
前端多线程大文件下载实践,提速10倍
背景
没错,你没有看错,是前端多线程,而不是Node。这一次的探索起源于最近开发中,有遇到视频流相关的开发需求发现了一个特殊的状态码,他的名字叫做 206~
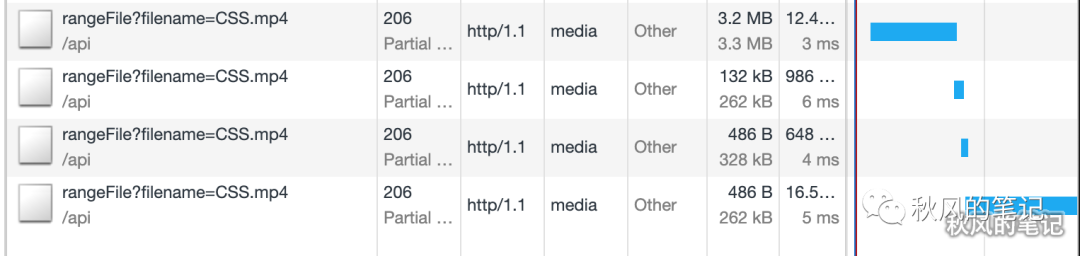
为了防止本文的枯燥,先上效果图镇文。(以一张3.7M 大小的图片为例)。
动画效果对比(单线程-左 VS 10个线程-右)

时间对比(单线程 VS 10个线程)
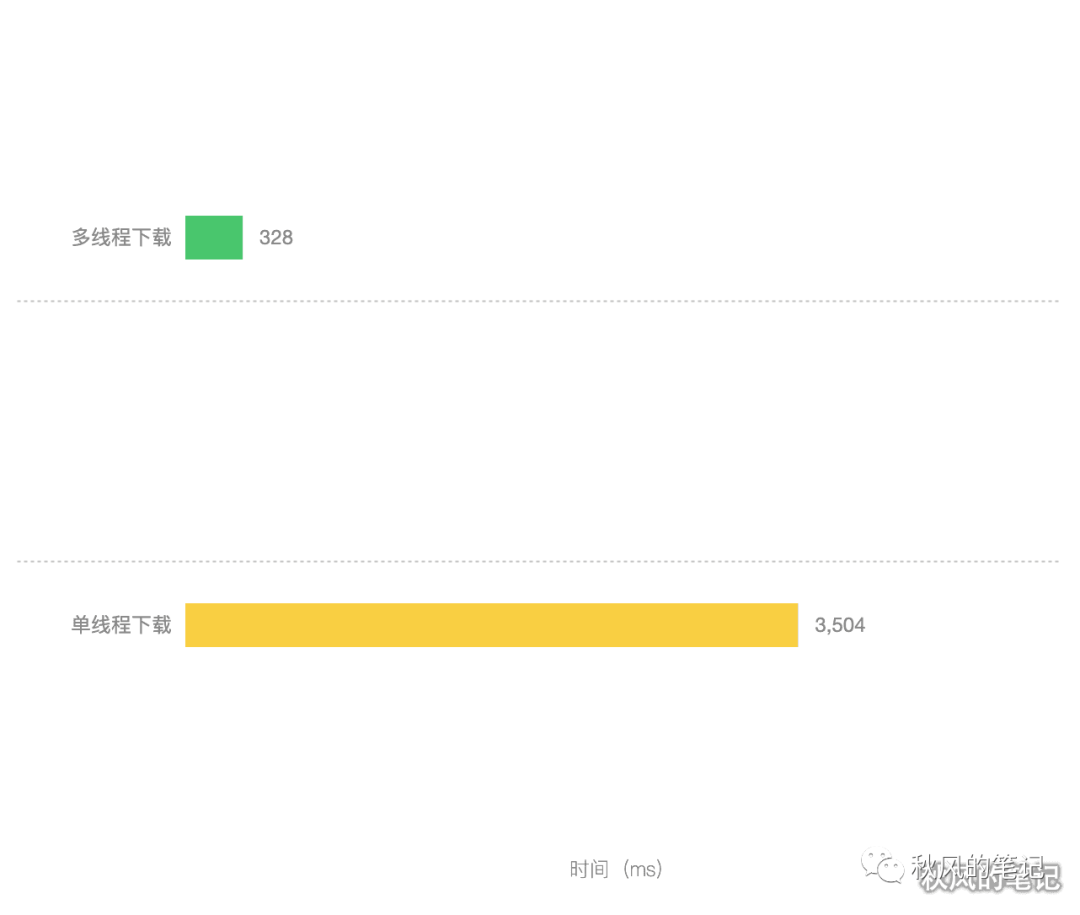
看到这里是不是有点心动,那么请你继续听我道来,那我们先抓个包来看看整个过程是怎么发生的。
GET /360_0388.jpg HTTP/1.1
Host: limit.qiufeng.com
Connection: keep-alive
...
