
如何使用 sklearn 优雅地进行数据挖掘?

文章来自:天池大数据科研平台
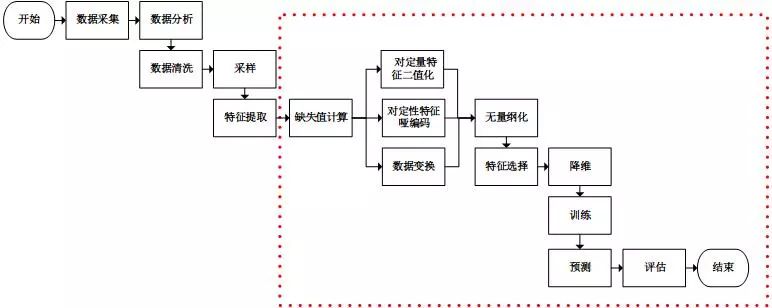
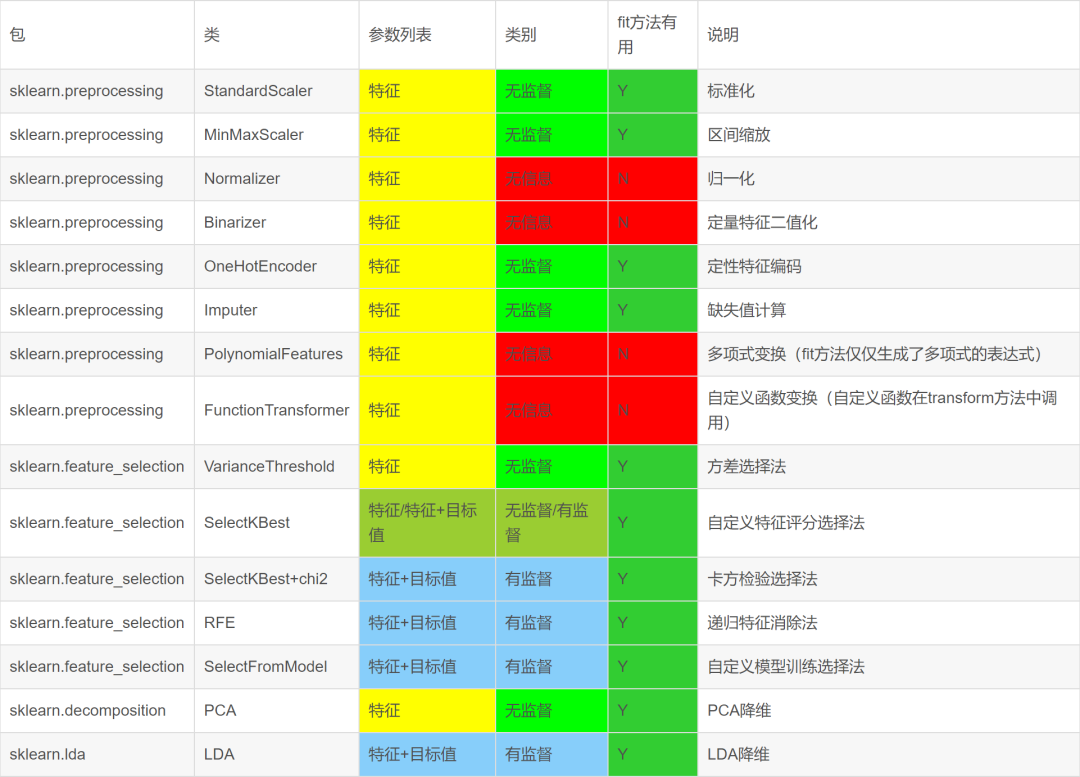
一、使用sklearn数据挖掘
def fit(self, X, y=None):
"""Do nothing and return the estimator unchanged
This method is just there to implement the usual API and hence
work in pipelines."""
