
用 Python 分析全球最美Top100女神
一、前言
前一段时间,国外媒体 TOP BEAUTY WORLD 评选了全球最帅男性和最美女性Top100,肖战成为了该排行榜历届以来首位登顶的亚洲人。这一消息立刻成为了流量的热点。
想看一下榜单中的最美小姐姐的信息。可是现在还没有最美小姐姐的文字榜单信息。但网站里有上一届的全球最美女性前一百名的榜单数据,包含了姓名、地区和职业等信息。
 全球最美 Top100 女神榜单数据,怎能不获取下来好好探究一波?下面我们利用 Python 爬虫将榜单数据获取下来,并进行数据可视化。
全球最美 Top100 女神榜单数据,怎能不获取下来好好探究一波?下面我们利用 Python 爬虫将榜单数据获取下来,并进行数据可视化。
二、爬取数据
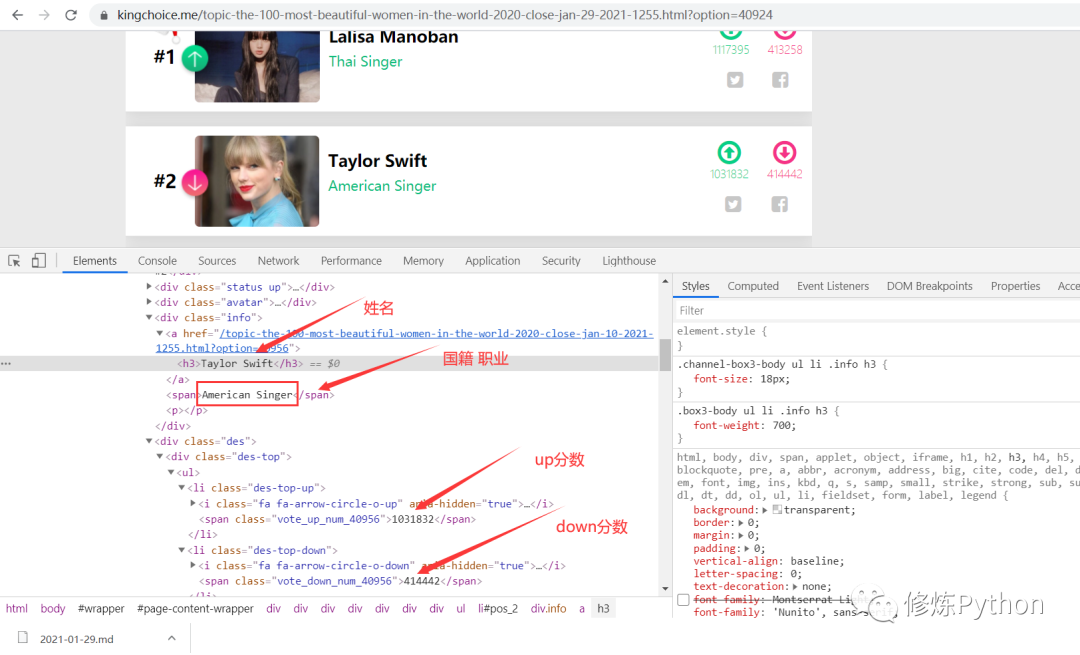 首先,我们想要获取到的数据,包括小姐姐的姓名、地区、职业等信息。检查发现网页属于静态网页,因此可以直接分析网页源代码,提取出我们想要的数据。
首先,我们想要获取到的数据,包括小姐姐的姓名、地区、职业等信息。检查发现网页属于静态网页,因此可以直接分析网页源代码,提取出我们想要的数据。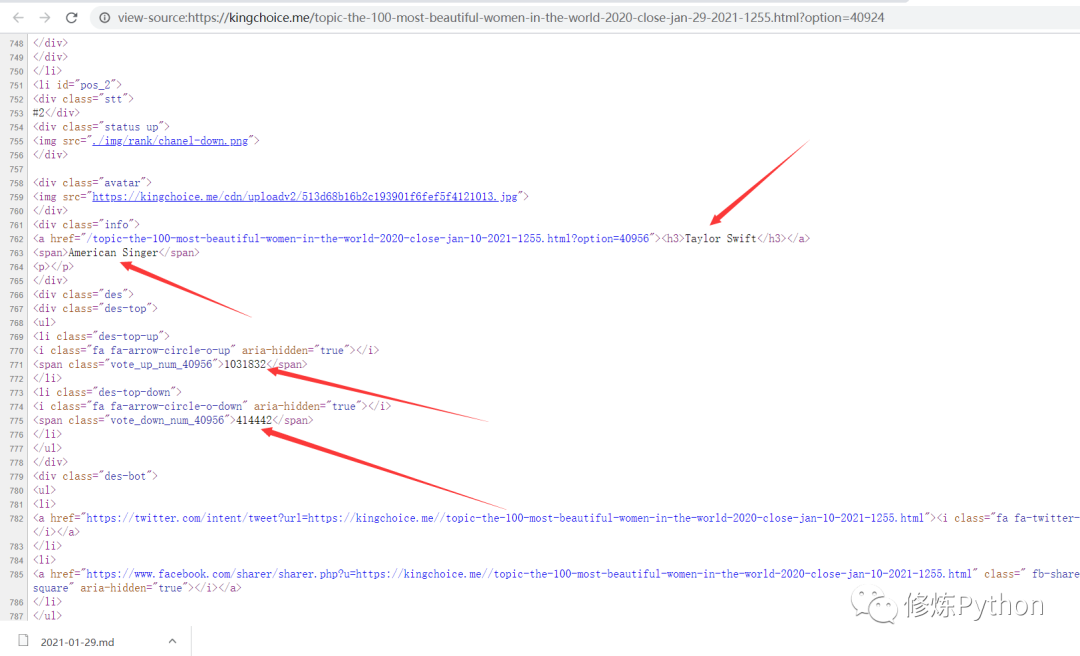
Python代码如下:
# -*- coding: UTF-8 -*-
"""
@File :spider.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
from lxml import etree
import logging
from fake_useragent import UserAgent
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['ranking', 'name', 'country', 'occupation', 'up_score', 'down_score'])