Range: bytes=0-102399
HTTP/1.1 206 Partial Content
Server: openresty/1.13.6.2
Date: Sat, 19 Sep 2020 06:31:11 GMT
Content-Type: image/jpeg
Content-Length: 102400
....
Content-Range: bytes 0-102399/3670627
...(这里是文件流)
可以看到请求这里多出一个字段 Range: bytes=0-102399 ,服务端也多出一个字段Content-Range: bytes 0-102399/3670627,以及返回的 状态码为 206.
那么Range是什么呢?还记得前几天写过一篇文章,是关于文件下载的,其中有提到大文件的下载方式,有个叫 Range的东西,但是上一篇作为系统性地介绍文件下载的概览,因此没有对range 进行详细介绍。
以下所有代码均在 https://github.com/hua1995116/node-demo/tree/master/file-download/example/download-multiple
Range 基本介绍
Range的起源
Range是在 HTTP/1.1 中新增的一个字段,这个特性也是我们使用的迅雷等支持多线程下载以及断点下载的核心机制。(介绍性的文案,摘录了一下)
首先客户端会发起一个带有Range: bytes=0-xxx的请求,如果服务端支持 Range,则会在响应头中添加Accept-Ranges: bytes来表示支持 Range 的请求,之后客户端才可能发起带 Range 的请求。
服务端通过请求头中的Range: bytes=0-xxx来判断是否是进行 Range 处理,如果这个值存在而且有效,则只发回请求的那部分文件内容,响应的状态码变成206,表示Partial Content,并设置Content-Range。如果无效,则返回416状态码,表明Request Range Not Satisfiable。如果请求头中不带 Range,那么服务端则正常响应,也不会设置 Content-Range 等。
| Value | Description |
|---|---|
| 206 | Partial Content |
| 416 | Range Not Satisfiable |
Range的格式为:
Range:(unit=first byte pos)-[last byte pos]
即Range: 单位(如bytes)= 开始字节位置-结束字节位置。
我们来举个例子,假设我们开启了多线程下载,需要把一个5000byte的文件分为4个线程进行下载。
Range: bytes=0-1199 头1200个字节 Range: bytes=1200-2399 第二个1200字节 Range: bytes=2400-3599 第三个1200字节 Range: bytes=3600-5000 最后的1400字节
服务器给出响应:
第1个响应
Content-Length:1200 Content-Range:bytes 0-1199/5000
第2个响应
Content-Length:1200 Content-Range:bytes 1200-2399/5000
第3个响应
Content-Length:1200 Content-Range:bytes 2400-3599/5000
第4个响应
Content-Length:1400 Content-Range:bytes 3600-5000/5000
如果每个请求都成功了,服务端返回的response头中有一个 Content-Range 的字段域,Content-Range 用于响应头,告诉了客户端发送了多少数据,它描述了响应覆盖的范围和整个实体长度。一般格式:
Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity length]即Content-Range:字节 开始字节位置-结束字节位置/文件大小。
浏览器支持情况
主流浏览器目前都支持这个特性。
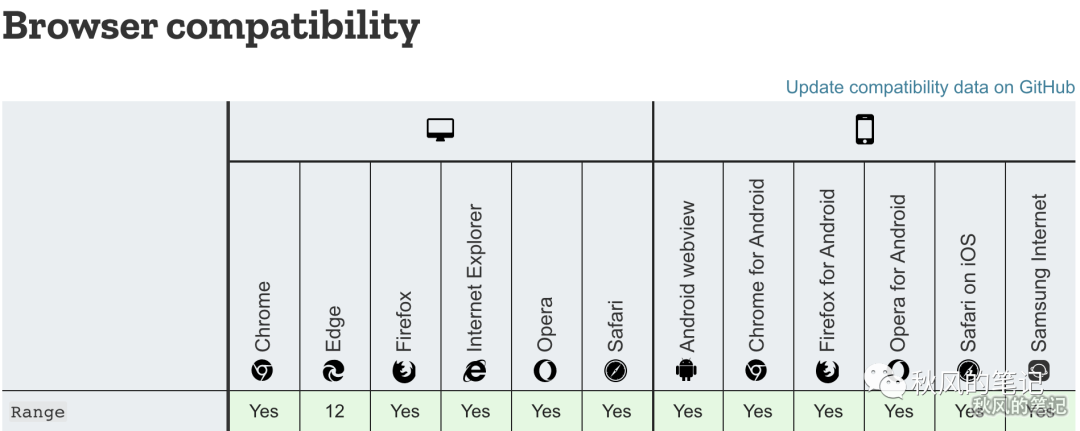
服务器支持
Nginx
在版本nginx版本 1.9.8 后,(加上 ngx_http_slice_module)默认自动支持,可以将 max_ranges 设置为 0的来取消这个设置。
Node
Node 默认不提供 对 Range方法的处理,需要自己写代码进行处理。
router.get('/api/rangeFile', async(ctx) => {
const { filename } = ctx.query;
const { size } = fs.statSync(path.join(__dirname, './static/', filename));
const range = ctx.headers['range'];
if (!range) {
ctx.set('Accept-Ranges', 'bytes');
ctx.body = fs.readFileSync(path.join(__dirname, './static/', filename));
return;
}
const { start, end } = getRange(range);
if (start >= size || end >= size) {
ctx.response.status = 416;
