
起点客户端精准化测试的演进之路

点击上方蓝字关注我,知识会给你力量

精准化测试,实际上就是对「业务」——「测试用例」——「代码」进行关联建模并追踪他们的变化的一种测试方法。
在敏捷迭代的团队里,精准化测试是让团队跑的更快、更稳的一个重要工具。起点客户端团队基于当前的迭代场景,结合自身的一些开发特定,定制了一套完整的精准化测试体系,对业务测试的效率和App的稳定性,提供了强有力的工具保障。
背景
在敏捷测试过程中,经常会遇到这样的问题:
我自测过了,你简单测下就好了。
代码重构了,我也不知道影响什么业务……
我就升级了SDK,不知道有什么影响……
代码改动挺多的,要么全测一遍吧!
我就改了一行代码,你要测几天?
这就是当前敏捷开发模式下,测试和开发的矛盾会越来越多的原因。快速的迭代,会极大的扩大测试的回归成本。
所以,敏捷开发下测试的最终选择,一定只有两条路:
自动化测试,降低人工成本
缩小回归范围,提高测试效率
否则大量的回归测试内容,会给测试团队增加数倍的工作量。
而它们的优先级,一定是优先「缩小回归范围」,自动化测试只是工具,缩小回归范围,才能给团队带来效率的提升,这个方向就是通过「代码分析」,来找到缩减无关的测试内容。
例如一个线上问题,对指定机型的设备有bug,开发进行修复后,对指定机型进行了if else判断,测试用例可以缩减到当前判断分别为true和false的场景。
敏捷开发模式下,唯一不变的东西就是「变化」,测试的过程,就是从变化中找到核心的影响因素,从中分析出需要测什么,不需要测什么。
那么在敏捷迭代的这样一个环境下,开发者和测试怎么来保证,我「提交的代码」、「测过的Case」在任何时候都是正确的呢?
当你无法量化的时候,你就在用你的人品和信誉做担保,而开发团队对你的信任也是基于你的信誉。可是在你还没有建立你的信誉的时候,你就必须拿出量化的东西来赢得信任。
❝
精准化测试,需要测试从提交的代码中找到具体的业务修改点,这对测试的要求很高,他需要从开发提交的代码中了解具体修改的业务逻辑点,而开发的一个commit,有时候并不是很纯粹,经常会夹带一些「私货」,这也是引起测试未覆盖的一个重要原因。
❞
所以,我们搭建精准化测试平台的意义,主要在于下面三点:
验证开发所有的代码修改,是否被测试用例完全覆盖
