
百万并发「零拷贝」技术系列之经典案例Netty

源 / 码农神说 文 / 韩旭

Netty在零拷贝思想上的实现可以理解为是广义的,它和wiki对零拷贝宽泛的定义特别吻合“CPU 不需要将数据从一块内存拷贝到另一块内存”,因为Netty主要是在用户空间尽量减少内存的拷贝次数,而非系统层面的用户空间和内核空间数据的拷贝。
Netty作为Java界知名的NIO网络通讯框架,凭借其高性能木秀于mina、twisted,其因素之一就如官方所述:“减少了不必要的内存拷贝”。
在零拷贝实现上,它有借助于Java NIO的tranferTo实现的FileRegion用于文件传输,也有通过巧妙设计buffer数据结构来避免由于拆分、组合而带来的拷贝。尤其是后者,因为buffer是用来化零为整降低I/O操作频率的重要技术手段,对性能的影响至关重要。
FileRegion的零拷贝是体现在系统层面的,它包装了Java NIO的FileChannel.tranferTo方法进行文件传输,从FileRegion的默认实现类DefaultFileRegion可以一探究竟。
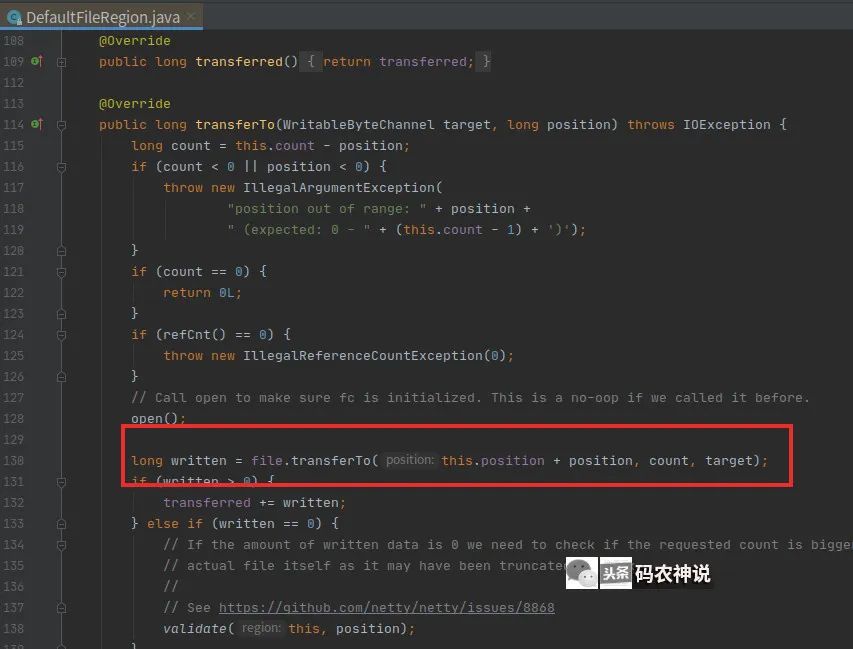
tranferTo在上一篇推文有较详细的讲解,此处不再累述。
Netty使用了它自己封装的buffer API替代了Java NIO的ByteBuffer:ByteBuf。官方列出了它的一些比较酷的特性
You can define your buffer type if necessary.根据需要可以定制自己的buffer类型。
Transparent zero copy is achieved by built-in composite buffer type.通过内建的组合类型可以实现透明的零拷贝。
A dynamic buffer type is provided out-of-the-box, whose capacity is expanded on demand, just like `StringBuffer`.它是一个开箱即用可根据需求动态扩展的buffer,就像`StringBuffer`。
There's no need to call the `flip()` method anymore.不再需要调用`flip()` 方法。
It is often faster than `ByteBuffer`.通常比`ByteBuffer`更快速。
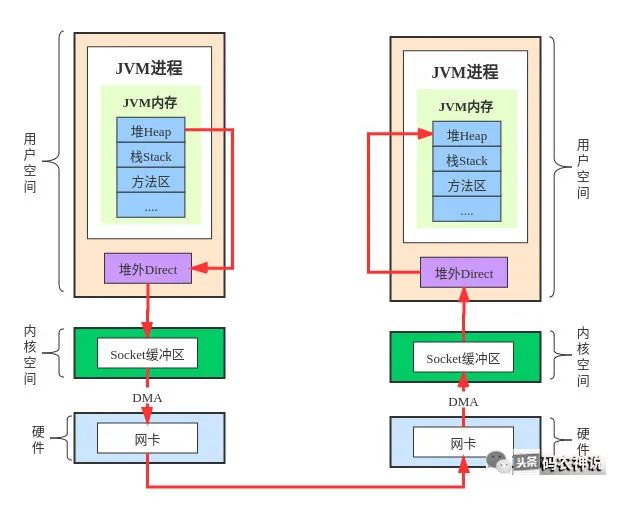
拿网络传输来说,对于传统的read/write的I/O方式,一般情况而言是这样的:Java堆内存—>用户空间的堆外内存—>内核socket缓冲区—>DMA—>网卡—>网卡—>DMA—>内核socket缓冲区—>用户空间的堆外内存—>Java堆内存。
DirectByteBuffer的使用是有一定的风险的,可能会造成OutOfMemory,官方是这样描述的
allocating many short-lived direct NIO buffers often causes an OutOfMemoryError.