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
headers = {
"accept-encoding": "gzip",
"upgrade-insecure-requests": "1",
"user-agent": ua.random,
}
url = "https://kingchoice.me/topic-the-100-most-beautiful-women-in-the-world-2020-close-jan-29-2021-1255.html?option=40924"
response = requests.get(url, headers=headers)
# print(response.status_code)
# print(response.text)
html = etree.HTML(response.text)
lis = html.xpath('//div[@class="channel-box3-body box3-body"]/ul/li')
logging.info(len(lis)) # 100条信息
for index_, li in enumerate(lis, start=1):
src = li.xpath('.//div[@class="avatar"]/img/@src')[0] # 图片
name = li.xpath('.//div[@class="info"]/a/h3/text()')[0] # 姓名
country, occupation = li.xpath('.//div[@class="info"]/span/text()')[0].split(' ', 1) # 地区 职业
up_score = li.xpath('.//div[@class="des"]/div[1]/ul/li[1]/span/text()')[0] # up分数
down_score = li.xpath('.//div[@class="des"]/div[1]/ul/li[2]/span/text()')[0] # down分数
img = requests.get(src, headers=headers).content
with open(r'.\Top100_beauty_img\{}.jpg'.format(name), 'wb') as f:
f.write(img)
sheet.append([index_, name, country, occupation, up_score, down_score])
logging.info([index_, name, country, occupation, up_score, down_score])
logging.info('已保存{}的信息'.format(name))
wb.save(filename='datas.xlsx')
结果如下:

三、数据可视化
先来看看全球最美 Top100 女神得分情况
# -*- coding: UTF-8 -*-
"""
@File :得分.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Line
from pyecharts.datasets import register_files
from pyecharts.globals import CurrentConfig
# 导入自定义的主题 可自己定制 也可以就用pyecharts官方的几种
register_files({"myTheme": ["themes/myTheme", "js"]})
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_excel('datas.xlsx')
