Go 每日一库之 goquery
简介
goquery是用 Go 语言编写的一个类似于 jQuery 的库。它基于 HTML 解析库net/html和 CSS 库cascadia,提供与 jQuery 相近的接口。Go 著名的爬虫框架colly就是基于 goquery 的。
快速使用
本文代码使用 Go Modules。
创建目录并初始化:
$ mkdir goquery && cd goquery
$ go mod init github.com/darjun/go-daily-lib/goquery
安装goquery库:
$ go get -u github.com/PuerkitoBio/goquery
下面我们编写一个抓取百度热榜的小程序:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
)
func BaiduHotSearch() {
res, err := http.Get("http://www.baidu.com")
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
if res.StatusCode != 200 {
log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
}
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
log.Fatal(err)
}
doc.Find(".s-hotsearch-content .hotsearch-item").Each(func(i int, s *goquery.Selection) {
content := s.Find(".title-content-title").Text()
fmt.Printf("%d: %s\n", i, content)
})
}
func main() {
BaiduHotSearch()
}
运行:
$ go run main.go
0: 熊孩子转走老妈5万块还赚了几十
1: 中使馆回应马来西亚扣留中国渔船
2: 科学家发现π行星
3: 医保局回应新冠疫苗医保全额报销
4: 阿塞拜疆第二大城市遭炮击
5: 李宇春周笔畅15年后再同框
可见,goquery 的使用非常简单:
创建一个 io.Reader,数据来源可以多样,可以从文件读取,可以是已有的字符串,还可以通过 HTTP 请求获取;调用 NewDocumentFromReader传入上面的io.Reader构造一个*goquery.Document对象;然后就可以调用 Document相关方法查询我们感兴趣的内容了。
在获取我们感兴趣的内容之前,我们必须要知道它们在 HTML 文档的什么位置。拿上面的示例来说,我感兴趣的是百度的热榜。首先打开百度:

然后,打开浏览器的开发者工具。我使用的是 Chrome 浏览器,按下 F12:
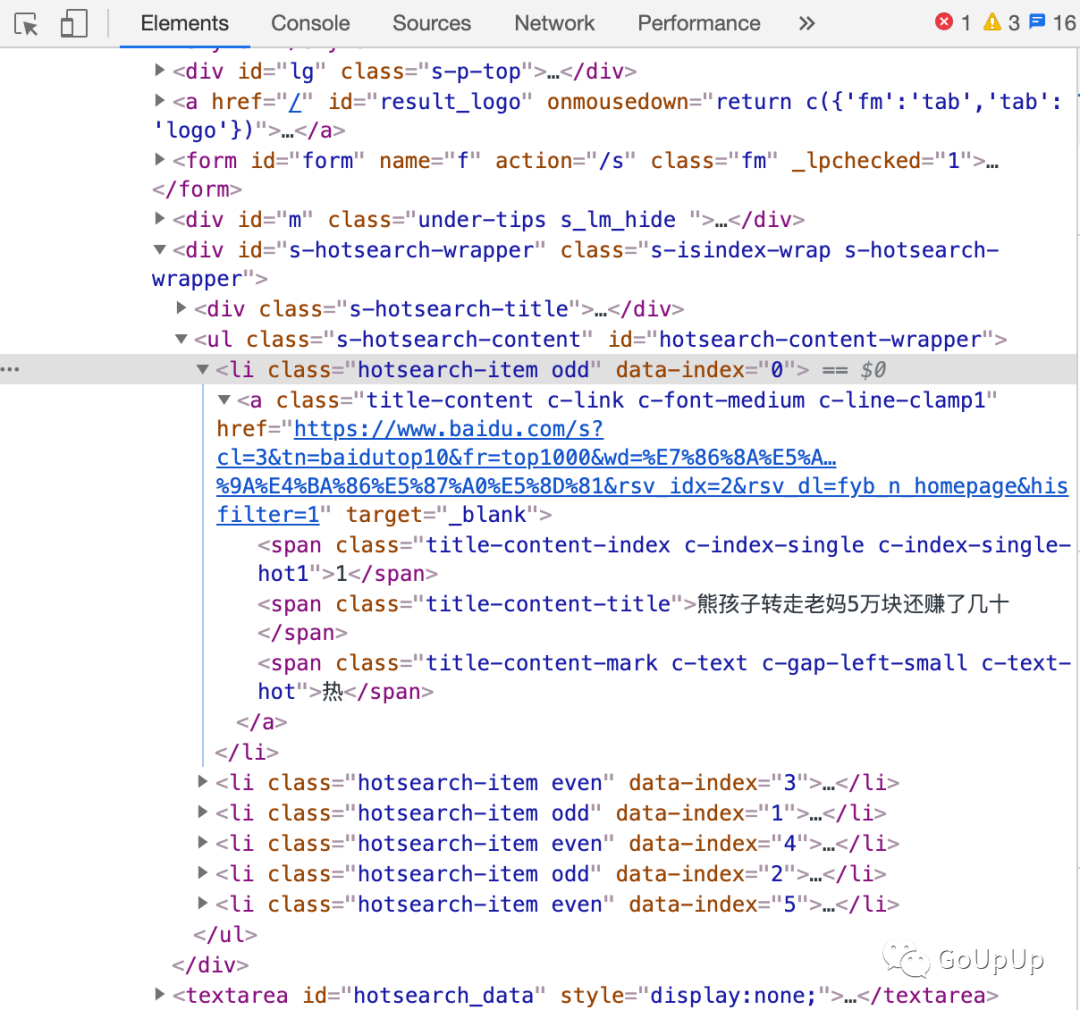
找到想要获取的内容在文档中的位置。必要时可以使用开发者工具左上角的定位按钮来定位,点击按钮,然后再点击一下我们想要定位的内容,就会自动定位到对应的 HTML 源码位置。非常方便!