避免开发提交了与Commit信息无关的代码,导致测试未验证的代码出现问题
从代码角度验证测试用例的完整性
精准化测试平台的适用场景,主要是下面两个:
功能提测阶段:验证测试用例是否覆盖修改代码,避免测试用例遗漏
回归测试阶段:验证新合入代码是否有未覆盖的代码(如果有自动化测试,可以进行回归验证)
但是,精准化测试并不是测试质量保证体系的银弹,对于精准化的覆盖率测试,需要先明确一个前提公理,那就是Coverage覆盖到的代码,就算是testcase执行完成了。因为覆盖率测试只能保障代码被执行,而执行逻辑是否正确,并不在保证之内。
因此,盲目的追求代码覆盖率是没有意义的,即使已经达到了 100%的代码覆盖率,软件的质量也不可能做到万无一失,因为代码覆盖率的计算只是基于执行代码的,并不能发现那些「未考虑某些输入」、「未判断的逻辑异常」以及「未处理某些情况」形成的缺陷。
设计思路
针对上面的这些问题,在开发的角度,我们希望能对测试的效率进行提升。
技术选型与方案设计
在服务端开发中,通常使用「单测+覆盖率」的方式来保证代码的执行覆盖程度,所以,这里借助代码覆盖率,来作为关联代码和用例的桥梁。
在移动端,代码覆盖率通常使用JaCoCo,即 Java Code Coverage来实现。
JaCoco作为一个Java平台下的老牌覆盖率工具,在开源平台上已经经过了多年的验证,这也是我们选择它作为技术选型的一个重要依据,它的原理其实非常简单,就是在代码中插入大量的探针,探针执行过的语句块即为执行过的代码块,通过分析探针的执行情况,就能算出相应的覆盖率,下面这张图就是一个反编译的探针代码。

image-20211122112802820
JaCoco默认场景下是不支持增量插入探针的,但在实际开发过程中,一般不太会对全量代码做检测,所以,我们需要改造JaCoco,为精准化测试平台提供增量探针功能。同时,还需要接入CI系统,与现有软件开发流程对接,完成「开发-测试-回归」的闭环。
大部分公司的CI系统都会采用Jenkins来搭建,起点在接入腾讯的蓝盾之前,也是采用的Jenkins,所以,整体的系统流程图如下所示。
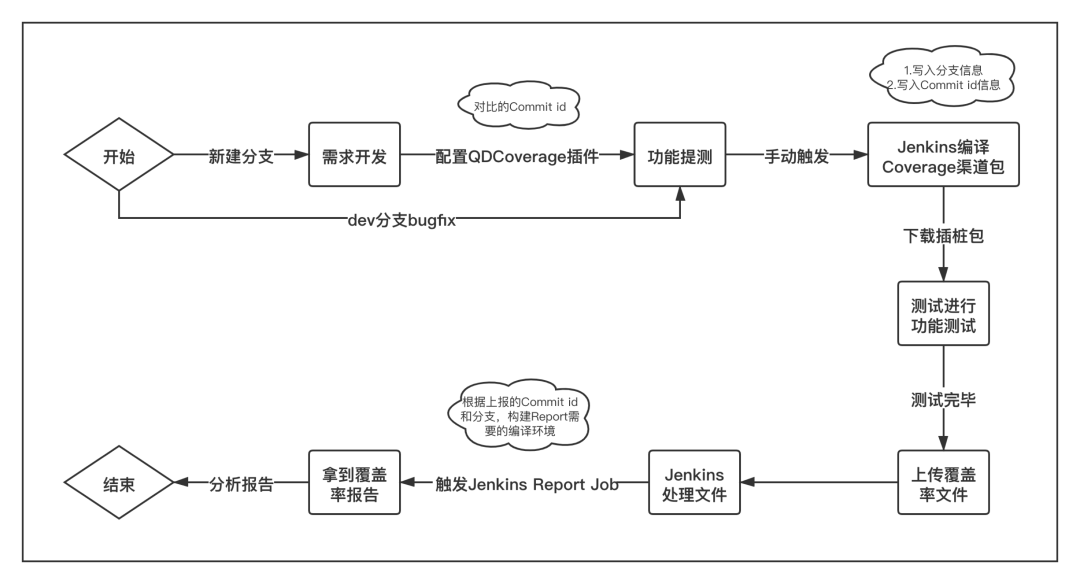
image-20211122103526203