up_score = list(df['up_score'])
down_score = list(df['down_score'])
x_data = [i for i in range(1, 101)]
c = (
Line(init_opts=opts.InitOpts(theme='myTheme'))
.add_xaxis(xaxis_data=x_data)
.set_colors(['#7FFF00', 'red']) # 设置两条折线图的颜色
.add_yaxis('up_score', y_axis=up_score,
label_opts=opts.LabelOpts(is_show=False)
)
.add_yaxis('down_socre', y_axis=down_score,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts( # 设置x轴 y轴标签
xaxis_opts=opts.AxisOpts(name='排名'),
yaxis_opts=opts.AxisOpts(name='得分'),
title_opts=opts.TitleOpts('得分情况')
)
.render('得分.html')
)
结果如下: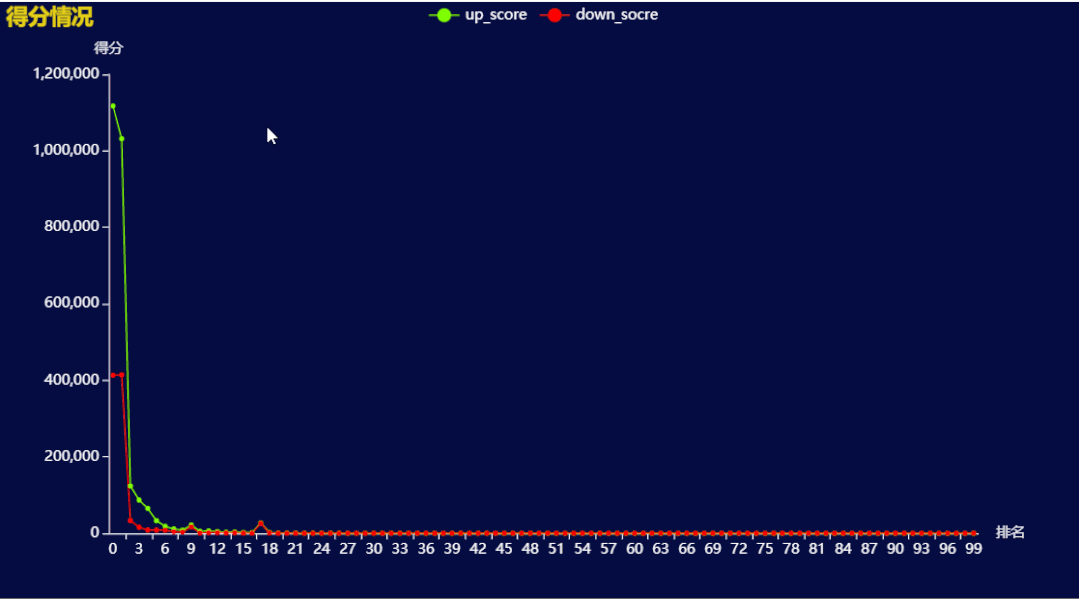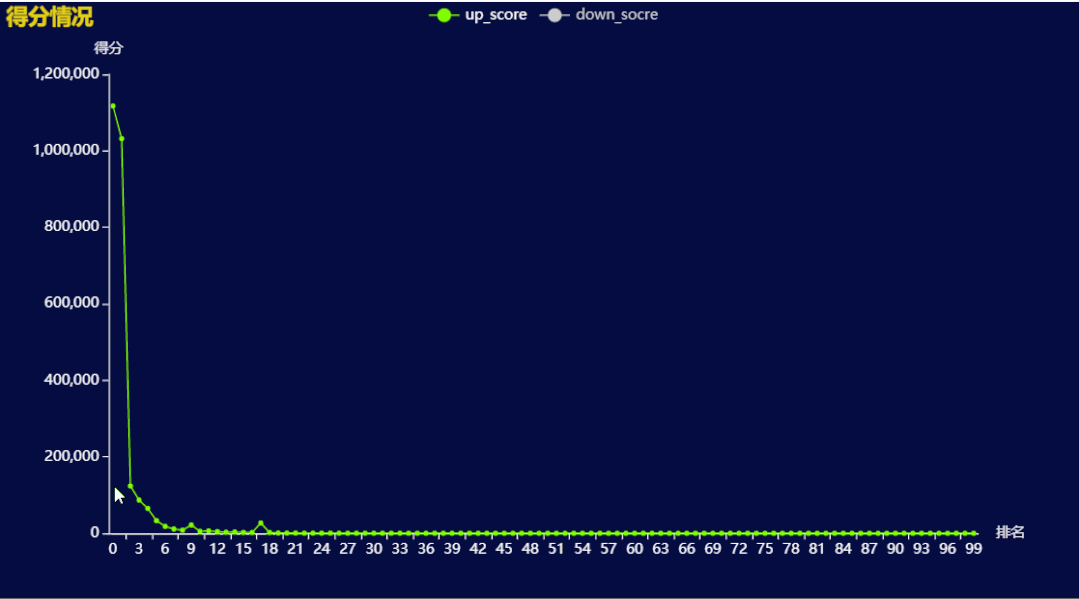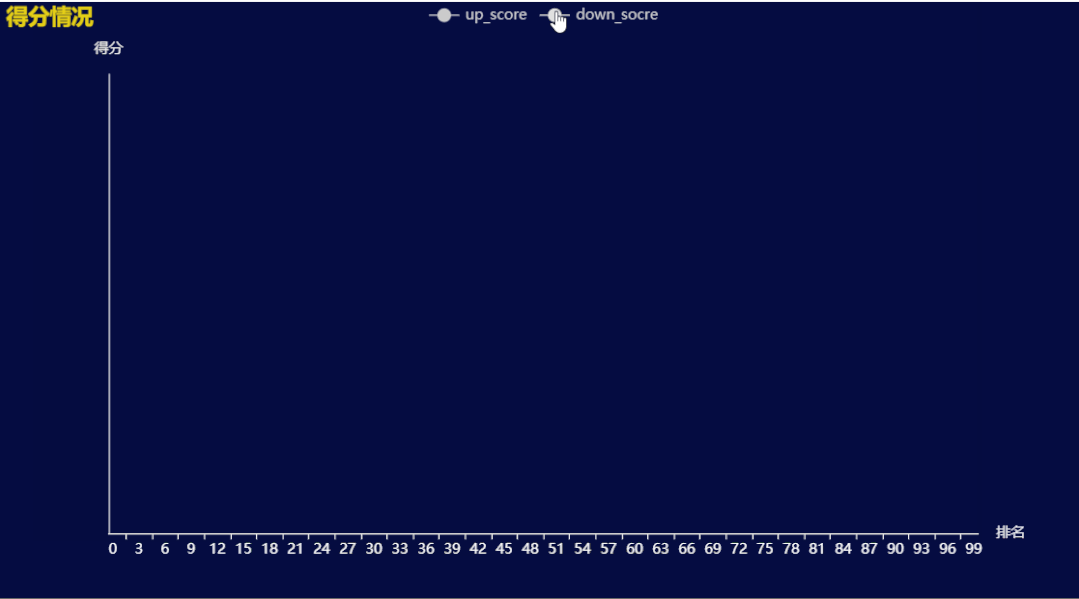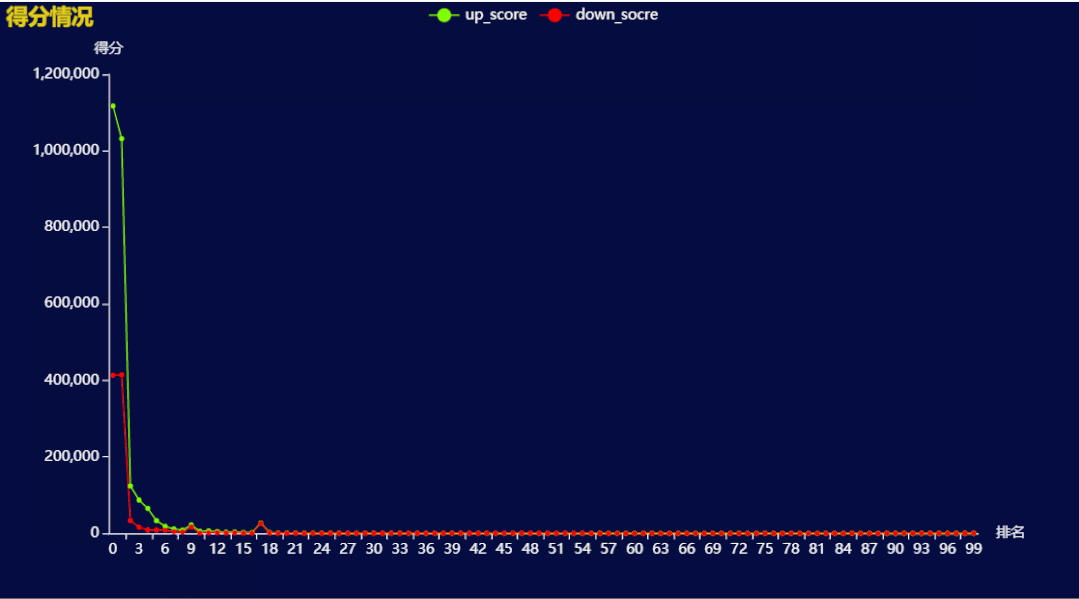 排第一、第二的 Lalisa Manoban 和 Taylor Swift 得分远远高于之后的美女。
排第一、第二的 Lalisa Manoban 和 Taylor Swift 得分远远高于之后的美女。
