
JDK9为何要将String的底层实现由char[]改成了byte[]?
阅读本文大概需要 3.5 分钟。
来自:沉默王二
char[] 优化为了 byte[] 来存储字符串内容,为什么要这样做呢?char[] 到 byte[],最主要的目的是为了节省字符串占用的内存 。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。一、为什么要优化 String 节省内存空间
jmap -histo:live pid | head -n 10 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。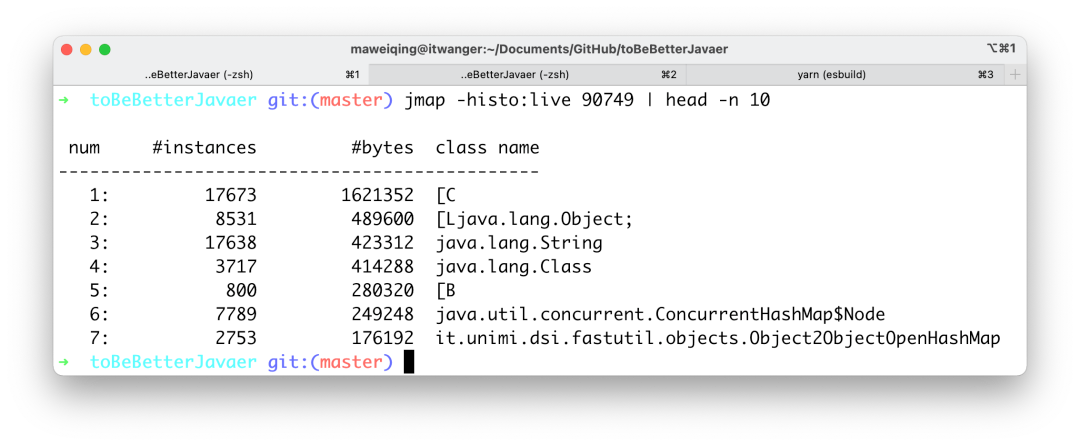
char[],所以我们可以看到内存占用排在第 1 位的就是 char 数组。char[] 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。二、byte[\] 为什么就能节省内存空间呢?
char[] 来表示 String 就导致了即使 String 中的字符只用一个字节就能表示,也得占用两个字节。char[] 优化为 byte[] 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。String name = "jack";
String name = "小二";
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;
char[] 到 byte[],中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节 。三、为什么用UTF-16而不用UTF-8呢?
如果只有一个字节,那么最高的比特位为 0; 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
0xxxxxxx:一个字节; 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1); 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
参考链接:https://www.zhihu.com/question/447224628
评论