ctx.body = '';
return;
}
ctx.response.status = 206;
ctx.set('Accept-Ranges', 'bytes');
ctx.set('Content-Range', `bytes ${start}-${end ? end : size - 1}/${size}`);
ctx.body = fs.createReadStream(path.join(__dirname, './static/', filename), { start, end });
})
或者你可以使用 koa-send 这个库。
https://github.com/pillarjs/send/blob/0.17.1/index.js#L680
Range实践
架构总览
我们先来看下流程架构图总览。单线程很简单,正常下载就可以了,不懂的可以参看我上一篇文章。多线程的话,会比较麻烦一些,需要按片去下载,下载好后,需要进行合并再进行下载。(关于blob等下载方式依旧可以参看上一篇)

服务端代码
很简单,就是对Range做了兼容。
router.get('/api/rangeFile', async(ctx) => {
const { filename } = ctx.query;
const { size } = fs.statSync(path.join(__dirname, './static/', filename));
const range = ctx.headers['range'];
if (!range) {
ctx.set('Accept-Ranges', 'bytes');
ctx.body = fs.readFileSync(path.join(__dirname, './static/', filename));
return;
}
const { start, end } = getRange(range);
if (start >= size || end >= size) {
ctx.response.status = 416;
ctx.body = '';
return;
}
ctx.response.status = 206;
ctx.set('Accept-Ranges', 'bytes');
ctx.set('Content-Range', `bytes ${start}-${end ? end : size - 1}/${size}`);
ctx.body = fs.createReadStream(path.join(__dirname, './static/', filename), { start, end });
})
html
然后来编写 html ,这没有什么好说的,写两个按钮来展示。
<button id="download1">串行下载button>
<button id="download2">多线程下载button>
<script src="https://cdn.bootcss.com/axios/0.19.2/axios.min.js">script>
js公共参数
const m = 1024 * 520; // 分片的大小
const url = 'http://localhost:8888/api/rangeFile?filename=360_0388.jpg'; // 要下载的地址
单线程部分
单线程下载代码,直接去请求以blob方式获取,然后用blobURL 的方式下载。
download1.onclick = () => {
console.time("直接下载");
function download(url) {
const req = new XMLHttpRequest();
req.open("GET", url, true);
req.responseType = "blob";
req.onload = function (oEvent) {
const content = req.response;
const aTag = document.createElement('a');
aTag.download = '360_0388.jpg';
const blob = new Blob([content])
const blobUrl = URL.createObjectURL(blob);
aTag.href = blobUrl;
aTag.click();
URL.revokeObjectURL(blob);
console.timeEnd("直接下载");
};
req.send();
}
download(url);
}
多线程部分
首先发送一个 head 请求,来获取文件的大小,然后根据 length 以及设置的分片大小,来计算每个分片是滑动距离。通过Promise.all的回调中,用concatenate函数对分片 buffer 进行一个合并成一个 blob,然后用blobURL 的方式下载。
// script
function downloadRange(url, start, end, i) {
return new Promise((resolve, reject) => {
const req = new XMLHttpRequest();
req.open("GET", url, true);
req.setRequestHeader('range', `bytes=${start}-${end}`)
req.responseType = "blob";