Top100 美女地区分布
# -*- coding: UTF-8 -*-
"""
@File :女神地区.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from collections import Counter
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType, CurrentConfig
import random
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_excel('datas.xlsx')
areas = df['country']
area_list = []
for item in areas:
if '-' in item:
item = item.split('-')
for i in item:
area_list.append(i)
else:
area_list.append(item)
area_count = Counter(area_list).most_common(10)
print(area_count)
area = [x[0] for x in area_count]
nums = [y[1] for y in area_count]
# 使用风格
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
colors = ['red', '#0000CD', '#000000', '#008000', '#FF1493', '#FFD700', '#FF4500', '#00FA9A', '#191970', '#9932CC']
random.shuffle(colors)
# 配置y轴数据 Baritem
y = []
for i in range(10):
y.append(
opts.BarItem(
name=area[i],
value=nums[i],
itemstyle_opts=opts.ItemStyleOpts(color=colors[i]) # 设置每根柱子的颜色
)
)
bar.add_xaxis(xaxis_data=area)
bar.add_yaxis("上榜美女数", y)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(
name='国家',
axislabel_opts=opts.LabelOpts(rotate=45)
),
yaxis_opts=opts.AxisOpts(
name='上榜美女数', min_=0, max_=55, # y轴刻度的最小值 最大值
),
title_opts=opts.TitleOpts(
title="各地区上榜美女数",
title_textstyle_opts=opts.TextStyleOpts(
font_family="KaiTi", font_size=25, color="black"
)
))
# 标记最大值 最小值 平均值 标记平均线
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值")]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值")]))
bar.render("女神地区分布.html")
结果如下: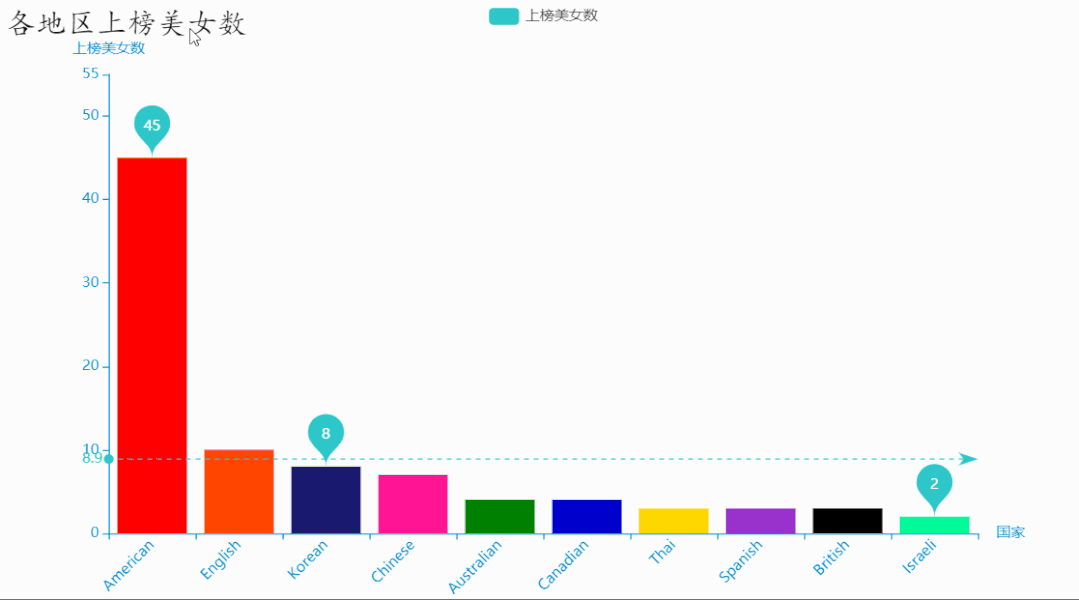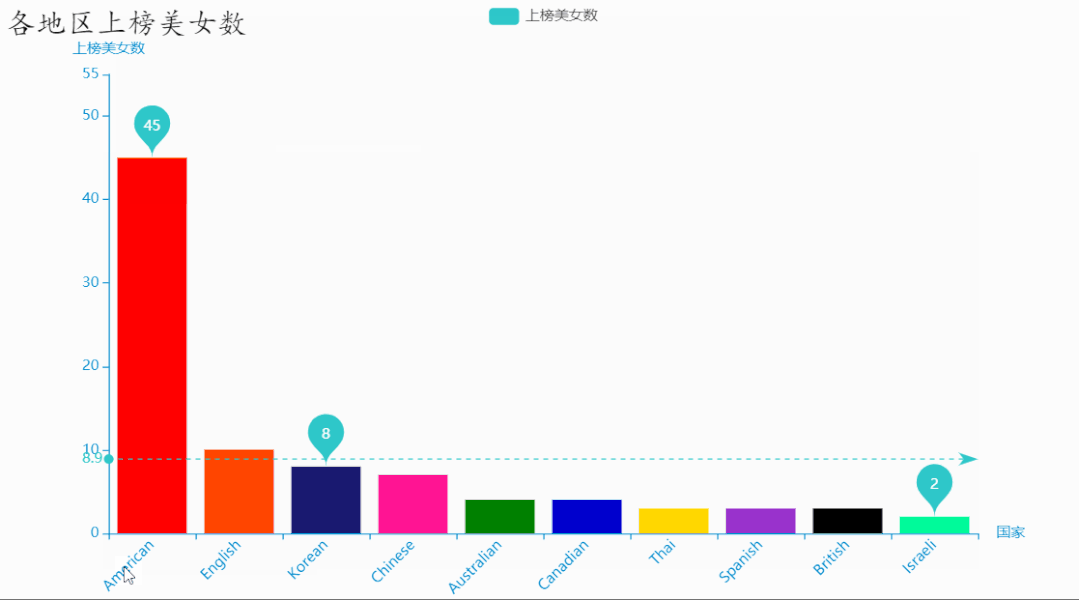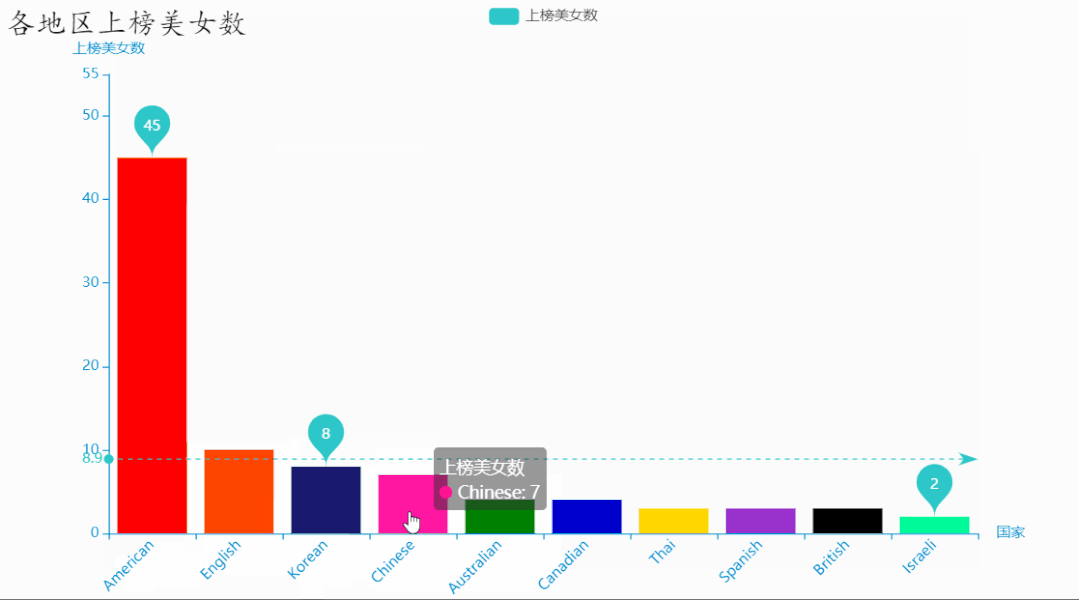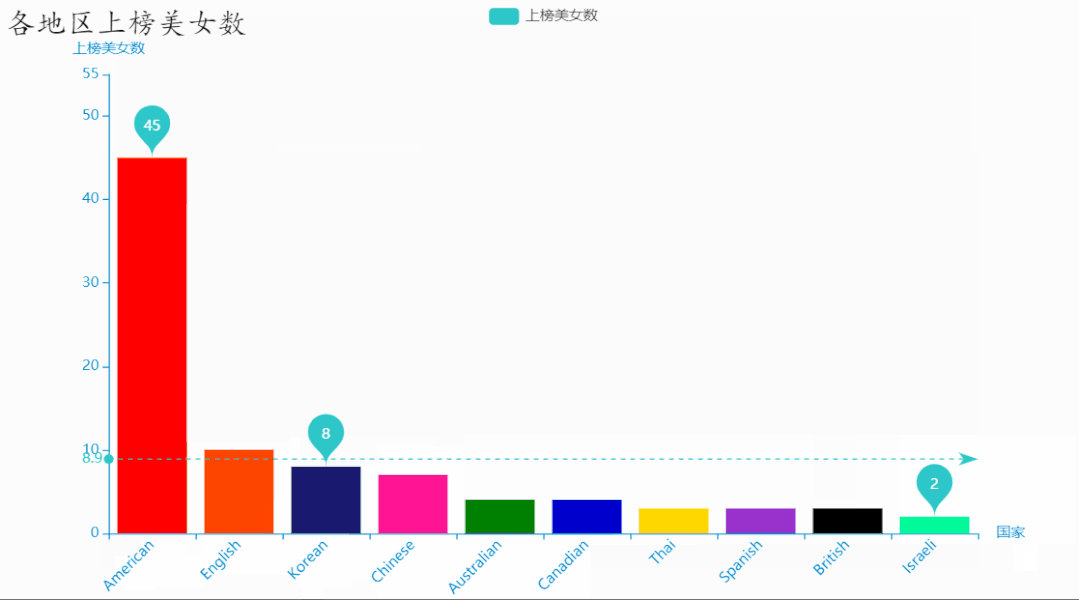 可以看到,英美地区的美女上榜人数最多,占了一半多,其次是韩国、中国的美女。
