执行如下SQL,我先说一下当初我学习的疑点。lock in share mode 这个是共享锁的意思。具体介绍在扩展中
select * from t where id=1 lock in share mode;
由于要访问id=1这条数据时要加读锁,如果在这之前这条记录上已经持有一个写锁,那么我们的select语句将被堵塞。我们复现一下过程。

sessionA开启一个事务还没有提交。sessionB便开始查询并且加读锁。导致 session B 被堵住。
扩展
提到了lock in share mode 我们可以扩展聊一聊for update 排他锁,就是行锁
for update:如果事务对数据加上排他锁之后,则其他事务不能对该数据加任何的锁。获取排他锁的事务既能读取数据,也能修改数据。
lock in share mode:如果事务对某行数据加上共享锁之后,可进行读写操作;其他事务可以对该数据加共享锁,但不能加排他锁,且只能读数据,不能修改数据。某个事物想进行修改数据操作,那他必须等其他事物的共享锁都释放完毕才能进行修改操作
注:普通 select 语句默认不加锁,而CUD操作默认加排他锁。
查询慢
首先举一个例子
mysql> select * from t where c=50000 limit 1;
由于字段 c 上没有索引,这个语句只能走 id 主键顺序扫描,因此需要扫描 5 万行。用时大概11.5毫秒。你可能会说,不是很慢呀,11.5 毫秒就返回了,我们线上一般都配置超过 1 秒才算慢查询。但你要记住:坏查询不一定是慢查询。我们这个例子里面只有 10 万行记录,数据量大起来的话,执行时间就线性涨上去了。
下面看一下只扫描1行数据就用时就非常大的例子。
select * from t where id=1;
是不是有点奇怪呢,我们可以查一下show log的信息

我们再看一个图对比一下

第二个图是需要加锁的。时间应该更长才对啊。以上两张图是借助丁奇老师的。文章是总结学习扩展的。
我们把上述结果继续复现一下。

sessionA开启一个事务,并且查询
id=1这条记录,并且查询id=1并且加读锁查询。sessionB在sessionA开启一个事务之后执行更新操作
我来解读一下。sessionA中的两个查询是不一样的。第一个是一致性读,第二个是当前读。所以第二个是非常快的,直接通过B+树找到对应的节点数据。而第一个的内部流程是1000001 开始,依次执行 undo log,执行了 100 万次以后,才将 1 这个结果返回。
总结
今天主要介绍了几种常见的查询慢的原因。以及一开始介绍了where条件后面的 index key机制问题。如果有不懂的地方可以微信关注【欢少的成长之路】我们一起交流探讨一下。
有些不懂的地方,可以留言评论