req.onload = function (oEvent) {
req.response.arrayBuffer().then(res => {
resolve({
i,
buffer: res
});
})
};
req.send();
})
}
// 合并buffer
function concatenate(resultConstructor, arrays) {
let totalLength = 0;
for (let arr of arrays) {
totalLength += arr.length;
}
let result = new resultConstructor(totalLength);
let offset = 0;
for (let arr of arrays) {
result.set(arr, offset);
offset += arr.length;
}
return result;
}
download2.onclick = () => {
axios({
url,
method: 'head',
}).then((res) => {
// 获取长度来进行分割块
console.time("并发下载");
const size = Number(res.headers['content-length']);
const length = parseInt(size / m);
const arr = []
for (let i = 0; i < length; i++) {
let start = i * m;
let end = (i == length - 1) ? size - 1 : (i + 1) * m - 1;
arr.push(downloadRange(url, start, end, i))
}
Promise.all(arr).then(res => {
const arrBufferList = res.sort(item => item.i - item.i).map(item => new Uint8Array(item.buffer));
const allBuffer = concatenate(Uint8Array, arrBufferList);
const blob = new Blob([allBuffer], {type: 'image/jpeg'});
const blobUrl = URL.createObjectURL(blob);
const aTag = document.createElement('a');
aTag.download = '360_0388.jpg';
aTag.href = blobUrl;
aTag.click();
URL.revokeObjectURL(blob);
console.timeEnd("并发下载");
})
})
}
完整示例
https://github.com/hua1995116/node-demo
// 进入目录
cd file-download
// 启动
node server.js
// 打开
http://localhost:8888/example/download-multiple/index.html
由于谷歌浏览器在 HTTP/1.1 对于单个域名有所限制,单个域名最大的并发量是 6.
这一点可以在源码以及官方人员的讨论中体现。
讨论地址
https://bugs.chromium.org/p/chromium/issues/detail?id=12066
Chromium 源码
// https://source.chromium.org/chromium/chromium/src/+/refs/tags/87.0.4268.1:net/socket/client_socket_pool_manager.cc;l=47
// Default to allow up to 6 connections per host. Experiment and tuning may
// try other values (greater than 0). Too large may cause many problems, such
// as home routers blocking the connections!?!? See http://crbug.com/12066.
//
// WebSocket connections are long-lived, and should be treated differently
// than normal other connections. Use a limit of 255, so the limit for wss will
// be the same as the limit for ws. Also note that Firefox uses a limit of 200.
// See http://crbug.com/486800
int g_max_sockets_per_group[] = {
6, // NORMAL_SOCKET_POOL
255 // WEBSOCKET_SOCKET_POOL
};
因此为了配合这个特性我将文件分成6个片段,每个片段为520kb (没错,写个代码都要搞个爱你的数字),即开启6个线程进行下载。
我用单个线程和多个线程进行分别下载了6次,看上去速度是差不多的。那么为什么和我们预期的不一样呢?