然后调用相关查找方法,传入 CSS 选择器。选择器可以有多种形式,上面我使用.s-hotsearch-content .hotsearch-item定位到热榜的每个条目。这里的语法与 jQuery 的一样。.s-hotsearch-content .hotsearch-item表示查找拥有class=s-hotsearch-content的节点下的所有拥有class=hotsearch-item的节点。
当然,这里我们使用.s-hotsearch-content li也是一样的。看你喜欢。Find方法返回一个*goquery.Selection对象。接着,我们使用Selection.Each遍历每个热榜条目,输出热榜内容,即拥有class=title-content-title的span元素的内容。
基本概念
goquery 暴露了两个结构,Document和Selection和一个接口Matcher。与 jQuery 不同的是,net/html 包解析 HTML 返回的是一个个节点,而不是一个完整的 DOM 树。所以 jQuery 中的各种状态操作函数在 goquery 中是没有对应的方法的,例如height/css/detach等。
另外,jQuery 有一个显著的特点,它根据传入参数的个数和类型的不同实现不同的功能。goquery 采用静态类型的编译型语言 Go,如果也采用这种方式,静态语言的优势就发挥不出来了。为此,goquery 在方法命名上做了一些约定:
jQuery 中可以不带参数调用的函数,在 goquery 也就是相同的名字,例如 Prev()。接受一个字符串选择器参数的版本在 goquery 中命名为XxxFiltered(),例如PrevFiltered();jQuery 只接受一个参数的函数,在 goquery 有相同的名字,例如 Is();jQuery 中接受一个 jQuery 对象作为参数的函数,在 goquery 中被命名为 XxxSelection(),并且接受一个*Selection类型的参数,例如FilterSelection();jQuery 中接受一个 DOM 元素作为参数的函数,在 goquery 中被命名为 XxxNodes(),并且接受一个类型为*html.Node的可变长参数,例如FilterNodes();jQuery 中接受一个函数作为参数的函数,在 goquery 中被命名为 XxxFunction(),并且接受一个函数作为参数,例如FilterFunction();goquery 中可以用选择器调用的函数有一个接受 Matcher类型参数的版本,命名为XxxMatcher(),例如IsMatcher()。
了解 jQuery 的童鞋,熟悉了上面的约定后,使用 goquery 基本就没有什么问题了。
编码
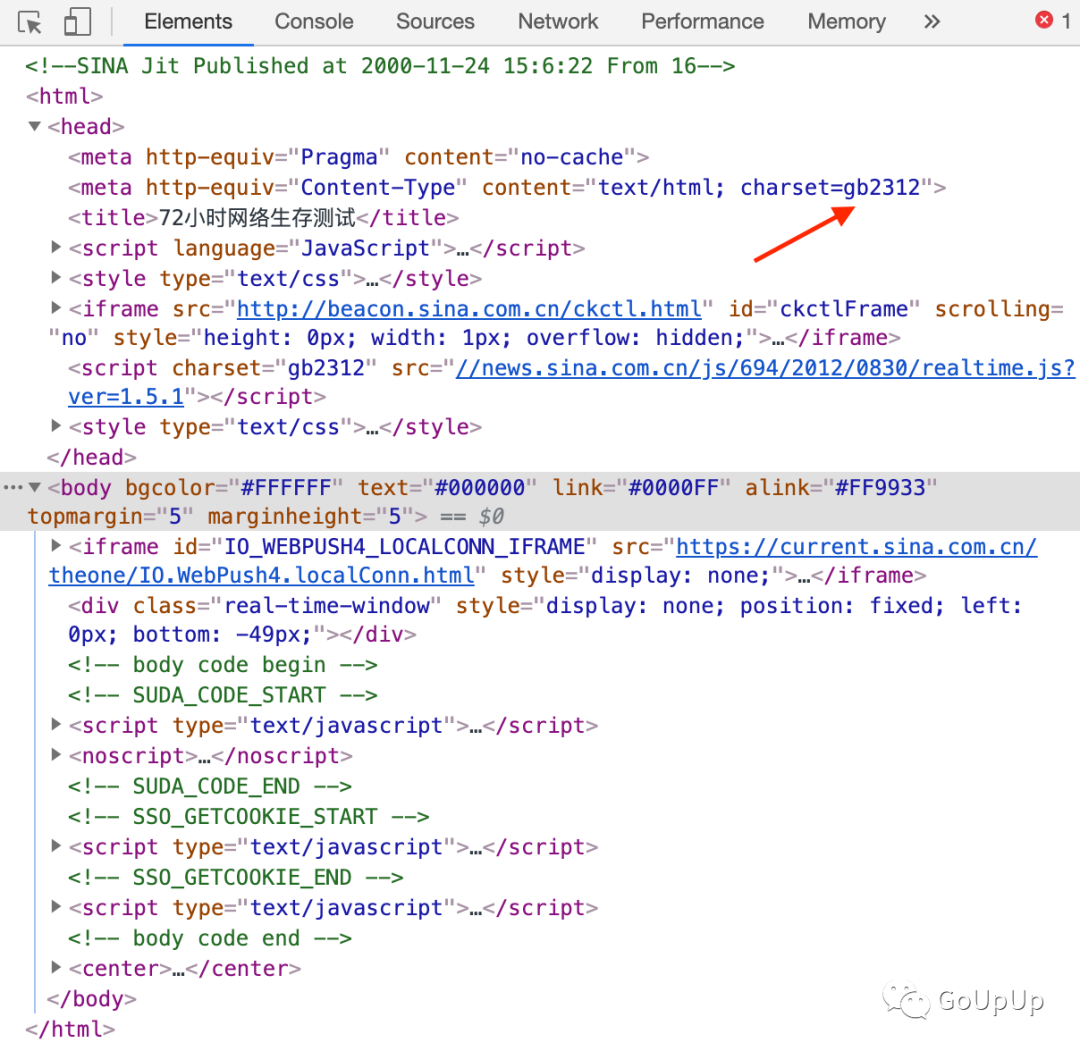
由于 net/html 要求使用 UTF-8 编码,goquery 也是如此。我们需要保证传给 goquery 的 HTML 源字符串是 UTF-8 编码的。现在已经很少有非UTF-8 编码的网页了。在早些时候,国内很多网站都是使用 GB2312 或 GBK 编码。如果我们遇到了非 UTF-8 编码的网页该怎么办呢?可以使用iconv-go将字符串的编码转为 UTF-8。