由于Jenkins Job的特殊性,当我们把增量覆盖率插件部署到CI后,会有很多流程上无法打通的问题,例如,覆盖率插桩包编译好后,需要测试手动测试,再将数据统计文件上传到Jenkins,然后再触发新的Job来生成报告,但这一步,在Jenkins上又没办法拿到对应编译包的源码和class文件,这与本地的流程有很大不同,同时,Jenkins拉取代码需要使用git commitid,这些内容也很难对齐,所以,我们在CI上部署,需要对整个流程做一些改动。
创建一个新的Jenkins Job,负责编译插桩包,在这个Job中,需要执行者输入:分支名、BaseCommitID和EndCommitID,这两个CommitID,就对应git diff中的对比id,Jenkins根据指定的CommitID和分支,拉取代码
这个Job在执行编译后,会将这些参数在编译时写入App的asset目录下的具体文件
测试下载增量包后进行手工测试,测试完毕后在App中的某个后门入口上传覆盖率文件
覆盖率文件上传后,触发新的Jenkins Job,在上报的同时,App从文件中读取前一步写入到assert中的文件,将分支名、BaseCommitID和EndCommitID这些信息同时上报
新的Jenkins Job拿到这些信息后,根据上报的CommitID和分支名等信息,重新进行一次编译,复刻第一次插桩包的编译过程
这个Job编译完成后,在脚本中继续调用generateCoverageReport指令来生成报告,这个时候编译的产物就和编译插桩包的内容一模一样了
至此,整个流程就形成了一个闭环,将最后一步生成的报告同步到公司内部的展示平台即可展示。
❝
起点在接入腾讯蓝盾系统之后,不再使用Jenkins来做CI,但蓝盾的整体流程与Jenkins基本类似,所以整个流程迁移蓝盾后并不需要做太多的修改,只需要将Jenkins的Job,迁移到蓝盾的流水线即可。
❞
对于测试人员来说,他们的使用流程与之前并无太大区别,主要的修改在于使用精准化的Job来打出增量包,整体流程如下所示。
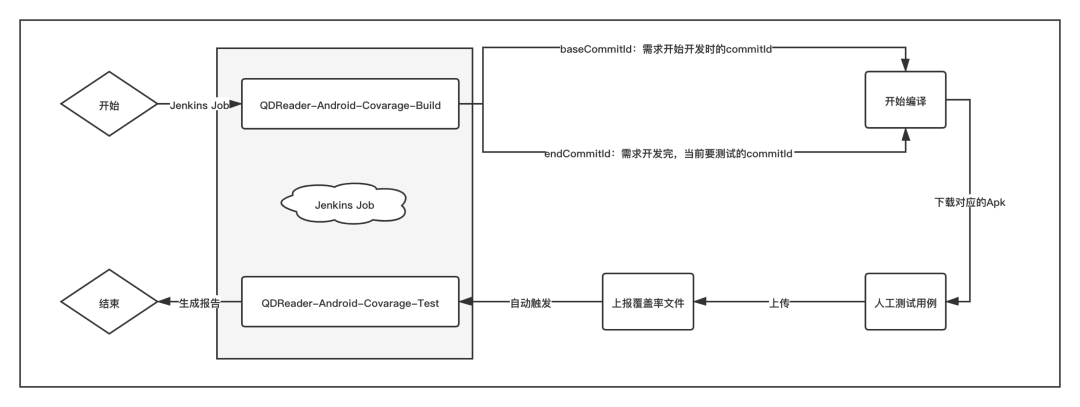
image-20211122112556387
至此,我们就完成了从开发到测试,并支持完整CI流程的方案设计。
拓展增量实现