探索失败的原因
我开始仔细对比两个请求,观察这两个请求的速度。
6个线程并发
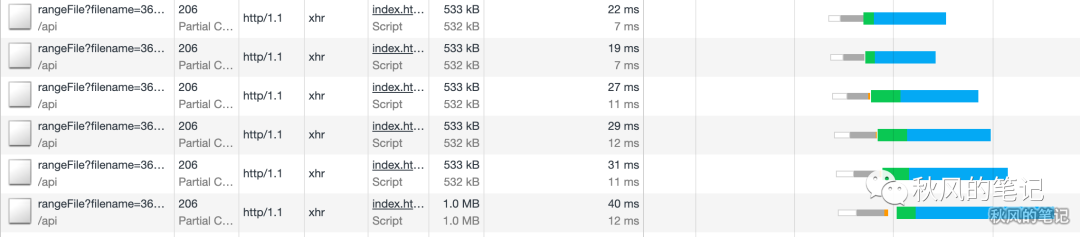
单个线程

我们按照3.7M 82ms 的速度来算的话,大约为 1ms 下载 46kb,而实际情况可以看到,533kb ,平均就要下载 20ms 左右(已经刨去了连接时间,纯 content 下载时间)。
我就去查找了一些资料,明白了有个叫做下行速度和上行速度的东西。
网络的实际传输速度要分上行速度和下行速度,上行速率就是发送出去数据的速度,下行就是收到数据的速度。ADSL是根据我们平时上网,发出数据的要求相对下载数据的较小这种习惯来实现的一种传输方式。我们说对于4M的宽带,那么我们的l理论最高下载速度就是512K/S,这就是所说的下行速度。 --百度百科
那我们现在的情况是怎么样的呢?
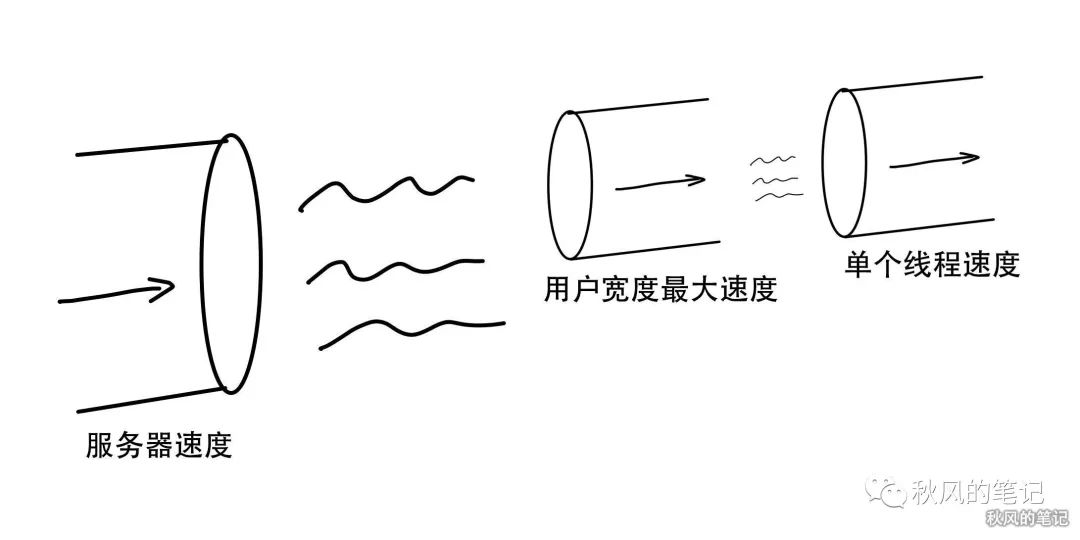
把服务器比作一根大水管,我来用图模拟一下我们单个线程和多个线程下载的情况。左侧为服务器端,右侧为客户端。(以下所有情况都是考虑理想情况下,只是为了模拟过程,不考虑其他一些程序的竞态影响。)
单线程
多线程
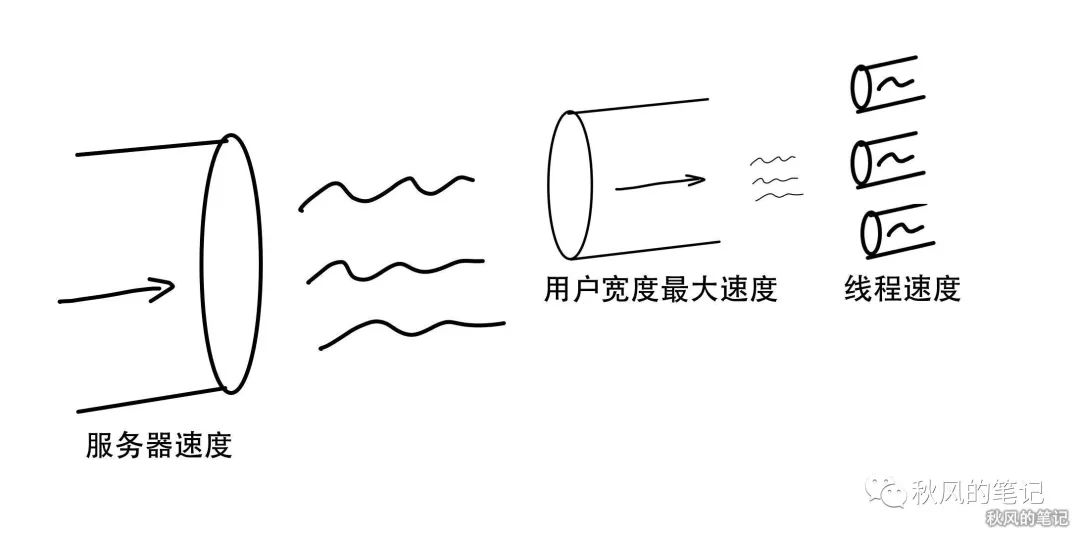
没错,由于我们的服务器是一根大水管,流速是一定的,并且我们客户端没有限制。如果是单线程跑的话,那么会跑满用户的最大的速度。如果是多线程呢,以3个线程为例子的话,相当于每个线程都跑了原先线程三分之一的速度。合起来的速度和单个线程是没有差别的。
下面我就分几种情况来讲解一下,什么样的情况才我们的多线程才会生效呢?
