唯快不破,聊聊pandas的迭代效率
共
1548字,需浏览
4分钟
·
2021-06-19 22:00
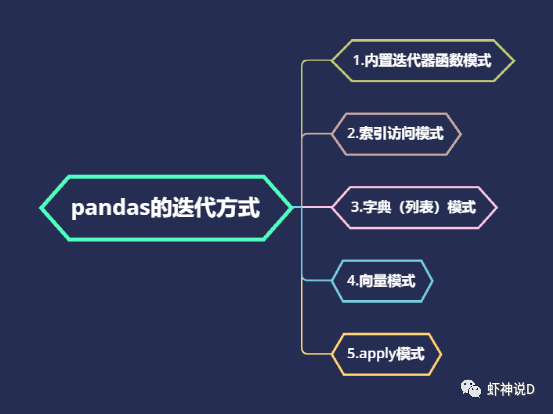
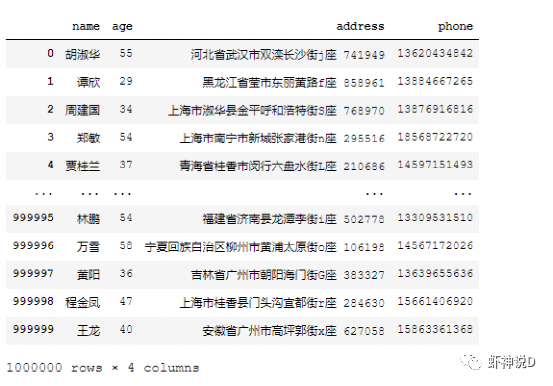
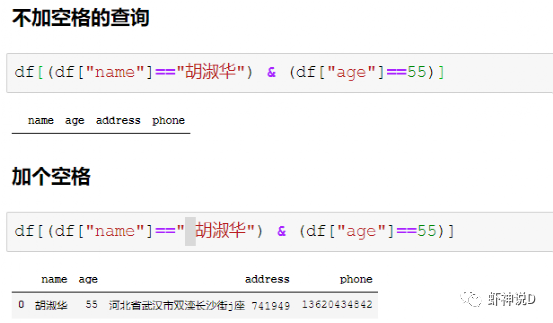
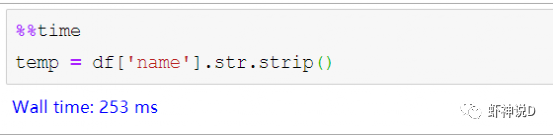
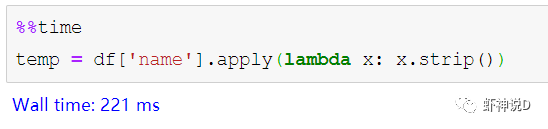
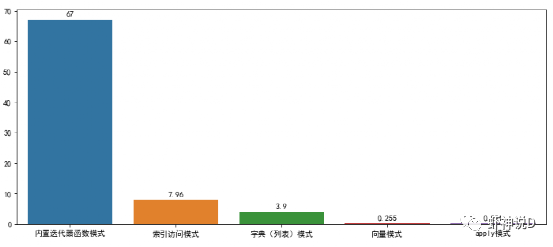
pandas这个包,说老实话,挺坑人的……主要是你一用它,就会上瘾,然后不管啥情况,只要有可能靠上边,你就会把其他方式给忘记了,比如虾神近期发现,自己都不太会写循环迭代了……这就是被pandas给惯坏的……今天来聊一个三代语言最常见的,但是四代语言基本上不怎么用的,而且又是最考验程序性能的话题:迭代。pandas的迭代设计很不好(或者说,是Python本身的性能问题),所以如果有可能,最好不要用直接迭代这种方式来处理Pandas的DataFrame。这里用Faker模拟数据工具包,模拟了100万条中文人员信息数据,如下:其中,在name这个列,我随机在前后增加了一个空格,也就是说,模拟这份数据里面,有多了空格的脏数据存在,这种脏数据对我们的查询影响很大,如下所示:胡淑华前面有一个空格,如果不处理,在查询的时候,会导致这种情况:所以,我们要把name这个列的前后空格给去掉,下面我们通过这个例子,来说明pandas的迭代效率问题。第一种方式,是最常见的,由Pandas内置的迭代器函数,主要有以下几种:literrows(): 将DataFrame迭代为(insex, Series)对。litertuples(): 将DataFrame迭代为元祖。literitems(): 将DataFrame迭代为(列名, Series)对然后我们换成第二种,只用索引来进行迭代:pandas默认会建立一个数值序列的索引,可以通过这个索引来获取所有的数据,代码如下:卧槽……7.96秒,瞬间速度就提升了8.4倍,效果拔群。接下去,尝试第三种,也就是把pandas的列,转换为字典或者列表模式来进行迭代:以上三种方式,都是传统三代语言的编码方式:由if和for组成的流程化程序编码,下面我们来看看四代语言的表现:首先是向量模式:把pandas的列转为向量,然后用向量函数来进行处理,如直接转换成字符串,然后处理:当然,有同学说,向量函数不多,很多时候我们可能都需要自定义函数来处理,所以,下面就是Pandas最最强烈推荐的:iterrows(或者其他两个内置迭代),效率是最差的,所以我们只需要做很少的代码改动,就可以直接转换为索引迭代模式或者字典迭代模式,效率就可以几十倍的提升。向量模式效率和代码简洁度都很高,但是受到API的限制,很多细粒度的方法无法实现。而效率最高的apply模式,则需要有一定的编程能力和思维,不过如果你要追求效率极限的话,不妨多学习一下这种编程模式。最后,这里推荐三代语言出身的老程序员多试用一下索引迭代或者字典迭代模式,因为如果你觉得改编码模式很麻烦的话,仅换一句话就能提升几十倍,何乐不为呢?加入知识星球【我们谈论数据科学】
400+小伙伴一起学习!
· 推荐阅读 ·
五种Pandas图表美化样式汇总
聊聊Pandas的前世今生
超简单,让别人也能访问到你的Dash应用
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报











 下载APP
下载APP