X = check_array(X, accept_sparse='csr')
return self
在此,我们仍然使用IRIS数据集来进行说明。为了适应提出的场景,对原数据集需要稍微加工:
ffrom numpy import hstack, vstack, array, median, nan
from numpy.random import choice
from sklearn.datasets import load_iris
iris = load_iris()
#特征矩阵加工
#使用vstack增加一行含缺失值的样本(nan, nan, nan, nan)
#使用hstack增加一列表示花的颜色(0-白、1-黄、2-红),花的颜色是随机的,意味着颜色并不影响花的分类
iris.data = hstack((choice([0, 1, 2], size=iris.data.shape[0]+1).reshape(-1,1), vstack((iris.data, array([nan, nan, nan, nan]).reshape(1,-1)))))
#目标值向量加工
#增加一个目标值,对应含缺失值的样本,值为众数
iris.target = hstack((iris.target, array([median(iris.target)])))
并行处理,流水线处理,自动化调参,持久化是使用sklearn优雅地进行数据挖掘的核心。并行处理和流水线处理将多个特征处理工作,甚至包括模型训练工作组合成一个工作(从代码的角度来说,即将多个对象组合成了一个对象)。
在组合的前提下,自动化调参技术帮我们省去了人工调参的反锁。训练好的模型是贮存在内存中的数据,持久化能够将这些数据保存在文件系统中,之后使用时无需再进行训练,直接从文件系统中加载即可。
二、并行处理
pipeline包提供了FeatureUnion类来进行整体并行处理:
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
from sklearn.pipeline import FeatureUnion
#新建将整体特征矩阵进行对数函数转换的对象
step2_1 = ('ToLog', FunctionTransformer(log1p))
#新建将整体特征矩阵进行二值化类的对象
step2_2 = ('ToBinary', Binarizer())
#新建整体并行处理对象
#该对象也有fit和transform方法,fit和transform方法均是并行地调用需要并行处理的对象的fit和transform方法
#参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
step2 = ('FeatureUnion', FeatureUnion(transformer_list=[step2_1, step2_2]))
from sklearn.pipeline import FeatureUnion, _fit_one_transformer, _fit_transform_one, _transform_one
from sklearn.externals.joblib import Parallel, delayed
from scipy import sparse
import numpy as np
#部分并行处理,继承FeatureUnion
class FeatureUnionExt(FeatureUnion):
#相比FeatureUnion,多了idx_list参数,其表示每个并行工作需要读取的特征矩阵的列
def __init__(self, transformer_list, idx_list, n_jobs=1, transformer_weights=None):
self.idx_list = idx_list
FeatureUnion.__init__(self, transformer_list=map(lambda trans:(trans[0], trans[1]), transformer_list), n_jobs=n_jobs, transformer_weights=transformer_weights)
#由于只部分读取特征矩阵,方法fit需要重构
def fit(self, X, y=None):
transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list)
transformers = Parallel(n_jobs=self.n_jobs)(
#从特征矩阵中提取部分输入fit方法
delayed(_fit_one_transformer)(trans, X[:,idx], y)
for name, trans, idx in transformer_idx_list)
self._update_transformer_list(transformers)
return self
#由于只部分读取特征矩阵,方法fit_transform需要重构
def fit_transform(self, X, y=None, **fit_params):
transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list)
result = Parallel(n_jobs=self.n_jobs)(
#从特征矩阵中提取部分输入fit_transform方法
delayed(_fit_transform_one)(trans, name, X[:,idx], y,
self.transformer_weights, **fit_params)
for name, trans, idx in transformer_idx_list)
Xs, transformers = zip(*result)
self._update_transformer_list(transformers)
if any(sparse.issparse(f) for f in Xs):
Xs = sparse.hstack(Xs).tocsr()
else:
Xs = np.hstack(Xs)
return Xs
#由于只部分读取特征矩阵,方法transform需要重构
def transform(self, X):
transformer_idx_list = map(lambda trans, idx:(trans[0], trans[1], idx), self.transformer_list, self.idx_list)
Xs = Parallel(n_jobs=self.n_jobs)(
#从特征矩阵中提取部分输入transform方法
delayed(_transform_one)(trans, name, X[:,idx], self.transformer_weights)
for name, trans, idx in transformer_idx_list)
if any(sparse.issparse(f) for f in Xs):
Xs = sparse.hstack(Xs).tocsr()
else:
Xs = np.hstack(Xs)
return Xs
from numpy import log1p
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
#新建将部分特征矩阵进行独热编码的对象
step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
#新建将部分特征矩阵进行对数函数转换的对象
step2_2 = ('ToLog', FunctionTransformer(log1p))
#新建将部分特征矩阵进行二值化类的对象
step2_3 = ('ToBinary', Binarizer())
#新建部分并行处理对象
#参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
#参数idx_list为相应的需要读取的特征矩阵的列
step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
三、流水线处理
from numpy import log1p
from sklearn.preprocessing import Imputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
#新建计算缺失值的对象
step1 = ('Imputer', Imputer())
#新建将部分特征矩阵进行定性特征编码的对象
step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
#新建将部分特征矩阵进行对数函数转换的对象
step2_2 = ('ToLog', FunctionTransformer(log1p))
#新建将部分特征矩阵进行二值化类的对象
step2_3 = ('ToBinary', Binarizer())
#新建部分并行处理对象,返回值为每个并行工作的输出的合并
step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
#新建无量纲化对象
step3 = ('MinMaxScaler', MinMaxScaler())
#新建卡方校验选择特征的对象
step4 = ('SelectKBest', SelectKBest(chi2, k=3))
#新建PCA降维的对象
step5 = ('PCA', PCA(n_components=2))
#新建逻辑回归的对象,其为待训练的模型作为流水线的最后一步
step6 = ('LogisticRegression', LogisticRegression(penalty='l2'))
#新建流水线处理对象
#参数steps为需要流水线处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
pipeline = Pipeline(steps=[step1, step2, step3, step4, step5, step6])
四、自动化调参
from sklearn.grid_search import GridSearchCV
iris = load_iris()
#新建网格搜索对象
#第一参数为待训练的模型
#param_grid为待调参数组成的网格,字典格式,键为参数名称(格式“对象名称__子对象名称__参数名称”),值为可取的参数值列表
grid_search = GridSearchCV(pipeline, param_grid={'FeatureUnionExt__ToBinary__threshold':[1.0, 2.0, 3.0, 4.0], 'LogisticRegression__C':[0.1, 0.2, 0.4, 0.8]})
#训练以及调参
grid_search.fit(iris.data, iris.target)
五、持久化
#持久化数据
#第一个参数为内存中的对象
#第二个参数为保存在文件系统中的名称
#第三个参数为压缩级别,0为不压缩,3为合适的压缩级别
dump(grid_search, 'grid_search.dmp', compress=3)
#从文件系统中加载数据到内存中
grid_search = load('grid_search.dmp')
⭐回顾
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“小詹学Python”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心。

评论