必须了解的MySQL三大日志:binlog、redo log和undo log
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」

逻辑日志:可以简单理解为记录的就是SQL语句。
物理日志:因为MySQL数据最终是保存在数据页中的,物理日志记录的就是数据页变更。
主从复制:在Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。
数据恢复:通过使用mysqlbinlog工具来恢复数据。
0:不去强制要求,由系统自行判断何时写入磁盘;
1:每次commit的时候都要将binlog写入磁盘;
N:每N个事务,才会将binlog写入磁盘。
STATMENT:基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的SQL语句会记录到binlog中。优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,从而提高了性能;缺点:在某些情况下会导致主从数据不一致,比如执行sysdate()、slepp()等。
ROW:基于行的复制(row-based replication,RBR),不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了。优点:不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题;缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨。
MIXED:基于STATMENT和ROW两种模式的混合复制(mixed-based replication,MBR),一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog。
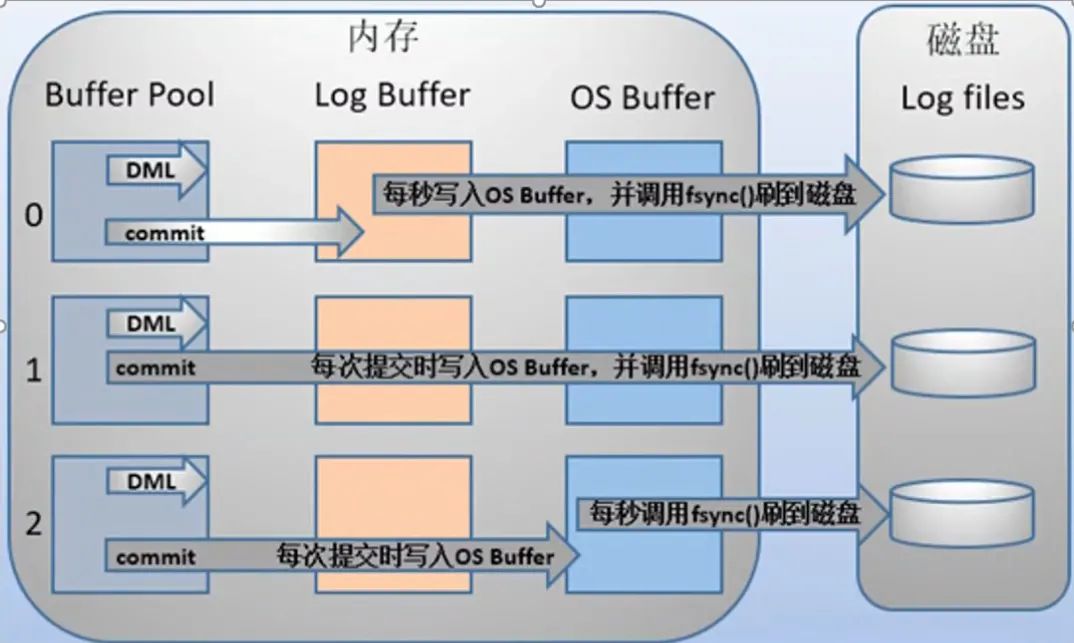
因为InnoDB是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
| 参数值 | 含义 |
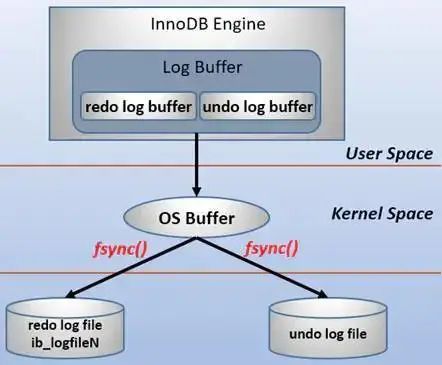
| 0(延迟写) | 事务提交时不会将redo log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到redo log file中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 |
| 1(实时写,实时刷) | 事务每次提交都会将redo log buffer中的日志写入os buffer并调用fsync()刷到redo log file中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。 |
| 2(实时写,延迟刷) | 每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到redo log file。 |
| redo log | binlog | |
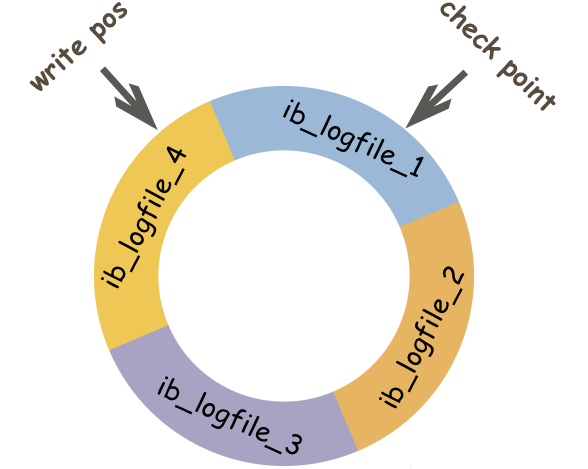
| 文件大小 | redo log的大小是固定的。 | binlog可通过配置参数max_binlog_size设置每个binlog文件的大小。 |
| 实现方式 | redo log是InnoDB引擎层实现的,并不是所有引擎都有。 | binlog是Server层实现的,所有引擎都可以使用 binlog日志。 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | binlog 通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上。 |
| 适用场景 | redo log适用于崩溃恢复(crash-safe)。 | binlog适用于主从复制和数据恢复。 |
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