服务器带宽大于用户带宽,不做任何限制
这种情况其实我们遇到的情况差不多的。
服务器带宽远大于用户带宽,限制单连接网速
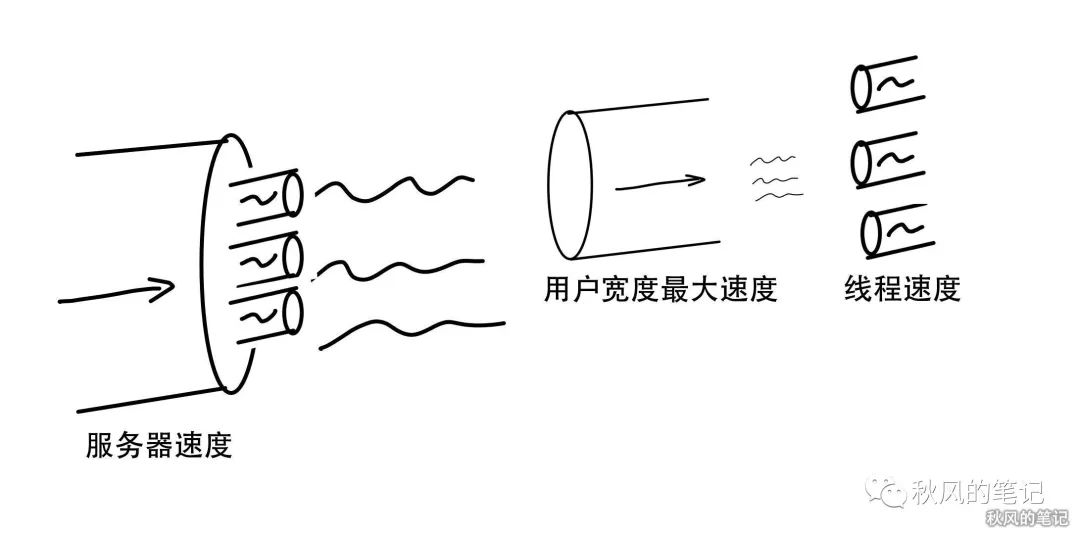
如果服务器限制了单个宽带的下载速度,大部分也是这种情况,例如百度云就是这样,例如明明你是 10M 的宽带,但是实际下载速度只有 100kb/s ,这种情况下,我们就可以开启多线程去下载,因为它往往限制的是单个TCP的下载,当然在线上环境不是说可以让用户开启无限多个线程,还是会有限制的,会限制你当前IP的最大TCP。这种情况下下载的上限往往是你的用户最大速度。按照上面的例子,如果你开10个线程已经达到了最大速度,因为再大,你的入口已经被限制死了,那么各个线程之间就会抢占速度,再多开线程也没有用了。
改进方案
由于 Node 我暂时没有找到比较简单地控制下载速度的方法,因此我就引入了 Nginx。
我们将每个TCP连接的速度控制在 1M/s。
加入配置 limit_rate 1M;
准备工作
1.nginx_conf
server {
listen 80;
server_name limit.qiufeng.com;
access_log /opt/logs/wwwlogs/limitqiufeng.access.log;
error_log /opt/logs/wwwlogs/limitqiufeng.error.log;
add_header Cache-Control max-age=60;
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'GET, OPTIONS';
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization,range,If-Range';
if ($request_method = 'OPTIONS') {
return 204;
}
limit_rate 1M;
location / {
root 你的静态目录;
index index.html;
}
}
2.配置本地 host
127.0.0.1 limit.qiufeng.com
查看效果,这下基本上速度已经是正常了,多线程下载比单线程快了速度。基本是 5-6 : 1 的速度,但是发现如果下载过程中快速点击数次后,使用Range下载会越来越快(此处怀疑是 Nginx 做了什么缓存,暂时没有深入研究)。
修改代码中的下载地址
const url = 'http://localhost:8888/api/rangeFile?filename=360_0388.jpg';
变成
const url = 'http://limit.qiufeng.com/360_0388.jpg';
测试下载速度

还记得上面说的吗,关于 HTTP/1.1 同一站点只能并发 6 个请求,多余的请求会放到下一个批次。但是 HTTP/2.0 不受这个限制,多路复用代替了 HTTP/1.x 的序列和阻塞机制。让我们来升级 HTTP/2.0 来测试一下。
需要本地生成一个证书。(生成证书方法: https://juejin.im/post/6844903556722475021)
server {
listen 443 ssl http2;
ssl on;