堆内和堆外内存各有优势和劣势,需要根据场景自行选择

网络传输的过程中对数据的拆包、组包等操作十分常见也很频繁,Netty提供了warp、Composite和slice方法来减少数据的拷贝,达到性能的提升的目标。
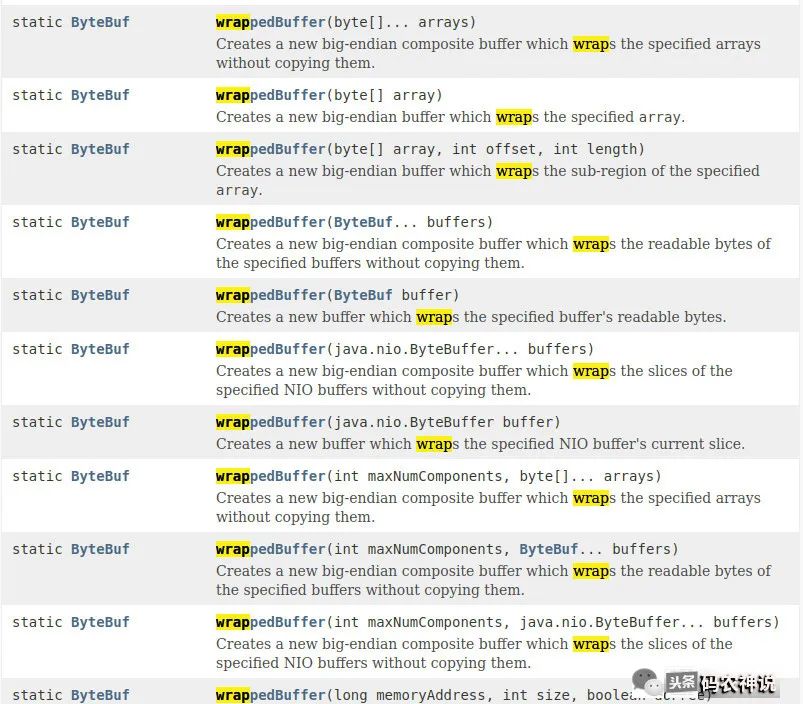
通常将一个对象比如byte数组转换成一个ByteBuffer,传统的作法是把数组拷贝到ByteBuffer对象中,而wrap的方式无须拷贝,它们共用同一块内存。
byte[] tmp=new byte[]{1,2};
//Java NIO
//传统方式(拷贝)
ByteBuffer byteBuffer=ByteBuffer.allocate(2);
byteBuffer.put(tmp);
//wrap方式
byteBuffer=ByteBuffer.wrap(tmp);
//Netty ByteBuf
//传统方式(拷贝)
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeBytes(tmp);
//wrap方式
byteBuf=Unpooled.wrappedBuffer(tmp);
CompositeByteBuf将多个ByteBuf组合成一个ByteBuf而不需要数据拷贝,每个ByteBuf都是独立存在的,只是在逻辑上的组合,提高性能的同时可以统一使用ByteBuf的API。假设有一个数据包是由三部分组成header、body、footer,它们可能是由不同的模块创建的,组合示意和代码如下
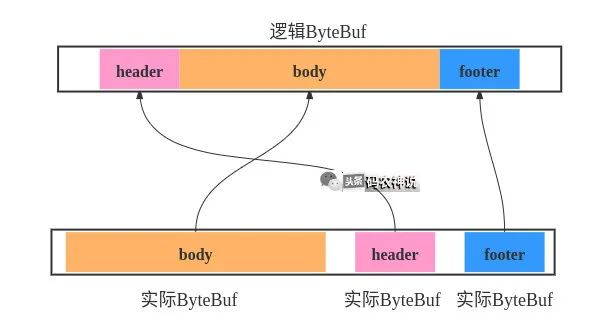
ByteBuf header = Unpooled.wrappedBuffer(tmp);
ByteBuf body = Unpooled.wrappedBuffer(tmp);
ByteBuf footer = Unpooled.wrappedBuffer(tmp);
//不建议的作法
ByteBuf wholeBuf = Unpooled.buffer(header.readableBytes()
+ body.readableBytes()+footer.readableBytes());
wholeBuf.writeBytes(header);
wholeBuf.writeBytes(body);
wholeBuf.writeBytes(footer);
//建议使用组合
CompositeByteBuf compositeByteBuf=Unpooled.compositeBuffer();
//第一个参数increaseWriterIndex,为true会自动增加writerIndexss
compositeByteBuf.addComponents(true,header,body,footer);
slice将一个ByteBuf分解为多个ByteBuf,但没有数据拷贝,而是共享同一个存储区域的,这在拆分包操作时非常有用,如上例数据包由header、body、footer三部分组成,拆分示意和代码如下