可以看到,英美地区的美女上榜人数最多,占了一半多,其次是韩国、中国的美女。
import pandas as pd
df = pd.read_excel('datas.xlsx')
data = df[df['country'].str.contains('Chinese')]
data.to_excel('test.xlsx', index=False)

发现国内上榜的美女,职业均是演员。
import pandas as pd
df = pd.read_excel('datas.xlsx')
data = df['occupation'].value_counts()
print(data)
Actress 69
Singer 18
Model 10
Atress 1
model 1
TV Actress 1
Name: occupation, dtype: int64
Process finished with exit code 0


再检查了网站里数据发现,有个别数据美女职业是模特,其他都是Model,就这一个写为model,还有某一个Actress拼写错误,弄成了Atress。还有一个的职业是 TV Actress,也将她归入演员 Actress 内。数据量少,我们直接在表格中找到,将其更改。
# -*- coding: UTF-8 -*-
"""
@File :职业分布.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
from collections import Counter
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
# 引用本地js资源渲染
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_excel('datas.xlsx')
data = list(df['occupation'])
job_count = Counter(data).most_common()
pie = Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
# 富文本效果 环图
pie.add('职业', data_pair=job_count, radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),)
pie.set_global_opts(title_opts=opts.TitleOpts(title='职业占比'))
pie.set_colors(['red', 'orange', 'purple']) # 设置颜色
pie.render('美女职业分布.html')
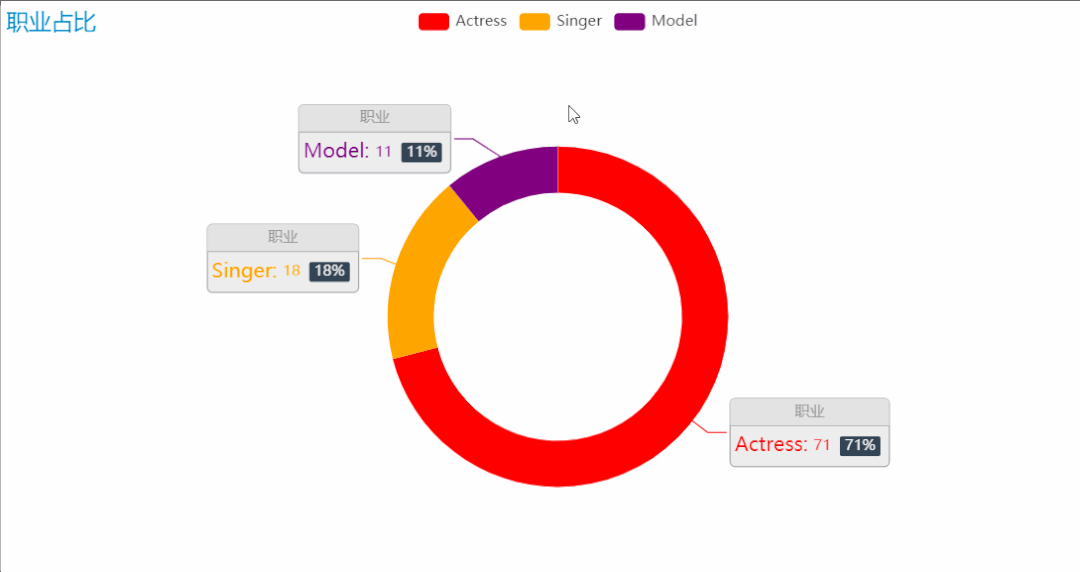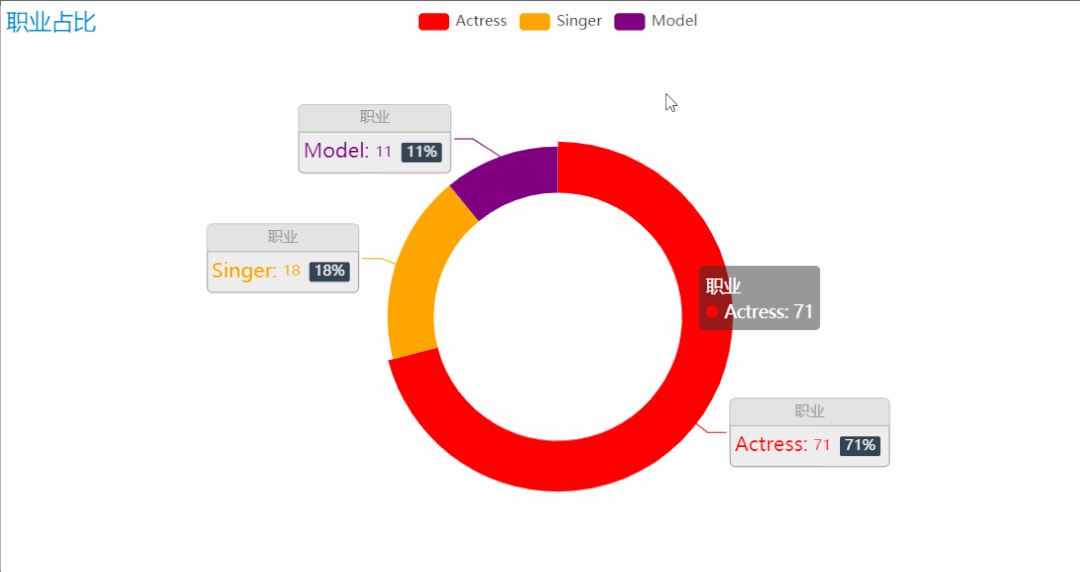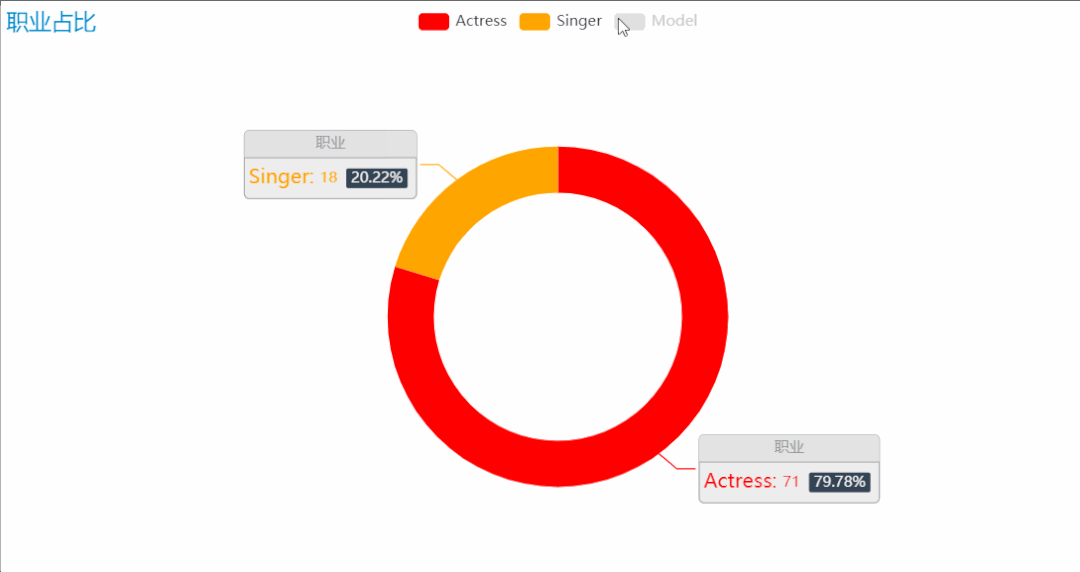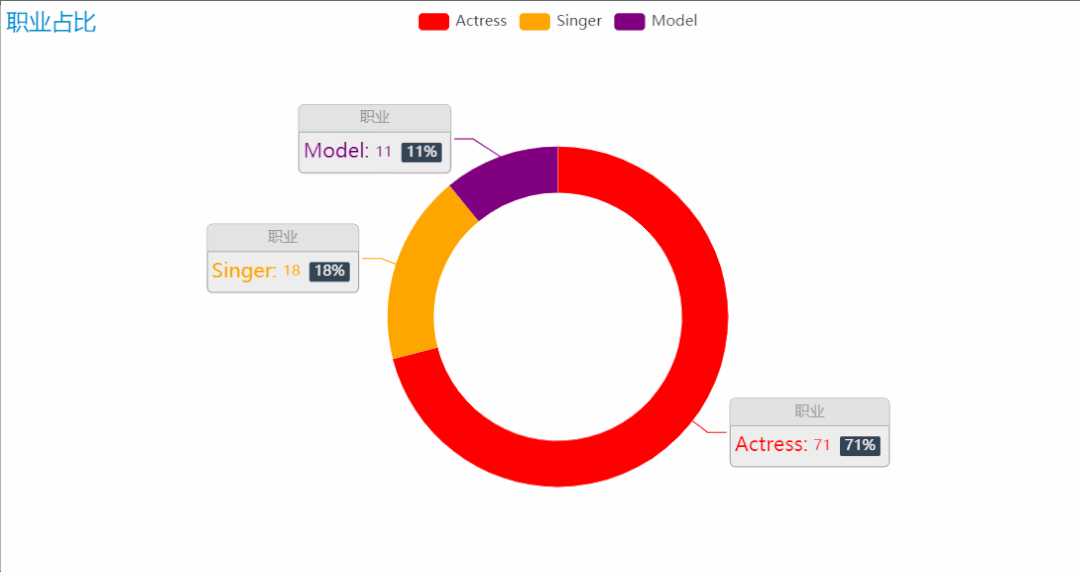
榜单中美女们的职业,主要有三种:演员、模特、歌手。这些职业都对各方面都有一定要求,才能发展得好。职业的占比中,可以看到演员的占比是最高的,因为颜值是一个演员重要的名片,特别是如今这样一个看颜值的时代,也是打分成绩中占比最高的一项,因此在榜单中,演员占比最高也就不足为奇了。
作者:叶庭云
CSDN:https://yetingyun.blog.csdn.net/热爱可抵岁月漫长,发现求知的乐趣,在不断总结和学习中进步,与诸君共勉。
更多阅读
特别推荐

点击下方阅读原文加入社区会员