ssl_certificate /usr/local/openresty/nginx/conf/ssl/server.crt;
ssl_certificate_key /usr/local/openresty/nginx/conf/ssl/server.key;
ssl_session_cache shared:le_nginx_SSL:1m;
ssl_session_timeout 1440m;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers RC4:HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
server_name limit.qiufeng.com;
access_log /opt/logs/wwwlogs/limitqiufeng2.access.log;
error_log /opt/logs/wwwlogs/limitqiufeng2.error.log;
add_header Cache-Control max-age=60;
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Methods 'GET, OPTIONS';
add_header Access-Control-Allow-Headers 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization,range,If-Range';
if ($request_method = 'OPTIONS') {
return 204;
}
limit_rate 1M;
location / {
root 你存放项目的前缀路径/node-demo/file-download/;
index index.html;
}
}
10个线程
将单个下载大小进行修改
const m = 1024 * 400;

12个线程
24个线程
当然线程不是越多越好,经过测试,发现线程达到一定数量的时候,反而速度会更加缓慢。以下是 36个并发请求的效果图。
实际应用探索
那么多进程下载到底有啥用呢?没错,开头也说了,这个分片机制是迅雷等下载软件的核心机制。
网易云课堂
https://study.163.com/course/courseLearn.htm?courseId=1004500008#/learn/video?lessonId=1048954063&courseId=1004500008
我们打开控制台,很容易地发现这个下载 url,直接一个裸奔的 mp4 下载地址。

把我们的测试脚本从控制台输入进行。
// 测试脚本,由于太长了,而且如果仔细看了上面的文章也应该能写出代码。实在写不出可以看以下代码。
https://github.com/hua1995116/node-demo/blob/master/file-download/example/download-multiple/script.js
直接下载

多线程下载

可以看到由于网易云课堂对单个TCP的下载速度并没有什么限制没有那么严格,提升的速度不是那么明显。
百度云
我们就来测试一下网页版的百度云。

以一个 16.6M的文件为例。
打开网页版百度云盘的界面,点击下载

