
把Go的BoltDB用在生产环境,结果18000台服务器瘫痪了

该公司在这套基础架构上拥有的服务器超过18000台,还部署和管理自己的存储设备和网络设备。
它广泛依赖HashiCorp公司开发的技术,包括 Nomad、Vault和Consul。
Consul 是一类名为服务网格(service mesh)的新兴企业技术的一部分,它在帮助厘清导致这起故障的情形方面发挥了关键作用。
像Consul这样的服务网格其功能类似网络上的交通管制员,允许各个微服务相互通信,并交换完成工作所需要的数据。
乍一看,这似乎只是运行Consul集群的硬件出现的简单故障,但更换所有服务器后,性能依然受到影响。
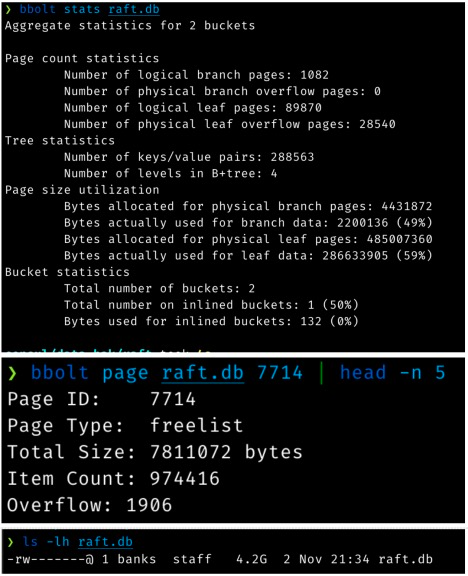
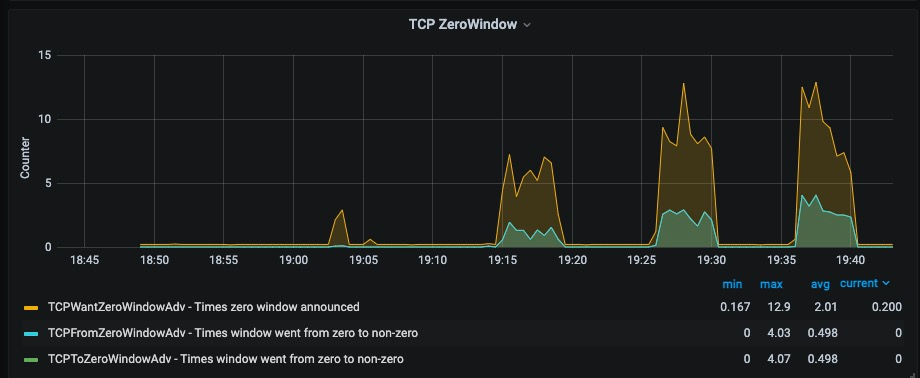
由Roblox工程师和HashiCorp工程师组成的联合团队最终查明,在Consul核心一个名为BoltDB的开源日志记录项目在设计上所做的选择导致了瓶颈,而这完全是因Roblox的独特架构而暴露出来的。
之所以花那么长的时间来诊断问题,一方面原因是团队无法确定导致问题的到底是Roblox的选择,还是Consul内部某个存在缺陷的组件。事实证明,这两个因素多少都有所牵涉。
该公司表示:“在一个Consul集群上运行所有Roblox后端服务使我们遇到了这种性质的故障。”因此,它增加了第二个数据中心来运行后端服务,还计划在那些数据中心区域里面实施可用区(AZ)。
HashiCorp还在开发新版本的Consul,以取代BoltDB。
但是尽管如此,三大云提供商的销售代表还是没有从Roblox获得任何大笔的新业务。
“总的来说,我们发现,公共云对于并不注重性能和延迟,且在规模有限的环境下运行的应用程序来说是一种很好的工具。然而,针对我们那些非常注重性能和延迟的工作负载,我们所做的选择是在本地构建和管理我们自己的基础架构,”该公司表示。


Roblox公告故障「根本原因」部分:
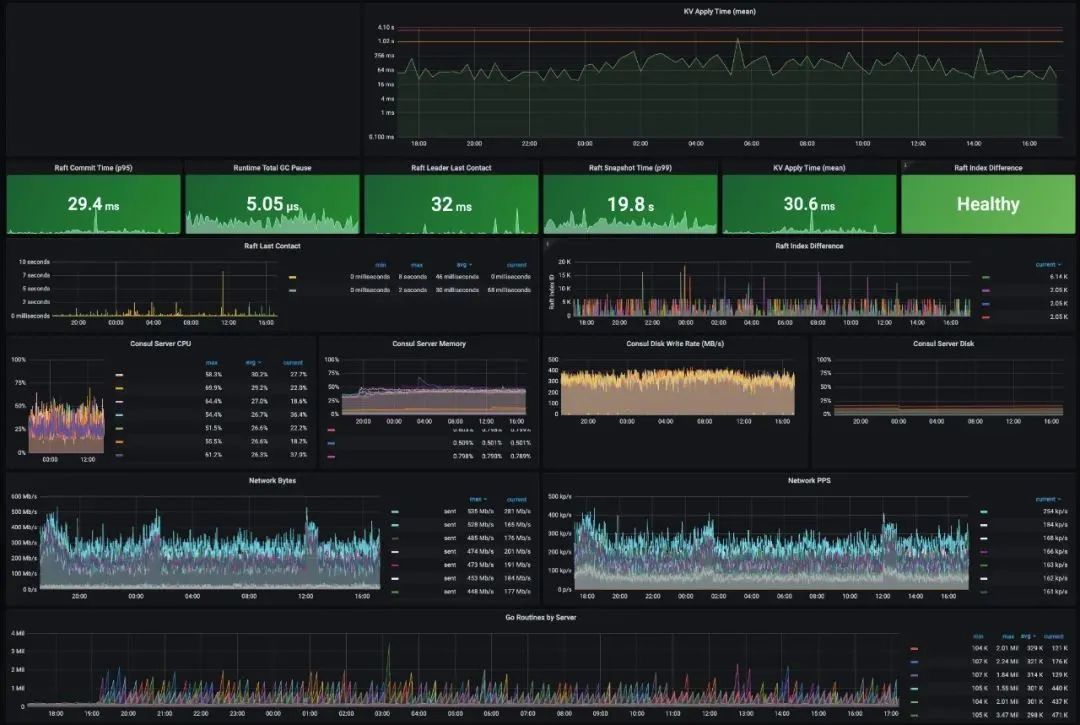
在Roblox的Consul的正常运作情况

推荐阅读