由于JaCoco Android Plugin在客户端没有增量的实现,所以,我们需要单独实现一套Plugin系统,在借助JaCoco探针的插入机制基础上,完成对增量代码的探针修改。
通常在增量修改方案有以下三种:
增量方案1:在插桩时,对diff信息做增量,精确到行级别插桩
增量方案2:插桩时做全量插桩,在生成报告时对diff信息做过滤,在报告级别做行增量
增量方案3:插桩时对Class级别做diff过滤,并进行Class内的全量插桩,在生成报告时,针对diff信息的行级别做报告的过滤
这里我们选择的第三种方案来实现。这是一种性价比最高的方案,通过获取diff信息,在插件层不用做太多的修改,只需要过滤掉非diff的文件,而在生成报告时,再借助diff行号来做高亮展示即可。
在Gradle插件中,我们在Transform过程中来获取增量内容,借助Git diff的执行结果,过滤需要做增量的修改Class文件,相关代码如下所示。
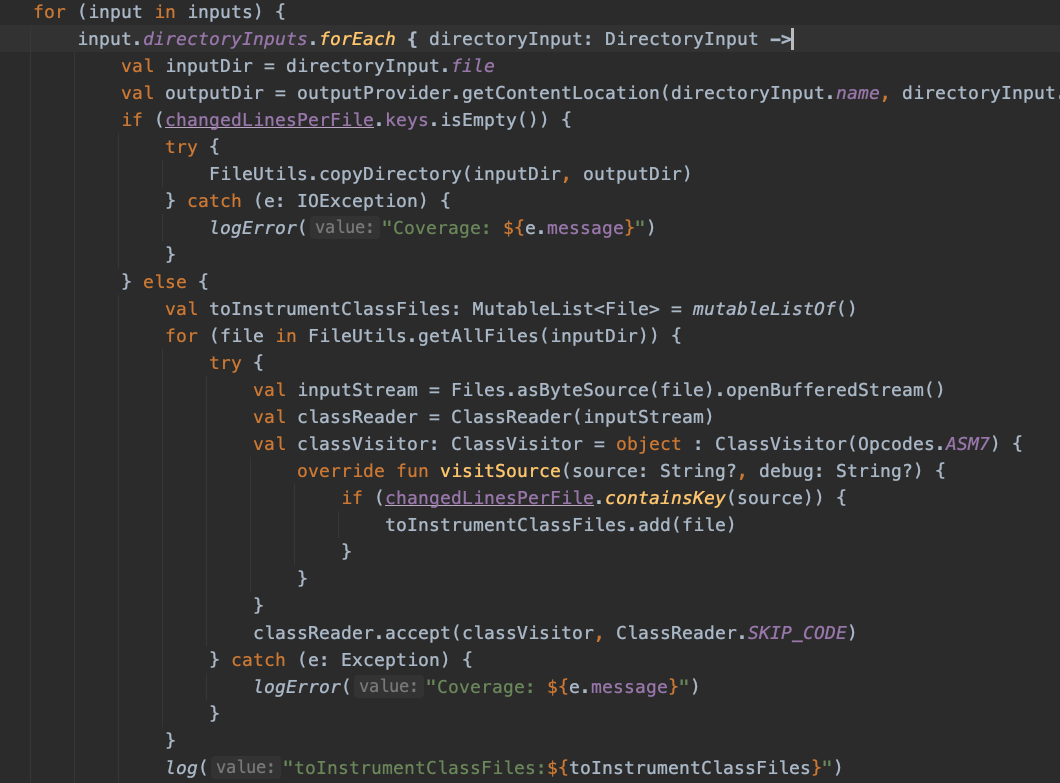
image-20211122111536575
在获取到增量Class文件之后,再借助JaCoco增加探针来实现探针代码的织入,相关代码如下所示。
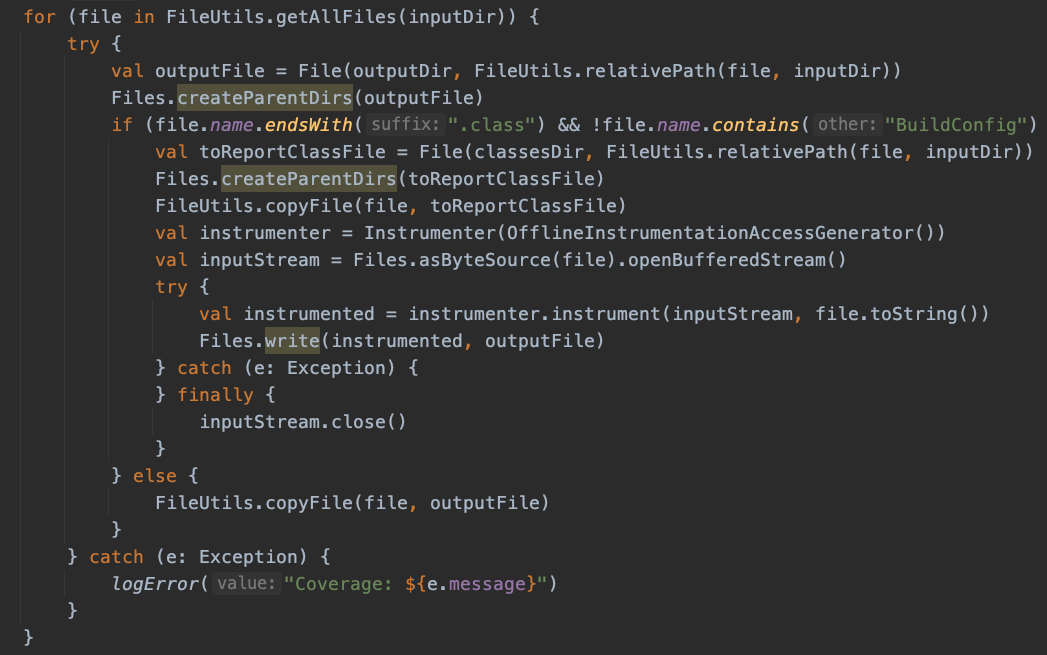
image-20211122111634396
增量探针的问题解决了,那么下面的问题就是如何获取diff信息了。在Git中,我们可以很方便的通过git diff命令来获取增量信息。
该命令格式如下所示,它用来对比不同commit(或分支)间的增量代码:
git diff [<options>] <commit> <commit>
其中commit可以是分支名,也可以是commit的id,对比分支间的差异,可以简写为 git diff targetBranchName,表示对比当前分支与目标分支间的代码差异。
❝
diff文件的解析这里不做过多的解释,感兴趣的朋友可以参考我的博客 https://xuyisheng.top/diff/
❞
获取到diff增量信息之后,就可以借助正则来获取我们需要的信息了——diff文件,以及该文件中的diff行号。
修改Report生成逻辑
