
自动路损检测器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

城市道路鸟瞰图
1 介绍
损坏的道路对市民的出行有一定的影响。对市政府来说,检测和确定要修复的道路是一项巨大挑战。在美国,大多数州仅仅采用半自动方法进行道路损坏的检测,而在世界其它地区这个过程则完全是人工检测。由于必须保证路况数据是最新的,所以必须以较高的频率检测道路,这使得收集数据的过程既昂贵又费时。这就引出了一个问题:计算机视觉可以提供帮助吗?
通过Lab1886一起提供数据,让我们一起探索以下问题的答案:
(1)是否可以利用汽车仪表板上智能手机拍摄的原始视频片段来自动检测道路是否损坏以及损坏程度?
(2)需要克服哪些技术挑战?
本文将要介绍如何解决自动路损检测任务,重点介绍遇到的一些问题。
2 目前的技术水平

图1:现有论文中关于道路损坏检测的示例图像
在深入研究之前,我们对当前的技术水平进行了调查,找出其他人已经完成的工作。从文献综述中,我们发现路损检测的方法大致可以分为以下几类
•3D分析:使用立体图像或LIDAR点云来检测人行道中的异常情况。
•基于振动的分析:充分利用车载加速度计或陀螺仪。
•基于视觉的分析:从传统技术(如边缘检测和光谱分割)到通过卷积神经网络(CNN)进行的表征学习和分割。
方法:由于我们的主要任务本质上是视觉,并且我们无法访问LIDAR或振动数据,因此我们选择专注于基于视觉的算法,特别是有监督的学习方法。
数据:之前的相关研究主要依赖于特写图像或与路面正交的图像,但这些图像与安装在仪表板上的摄像机传输的图像明显不同,因此不能使用这些数据训练或校准。
3 我们的数据
数据集:安装在汽车上的照相机收集的数据集。整个数据集包含约27000张德国道路的图像,这些图像是在晴天和干燥条件下进行40次不同行驶拍摄到的。图像中道路类型变化很大:有些是带有建筑物环境的多车道城市道路,有些是没有道路标记或建筑物的乡村道路,路面也各不相同(混凝土、沥青、鹅卵石)。图像以大约每秒1张的方式拍摄。

图2:来自Lab1886提供的数据集中的示例图像。
4 数据标注的困难
因为数据集缺少标签,因此我们需要一种方法解析每张图像,针对每种类型的道路损坏对相关像素进行细分,并为像素标注相应损坏严重性类别的标签。手动标注是一项艰巨的任务,因此我们使用几种简化标注的方式:
(1)缩小工作范围(仅考虑油漆损坏):由于道路损坏的形式多种多样(例如鳄鱼皮裂缝、纵向裂缝、坑洼、斑块、油漆),我们选择缩小工作范围,仅考虑油漆损坏。这不仅可以使数据标注更容易,还可以为以后识别其他类型道路损坏提供参考。
(2)尝试使用预先训练的分类模型筛选出没有油漆损坏的图像:我们从Maeda那里得到两个经过预先训练的分类模型,这些分类器在10000幅以上的图像上进行了训练,使用边界框来识别8种不同类型的道路损坏(包括磨损的油漆线)。这些模型对我们数据集的泛化效果很差。通过如下‘小提琴图’可以看到无论是否存在油漆损坏,模型预测的分布几乎相同。
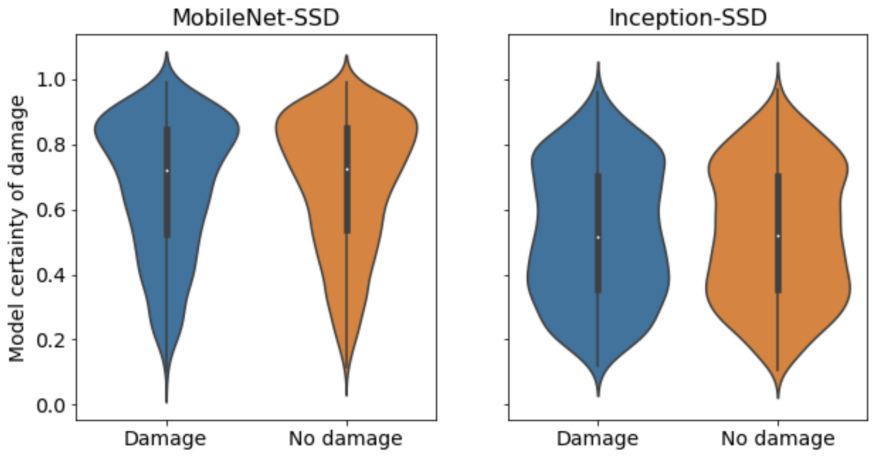
图3:Maeda等人模型的小提琴图, MobileNet-SSD和Inception-SSD。这些图表明,任何参数调整都不可以帮助模型区分是否存在油漆损坏。
(3)尝试使用Mechanical Turk(MTurk)众包注释,这是Amazon提供的一项服务,参与者可以执行简单的任务来换取金钱。我们的任务:通过从下拉菜单中选择相应的严重性标签来标注图像中的油漆损坏。我们选择以下简单的严重等级:
•1-轻度损坏
•2-中等/中度损害
•3-严重损坏
图4为 MTurk标注界面的示例。我们用200张图像进行了一些试验性实验,每次修改指令用来纠正先前实验中观察到的不良结果,我们至少有三名工作人员在每个图像上标注。

图4:MTurk批注界面的示例。
即使进行三次实验迭代,工作人员仍在注释内容和注释方法上存在分歧。我们使用交并比(IoU)量化了同一张图片中不同标注者之间的协议分数,根据协议分布,大多数标签的注释完全没有重叠(如图5),表明对于非专家而言,标注涂料损坏是一项困难任务。
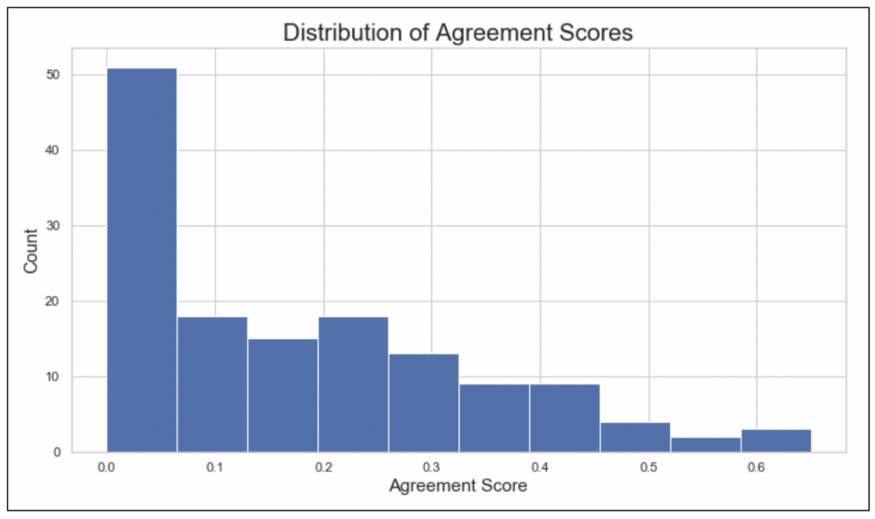
图5:通过MTurk标注的图像的标注协议得分的分布。这显示了标记任务的高度主观性以及为什么众包困难。
结果:最终选择自己标记数据。总共对1357张图像进行了标注,其中每个严重程度至少包含300个实例。
5 模型
从根本上讲,我们的任务解决两个问题:
•损坏在哪里?
•损坏有多糟?