这个时候点击暂停, 打开 chrome -> 更多 -> 下载内容 -> 右键复制下载链接

依旧用上述的网易云课程下载课程的脚本。只不过你需要改一下参数。
url 改成对应百度云下载链接
m 改成 1024 * 1024 * 2 合适的分片大小~
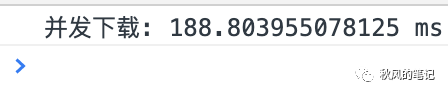
直接下载
百度云多单个TCP连接的限速,真的是惨无人道,足足花了217秒!!!就一个17M的文件,平时我们饱受了它多少的折磨。(除了VIP玩家)

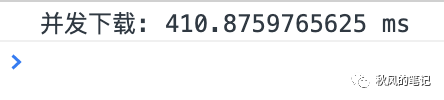
多线程下载
由于是HTTP/1.1 因此我们只要开启6个以及以上的线程下载就好了。以下是多线程下载的速度,约用时 46 秒。

我们通过这个图再来切身感受一下速度差异。
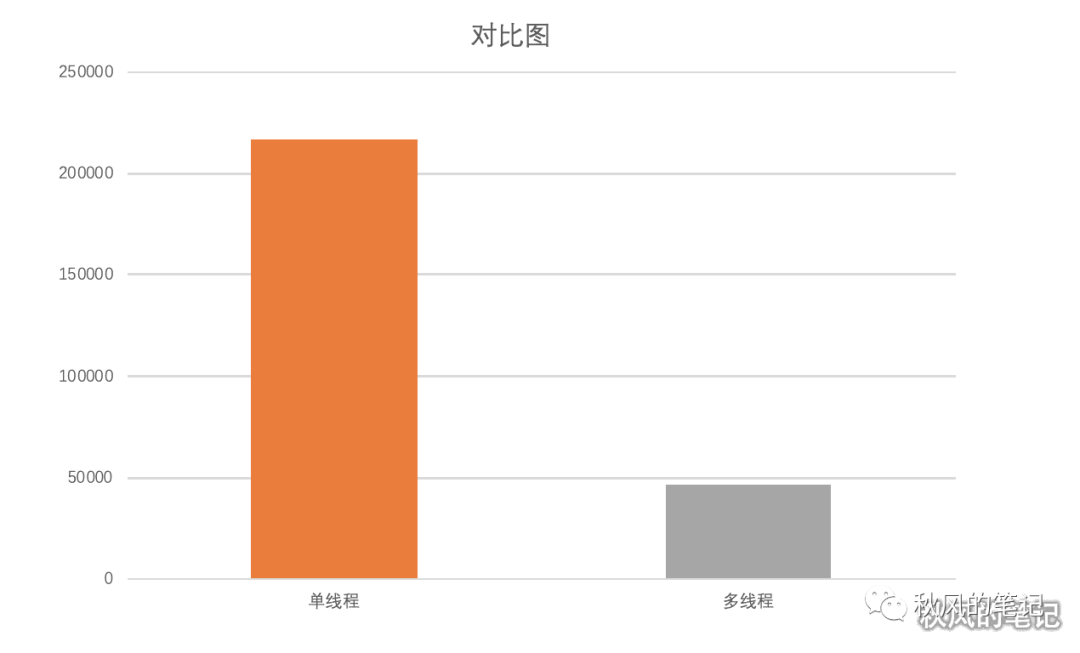
真香,免费且只靠我们前端自己实现了这个功能,太tm香了,你还不赶紧来试试??
方案缺陷
1.对于大文件的上限有一定的限制
由于 blob 在 各大浏览器有上限大小的限制,因此该方法还是存在一定的缺陷。
| Browser | Constructs as | Filenames | Max Blob Size | Dependencies |
|---|---|---|---|---|
| Firefox 20+ | Blob | Yes | 800 MiB | None |
| Firefox < 20 | data: URI | No | n/a | Blob.js |
| Chrome | Blob | Yes | 2GB | None |
| Chrome for Android | Blob | Yes | RAM/5 | None |
| Edge | Blob | Yes | ? | None |
| IE 10+ | Blob | Yes | 600 MiB | None |
| Opera 15+ | Blob | Yes | 500 MiB | None |
| Opera < 15 | data: URI | No | n/a | Blob.js |
| Safari 6.1+* | Blob | No | ? | None |
| Safari < 6 | data: URI | No | n/a | Blob.js |
| Safari 10.1+ | Blob | Yes | n/a | None |
2. 服务器对单个TCP速度有所限制
一般情况下都会有限制,那么这个时候就看用户的宽度速度了。
结尾
文章写的比较仓促,表达可能不是特别精准,如有错误之处,欢迎各位大佬指出。
回头调研下,有没有网页版百度云加速的插件,如果没有就造一个网页版百度云下载的插件~。
参考文献
Nginx带宽控制 : https://blog.huoding.com/2015/03/20/423
openresty 部署 https 并开启 http2 支持 : https://www.gryen.com/articles/show/5.html
聊一聊HTTP的Range : https://dabing1022.github.io/2016/12/24/%E8%81%8A%E4%B8%80%E8%81%8AHTTP%E7%9A%84Range,%20Content-Range/