一般来说,修改JaCoco的Report生成逻辑,通常是通过修改JaCoco Analyzer类的analyzeClass函数。但实际上,JaCoco的Report库,给我们提供了修改的接口。在修改之前,我们先来了解下JaCoco默认的Report机制。
原始报告解读
JaCoco覆盖率报告分为三层递进数据:Package——Class——Method,其覆盖率统计实际上是由内向外的。
先了解下场景,我们修改了两行代码,并执行了其中一行。我们先看Method级别:
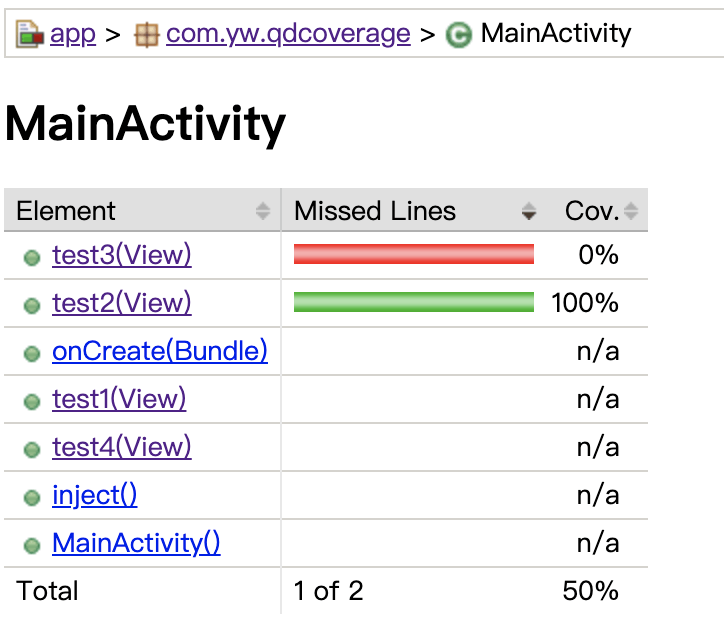
image-20210720112035764
这里由于是增量代码检测,所以在MainActivity里面的所有代码中,只有有代码修改的两个方法有覆盖率数据,即test2和test3。其中test2执行了,所以其覆盖率为100%,而test3未执行,所以其覆盖率数据未0%。
再来看看Class级别:
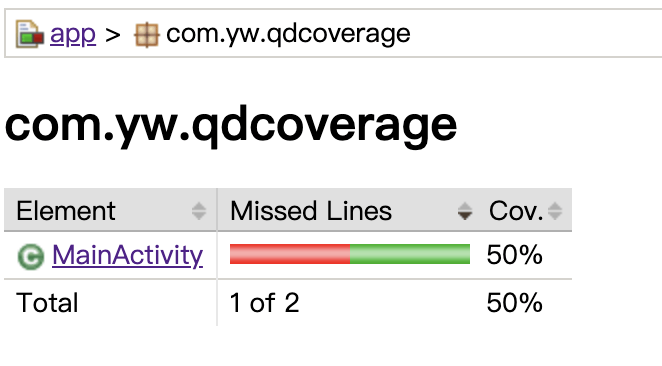
image-20210720112314835
这里的覆盖率是以Method为维度进行统计的,发生变更的有两个Method,执行的是一个,所以覆盖率为50%。
同理,再外层的Package级别,则是以Class为维度进行统计的。
增量覆盖率的统计
由于JaCoco的报告太过于复杂,而且与我们常规的理解有些不同,对于测试或者Reporter对象来说,有太多的无关紧要的数据,所以,我们可以自己来编写增量覆盖率的统计规则。
在前面的插桩过程中,实际上我们已经拿到了「修改的文件」——「修改的具体行号」这样的一个对应关系文件,只要我们再读出JaCoco覆盖率文件中,这些修改的行,是否被执行的数据,其实就可以完成覆盖率的统计了,我们简单的定义「增量覆盖率」的统计规则:
该文件中被修改的代码中已执行或者部分执行的代码行数 / 该文件中被修改的所有代码行数 %
有了这些数据之后,我们也不需要再使用JaCoco的覆盖率报表了,直接使用自己的统计数据,而只需要最后跳转每个文件的源代码覆盖文件即可。
那么现在的问题就剩下如何拿到行是否被执行的覆盖率数据了。
参考下官方的Report Demo,地址如下所示。
https://github.com/jacoco/jacoco/blob/master/org.jacoco.examples/src/org/jacoco/examples/ReportGenerator.java