解决问题的方法:
方法一、使用两个不同的模型(分割和分类)分别解决每个问题(多阶段)
1.分割模型:识别输入图像中存在油漆损坏的区域。尝试了一些传统的计算机视觉技术(阈值化、分水岭分割和简单线性交互式聚类(SLIC)),来了解它们是否可以充分‘掩盖’油漆,所有这些传统方法都需要手动调整大量的超参数,并且无法在多个图像上进行概括。(图6传统分割算法的结果)最终,我们使用流行的卷积编码-解码器网络U-Net来执行单通道语义分割。模型的输出是每个像素是否代表油漆损坏的预测概率。

图6:在我们数据集中的单个图像上运行三种传统图像分割算法的结果。
2.分类模型:从理论上讲,对预测进行阈值处理来生成可从输入图像中找出受损区域的掩码(图像分割),然后将其输入分类器以预测损坏严重性。但在实践中,使用真实(像素级)标注的图片作为分类模型的输入,从而能够找到分割模型表现不佳的可能性,这样我们能够分别评估分割模型和分类模型。我们使用的分类器是基于ResNet18架构的CNN。

图7:左:原始图像。中/右:传递到我们分类器模型的相应掩码输入。
3.评估:在占总图像15%的测试集上评估每个模型。单类语义分割模型,(示例输出如图7),与传统的计算机视觉方法相比,该模型学会了分割画线(图8)。然而像素级精度和召回率曲线(图9)表明,该模型倾向于高估涂料损坏的存在。
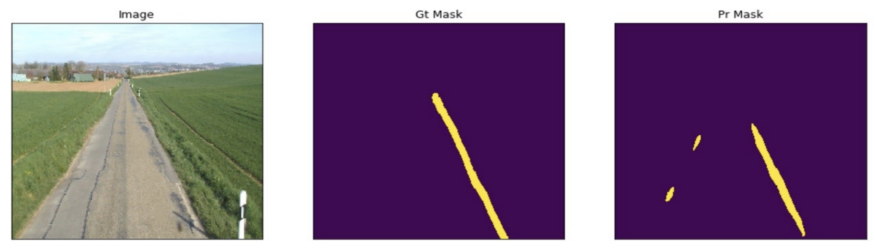
图8:左:原始图像。中:地面真相面具。右:单通道细分模型的阈值输出。
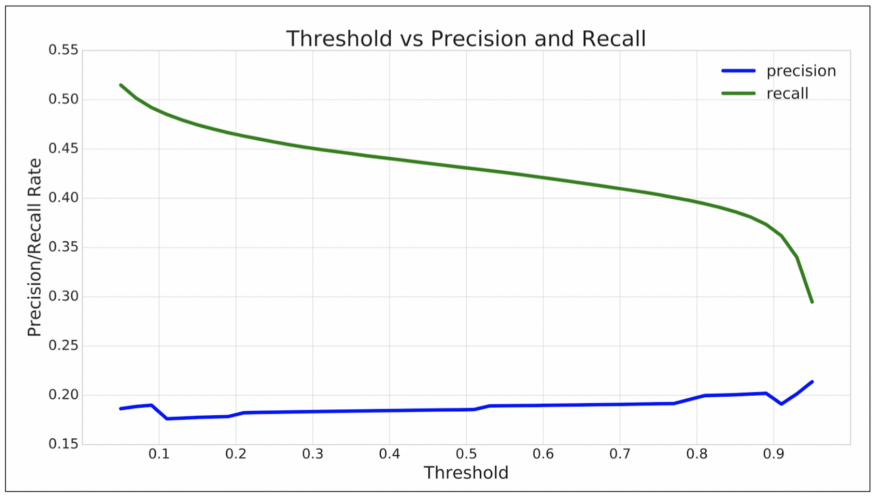
图9:单通道分割模型的像素级精度和召回率与概率阈值的关系。随着阈值的提高,该模型预测的损坏将减少。
损坏程度分类模型,能够在一定程度上区分高度损害与低度损害,但很难从中等/中度损害中区分低度损害(见图10)。这是表明标记的低度和中度损坏实例彼此太相似,分类模型对两者都做出了相似的预测。
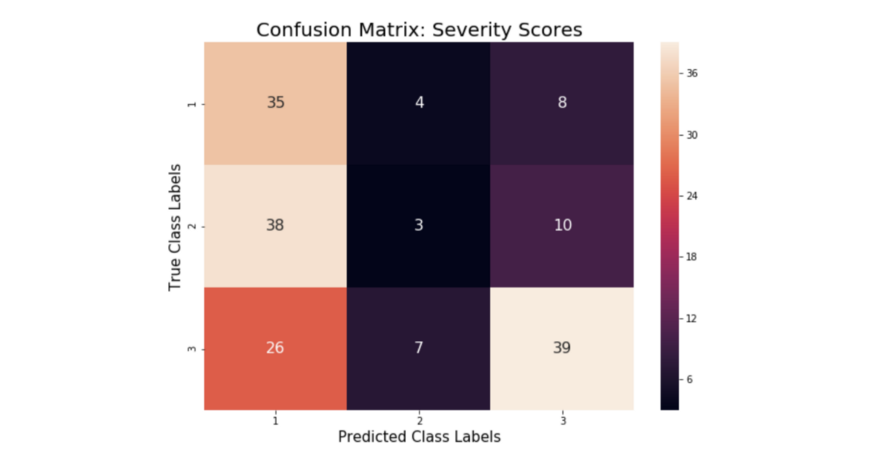
图10:严重性分类网络的混淆矩阵。每个类别的预测准确度如下:1–74.5%,2-–5.9%,3–54.2%,总体:45%。