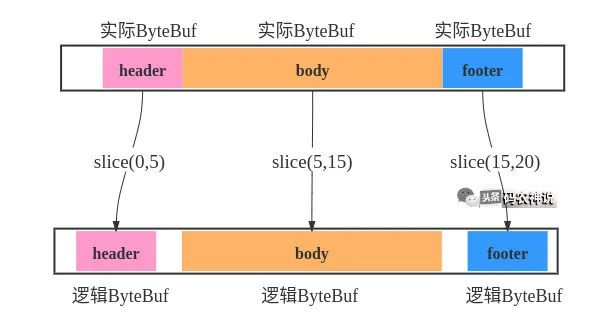
ByteBuf byteBuf4slice=.....;
ByteBuf header=byteBuf4slice.slice(0,5);
ByteBuf body=byteBuf4slice.slice(5,15);
ByteBuf footer=byteBuf4slice.slice(15,20);
Netty 4.x提供了池化的Buffer,类似于线程池或数据库连接池的思想,避免了Buffer频繁的创建和释放带来的性能低效及GC压力。池化和非池化的性能对比如下
int loop = 3000000;
byte[] content="this is a test".getBytes();
//池化buffer
long startTime = System.currentTimeMillis();
ByteBuf pooledBuf = null;
for (int i = 0; i < loop; i++) {
pooledBuf= PooledByteBufAllocator.DEFAULT.buffer(1024);
pooledBuf.writeBytes(content);
pooledBuf.release();
}
long pooledTime=System.currentTimeMillis()-startTime;
System.out.println("3百万次池化buffer消耗的时间:"+pooledTime);
//非池化buffer
startTime = System.currentTimeMillis();
ByteBuf unPooledBuf = null;
for (int i = 0; i < loop; i++) {
unPooledBuf= Unpooled.buffer(1024);
unPooledBuf.writeBytes(content);
unPooledBuf.release();
}
long unPooledTime=System.currentTimeMillis()-startTime;
System.out.println("3百万次池化buffer消耗的时间:"+unPooledTime);
//性能提升
System.out.println("池化buffer性能提升:"+Double.valueOf(
String.format("%.2f",(unPooledTime-pooledTime)/(double)unPooledTime))*100
+"%");
执行后从输出可见,池化后的buffer性能提升20%左右,非常可观
3百万次池化buffer消耗的时间:766
3百万次池化buffer消耗的时间:989
池化buffer性能提升:23.0%
— 完 —
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~