核心代码如下所示。
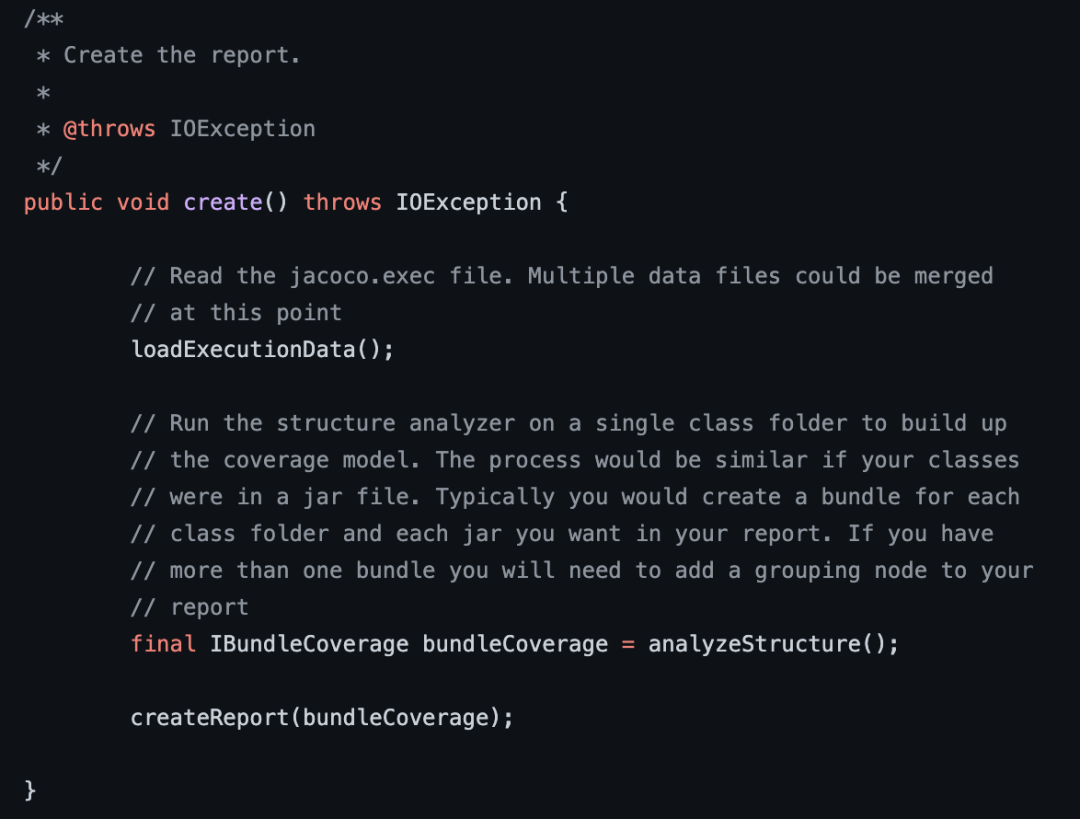
image-20210819113814268
官方在Demo中给出了一个IBundleCoverage的结构化数据,它就是从execution Data File中得到的所有覆盖率的数据,那么接下来,我们遍历这个数据,拿到其中的LineImpl信息,即可获取当前行是否被执行的数据了,再和我们的增量信息做对比,就可以完成增量覆盖率的统计计算了。
修改报表
JaCoco的原生报表,结构比较复杂,不适合展示和汇总,特别是不利于非技术人员的使用,所以,我们需要对原生报表进行修改,让报表更加直观。
首先,我们来思考下,一个非技术人员究竟需要怎么看一个覆盖率报表,假如我是这样一个人,我想知道的,就是每个文件的增量代码覆盖率,说直白一点,就是这个文件里面,在这个需求中,我修改了哪些行,这些行里面,有哪些行是已经执行了,哪些是没执行的,如果能知道这个修改对应的修改人是谁,是在哪个需求里面改的,那就更好了,其它的内容,我也并不关心。
所以,在梳理了覆盖率真正的需求之后,我们抽象出了新的覆盖率报表的必须项目:
文件名
已覆盖了多少行
总共修改了多少行
提交信息
覆盖率数据
这是汇总表,针对每个文件的详情,我们可以继续使用JaCoco的明细报表。
在官方Demo中,我们发现,报表数据实际上都被解析到了IBundleCoverage中,所以,我们只需要遍历IBundleCoverage数据,就可以拿到JaCoco的统计数据,IBundleCoverage的统计维度和它原生的报表结构类似,最外层是packages数据,内部遍历是sourceFiles数据,在到内部,就能拿到行数据,在行数据中,就可以拿到该行是否被覆盖的状态,OK,顺着这个思路,我们就可以自己来统计相关的覆盖率数据了,在遍历的过程中,我们可以使用一些Map来保存遍历出来的数据,最后输出到文件中,通过自定义的HTML文件展示出来。
核心代码如下所示。
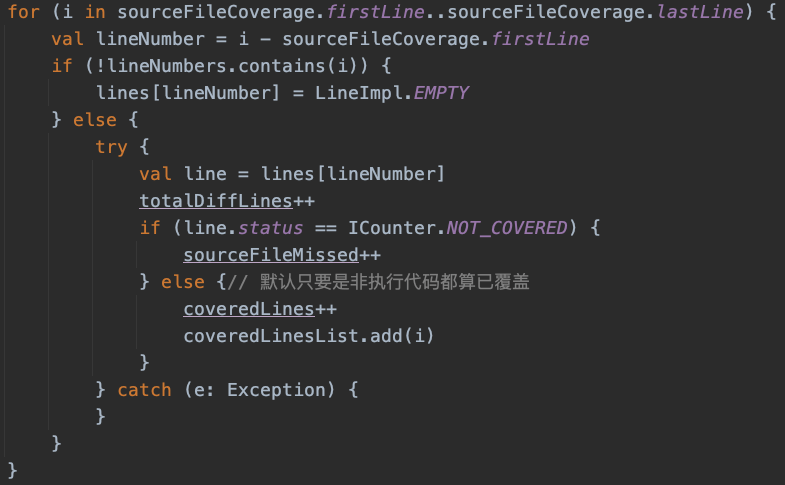
image-20210819114534934
这里有几个细节需要注意:
sourceFiles的firstLine和lastLine,封装了可执行的所有代码起始值(因为字节码中是不包含import和package信息的),所以这样会导致git diff信息中的import等修改不会被遍历到,这部分数据默认为已执行,需要手动处理掉
前面分析了我们的增量逻辑,在插桩时,只对文件做增量,所以这个文件主要有修改,那么整个文件都会被插桩,而在JaCoco生成每个文件的覆盖率信息时,需要对行做过滤,将不在diff文件中的行设置为Empty,取消覆盖率的高亮显示
在统计覆盖率时,我们进行了包容处理,即只要不是完全未执行的代码,我们都认为是已执行,这样做的原因主要是因为PARTLY_COVERED在Kotlin中经常会因为一些语法糖而产生一些无效的标识,而且有些场景下,一个条件分支的部分执行,就已经完成了逻辑的处理,所以,这样的计算也是合理的
最终我们会把遍历出来的数据写入一个文件,这样再通过自定义的HTML文件展示这个一个数据文件即可,这里还有一点需要注意,那就是HTML不能访问本地的文件系统(跨域问题),所以这里使用import js的方式引入数据文件。
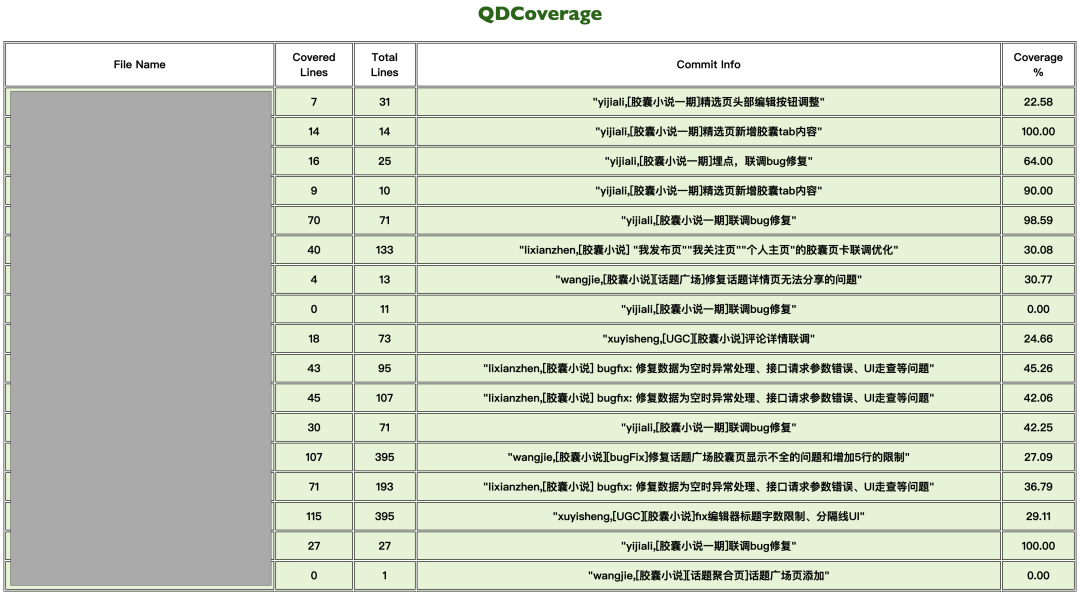
image-20211122111104225
上面这张图就是最终生成的覆盖率报告,点击相关类,就可以跳转到相关的类详细覆盖率文件界面,这里是复用的JaCoco覆盖率展示页面,这里不再赘述。
精准化测试的作用
精准化测试对开发和测试的收益如下:
将黑盒测试转化为白盒测试
统计到行,提高了发现问题的精读和效率
提升了测试回归用例的效率
反向约束了代码规范
在精准化测试平台的迭代过程中,通过覆盖率文件的分析,发现了很多在一般测试流程中很难发现的问题,下面简单的列举一些在测试过程中发现的问题。
场景展示
「更多」按钮的点击事件和无actionurl时隐藏的逻辑没覆盖
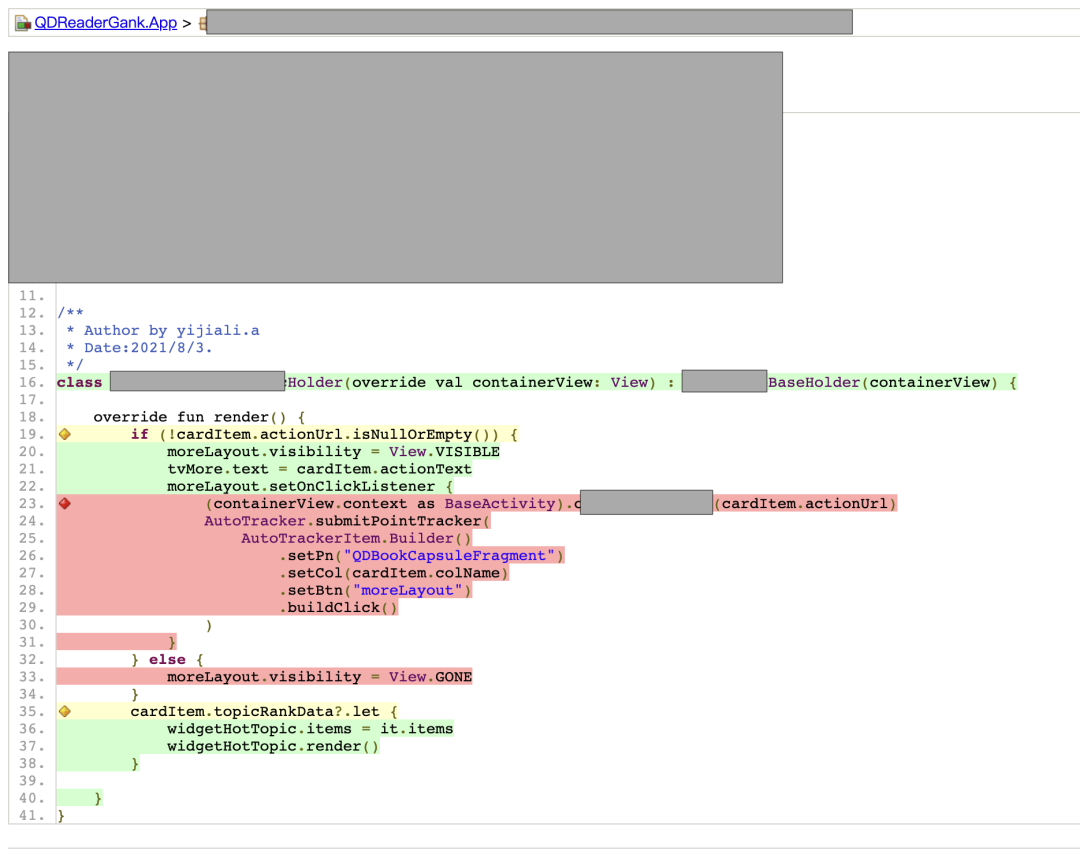
image-20211122112333343
代码冗余,同样的代码,方法名不同,且未被调用

image-20211122112406556
代码逻辑不对,网络异常后无需再绑定数据

image-20211122112452914
上面这些案例就是通过精准化测试平台发现的一些问题,这些问题大致可以分为下面几类。