方法二、多类别分割模型
调整U-Net以执行多类别分割,除了包含所有像素是否损坏的掩码(mask),还为损坏严重性类别生成了一个掩码(mask)。
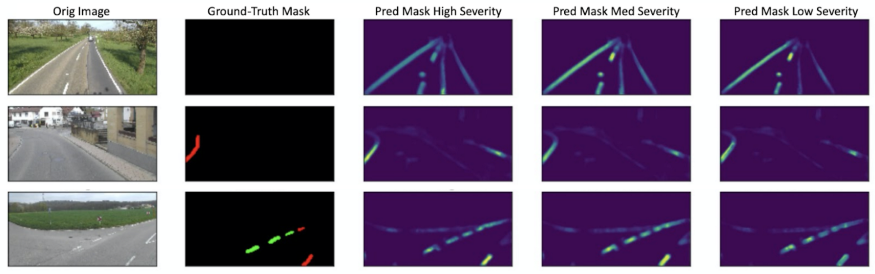
图11:多类别分割模型的示例输出。从左到右:严重性级别1、2和3的输入,目标和像素级别预测
多类分割模型的性能与多阶段方法中的分类器非常相似,因为它能够区分低度和高度油漆损坏,但对低度和中度损坏做出了类似预测。这在图12中得到了最充分的传达。
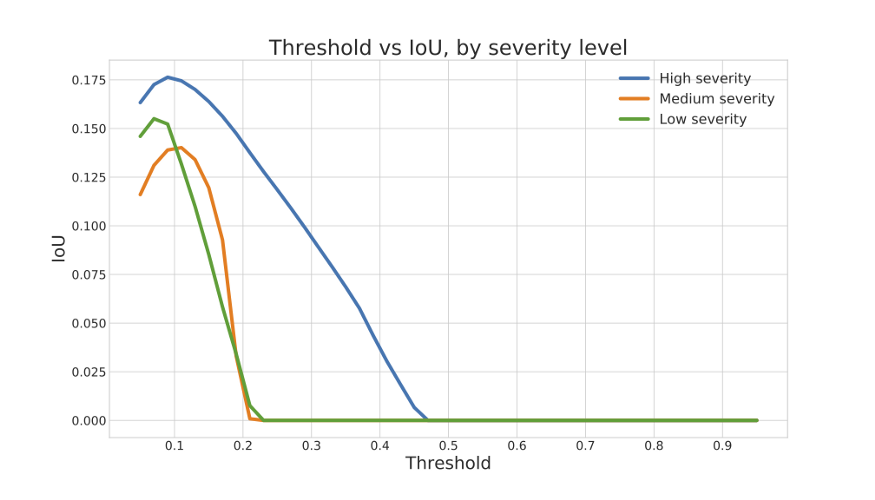
图12:多类细分模型的并集在交集上的变化作为概率阈值的函数。
多类分割模型的性能对预测阈值非常敏感,即在将像素指定为“损坏”之前,该模型必须逐像素预测确定性。考虑到模型在中、低损坏等级之间的不确定性,它倾向于为这两者分配非常低的概率。阈值超过20%时,我们的多类别分割模型只能预测出严重程度较高的损坏;较低的阈值导致对损坏区域的过度预测。这样区分严重性的困难与识别损坏位置的困难混为一谈。
从建模的角度来看,采用多阶段方法可能更有利于阐明任务在哪些方面最具挑战性。
6 重点
6.1 概括
理想情况:模型对于从不同角度、不同光照条件或天气的新区域获取的数据能保持较高的准确性。
数据:道路损坏的数据不足,并且 Maeda等人的数据无法完全归纳到我们的数据集中(尽管日本的道路和德国的道路仅存在细微的系统差异—德国道路通常较宽,颜色较浅),任何现有模型都需要进行大量的重新训练和调整才能处理新数据,但是数据收集和注释艰难,如果没有足够的资源来获取数据或雇用经过训练的专业知识人员,训练可推广模型对于本地市政来说是一项巨大挑战。
神经网络表征学习:使用复杂的神经网络进行表征学习是必要的,因为简单的计算机视觉方法无法解决问题。
6.2 噪声注释
我们的标注过程看似简单:识别损坏的油漆并将其严重性得分指定为1、2或3。但是查看MTurk结果,就很清楚这并不是那么简单。即使为MTurk提供了非常详细的说明并提供了充分的示例,工人之间也几乎没有一致意见。出现了一些意外的问题:
1.是否突出显示整个油漆线,还是仅突出虚线部分?