我在知乎https://www.zhihu.com/question/20091439的这个回答中找到了一个 2000 年的新浪网页,72小时网络生存测试,使用 GB2312 编码:
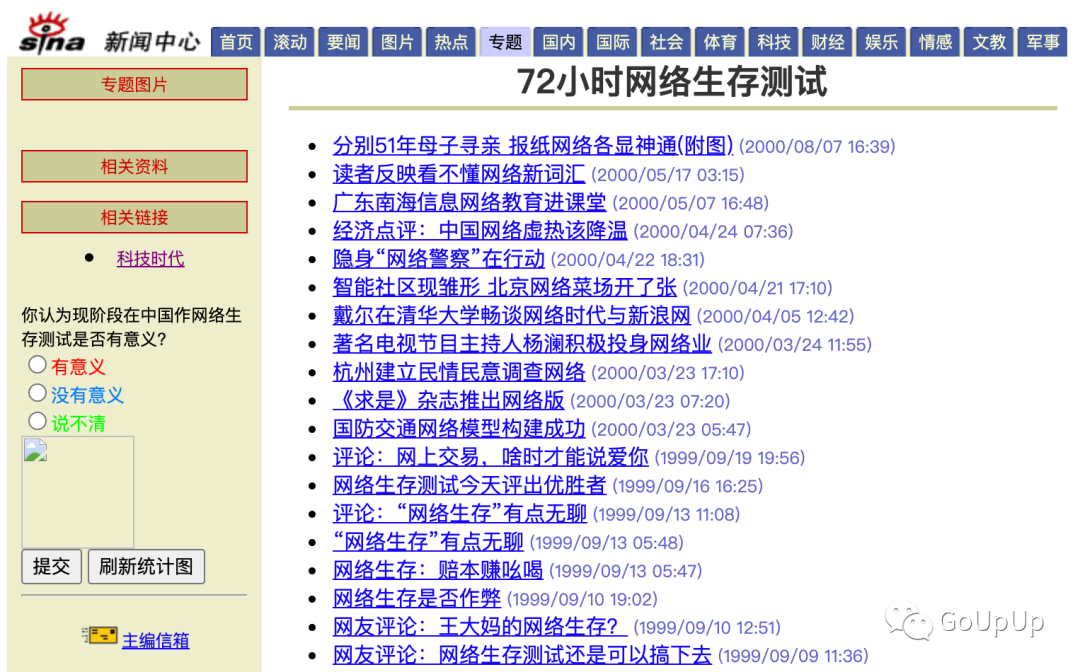
我们就来抓一下这个列表。首先安装 iconv-go:
$ go get -u github.com/djimenez/iconv-go
编码:
package main
import (
"fmt"
"log"
"net/http"
"github.com/PuerkitoBio/goquery"
"github.com/djimenez/iconv-go"
)
func SinaNewSurvival() {
res, err := http.Get("http://news.sina.com.cn/society/netsurvival")
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
if res.StatusCode != 200 {
log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
}
utf8Body, err := iconv.NewReader(res.Body, "gb2312", "utf-8")
if err != nil {
log.Fatal(err)
}
doc, err := goquery.NewDocumentFromReader(utf8Body)
if err != nil {
log.Fatal(err)
}
doc.Find(".title14 li").Each(func(i int, s *goquery.Selection) {
content := s.Find("a").Text()
time := s.Find("font").Text()
fmt.Printf("%d: %s%s\n", i, content, time)
})
}
func main() {
SinaNewSurvival()
}
基本结构与第一个例子一样,注意iconv的使用:
utf8Body, err := iconv.NewReader(res.Body, "gb2312", "utf-8")
如果我们不做这一层转换的话,最后输出会是乱码。运行:
$ go run main.go
0: 分别51年母子寻亲 报纸网络各显神通(附图) (2000/08/07 16:39)
1: 读者反映看不懂网络新词汇 (2000/05/17 03:15)
2: 广东南海信息网络教育进课堂 (2000/05/07 16:48)
3: 经济点评:中国网络虚热该降温 (2000/04/24 07:36)
4: 隐身“网络警察”在行动 (2000/04/22 18:31)
5: 智能社区现雏形 北京网络菜场开了张 (2000/04/21 17:10)