代码分支未覆盖,该部分逻辑未得到验证
代码冗余,开发可以发现潜在的不规范代码
修改了与提交信息不同的修改,场景不会被测试用例覆盖
银弹?
在开发精准化测试平台的过程中,我们也发现了这个方案的一些不足,这也印证了那句老生常谈的话——软件开发领域没有永恒的银弹。
首先,精准化测试在没有自动化测试平台的基础上,如果测试代码频繁修改,那么会导致增量覆盖率文件存在一些问题。因为精准化测试报告与代码版本是一一对应的关系,这就好比是医院的验血报告,报告只对当次提交的血液检测样本负责,覆盖率报告也是同样的道理。
其次,精准化测试平台在多人协作的场景下有一些不足,覆盖率记录文件在本地设备中,所以多人协同测试的场景下,本地覆盖率文件难以合并。
最后,精准化测试报告的分析依赖人工,需要测试和开发共同分析报告,找出潜在的问题风险。
介于上面提到的问题,我们梳理了当前精准化测试平台的使用规范和适用场景。
在集成测试阶段,通过精准化测试平台,严格把控新的代码提交,保证合入代码合格且经过验证
在功能测试阶段,尽可能单人单业务测试,针对每次测试的精准化报告,来分析潜在的风险,和发现潜在的问题
通过自动化测试,回归已测场景,从而产出迭代的覆盖率报告
同时,基于这些问题和限制,我们也在进一步拓展精准化测试平台的功能,在后续迭代中,将在下面几个方面来逐渐提高精准化测试平台的功能,争取从「能用」到「可用」再到「好用」,将精准化测试平台打造成提升敏捷开发效率的利器。
增加代码调用链管理分析工具和测试用例数据库的搭建,为搭建「代码」——「测试用例」的映射关系做准备
搭建自动化测试平台,进一步降低测试的回归工作量,同时利用自动化测试,降低精准化测试覆盖率数据的生成难度
自动化分析覆盖率报告,智能识别未覆盖代码,通过「代码」——「测试用例」映射库,识别未覆盖的测试用例,提交给测试做进一步的验证
以上。
在此感谢起点客户端团队和起点测试团队在精准化测试平台的搭建中提供的宝贵建议和帮助。
向大家推荐下我的网站 https://xuyisheng.top/ 点击原文一键直达
专注 Android-Kotlin-Flutter 欢迎大家访问
往期推荐
本文原创公众号:群英传,授权转载请联系微信(Tomcat_xu),授权后,请在原创发表24小时后转载。
< END >
作者:徐宜生
更文不易,点个“三连”支持一下👇