2.这里应该是油漆吗?
3.应该标记多远?
4.应该注释损坏周围多少“缓冲”区域为建模提供背景?
即使在讨论了这些要点并自己标记了数据之后,依然有几个相互矛盾的例子,这些例子构成了中、低程度损害的实例。因此我们建议研究员将严重度等级分解为能够满足他们要求的最少几类,我们怀疑这是我们的模型学会区分极端损坏而无法区分中、低损坏的关键原因。为减轻此错误需要更一致的标签、更多的数据或更少的严重性等级。
6.3 模型评估
分割模型的定量评估非常细致。首先,与真实掩码的比较都会受到两个噪声源的影响:
1.注释不一致引起的意外噪声(对我们来说是一个实际问题)。
2.在注释期间,突出显示的场景上下文数量。
评估指标:
1.IoU评估指标:假设我们有一个仅分割油漆线的理想模型,注释在突出显示场景上下文中越宽松,则IoU得分就越低。
2.以像素或图像为单位计算精度和召回率:对每个像素进行预测或对每个图像进行预测,为了将像素级预测映射到图像,将图像中任何正像素预测的存在视为该图像的正预测。精度和召回率的任何计算都必须通过最终用户希望模型的保守程度来限定。
请注意,我们用来评估模型的指标并不构成详尽清单。我们的建议是使用一套以像素和图像为单位的指标,以了解模型在各种特殊水平下的表现。
7 结束语
深度学习模型在精选数据集上表现非常出色,但在非结构化数据上仍有很大改进空间,应用计算机视觉模型执行自动道路损坏检测时,必须考虑的一些重要因素,包括:
•如何正确地对不同类型的损害进行分类。
•如何确保注释一致。
•具有数百万个参数的深度学习模型需要多少个注释才能有效学习:损坏存在的地方,以及损坏的程度。
•如何有效评估分割模型,并考虑注释的制作方式以及最终用户的身份。
我们的贡献是概述了这些挑战,并证明即使在数据有限和标签嘈杂的情况下,我们的模型也能够学会分割油漆线,分类严重的极端示例。模型的瓶颈在于数据。
参考资料
[1] R. Fan,M. Liu,基于无监督视差图分割的道路损坏检测https://arxiv.org/pdf/1910.04988.pdf (2019年),IEEE Transactions on Intelligent Transportation Systems
[2] S. Chen等人,“ 3D LiDAR扫描进行桥梁损伤评估” https://ascelibrary.org/doi/10.1061/9780784412640.052 (2012年),《法证工程》 2012年:通往更安全明天的门户
[3] S. Sattar等人,《使用智能手机传感器进行路面监测:回顾》https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6263868/ (2018年),传感器(瑞士巴塞尔)
[4] E. Buza等人,“ 具有图像处理和光谱聚类的坑洞检测”
https://pdfs.semanticscholar.org/78d5/c9c0c9bcdb939e028bc4d6f808300253dca1.pdf (2013年),第二届国际信息技术和计算机网络会议论文集
[5] J. Singh,S。Shekhar,《使用Mask R-CNN的智能手机捕获图像中的道路损坏检测和分类》https://arxiv.org/pdf/1811.04535.pdf%60 (2018),arXiv预印本arXiv:1811.04535
[6] H. Maeda等人,《使用深度神经网络的道路损坏检测与通过智能手机捕获的图像》https://arxiv.org/pdf/1801.09454.pdf (2018),计算机。辅助文明 基础设施。。
[7] O. Ronneberger等人,U-net:用于生物医学图像分割的卷积网络https://arxiv.org/pdf/1505.04597.pdf(2015年),医学图像计算和计算机辅助干预国际会议
 End
End
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~