6: 戴尔在清华大学畅谈网络时代与新浪网 (2000/04/05 12:42)
7: 著名电视节目主持人杨澜积极投身网络业 (2000/03/24 11:55)
8: 杭州建立民情民意调查网络 (2000/03/23 17:10)
9: 《求是》杂志推出网络版 (2000/03/23 07:20)
10: 国防交通网络模型构建成功 (2000/03/23 05:47)
11: 评论:网上交易,啥时才能说爱你 (1999/09/19 19:56)
12: 网络生存测试今天评出优胜者 (1999/09/16 16:25)
如果我们想做得通用一点,不想把网页编码写死在代码里面,可以使用x/text/encoding和x/net/html/charset这两个包去猜测网页的编码。安装 x/text 包,由于 x/net/html/charset 是 x/net/html 的子包,不需要再次安装了:
$ go get -u golang.org/x/text
工具函数:
func detectContentCharset(body io.Reader) string {
r := bufio.NewReader(body)
if data, err := r.Peek(1024); err == nil {
if _, name, _ := charset.DetermineEncoding(data, ""); len(name) != 0 {
return name
}
}
return "utf-8"
}
func DecodeHTMLBody(body io.Reader, charset string) (io.Reader, error) {
if charset == "" {
charset = detectContentCharset(body)
}
e, err := htmlindex.Get(charset)
if err != nil {
return nil, err
}
if name, _ := htmlindex.Name(e); name != "utf-8" {
body = e.NewDecoder().Reader(body)
}
return body, nil
}
charset.DetermineEncoding会根据 HTML 页面中的 meta 元信息猜测网页编码。
接下来只需要把使用 iconv-go 的那行代码改为下面的即可:
utf8Body, err := DecodeHTMLBody(res.Body, "")
总结
goquery 功能强大,使用简单,是爬虫库 colly 的基石。可以用来做一些简单的爬取工作和 HTML 处理。由于过于底层,爬取大量的,复杂的网页建议还是使用 colly 来完成。
大家如果发现好玩、好用的 Go 语言库,欢迎到 Go 每日一库 GitHub 上提交 issue?
参考
goquery GitHub:https://github.com/PuerkitoBio/goquery Go 每日一库 GitHub:https://github.com/darjun/go-daily-lib
推荐阅读