
缓存穿透、击穿、雪崩、预热、更新、降级全解析
点击上方蓝色字体,选择“设为星标”




Redis是高性能的分布式内存数据库,对于内存数据库经常会出现下面几种情况,也经常会出现在Redis面试题中:缓存穿透、缓存击穿、缓存雪崩、缓存预热、缓存更新、缓存降级。本篇分别介绍这些概念以及对应的解决方案。
缓存穿透
当查询Redis中没有的数据时,该查询会下沉到数据库层,同时数据库层也没有该数据,当这种情况大量出现或被恶意攻击时,接口的访问全部透过Redis访问数据库,而数据库中也没有这些数据,我们称这种现象为"缓存穿透"。缓存穿透会穿透Redis的保护,提升底层数据库的负载压力,同时这类穿透查询没有数据返回也造成了网络和计算资源的浪费。
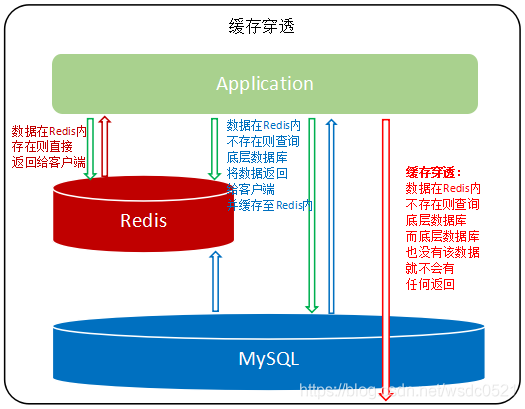
解决方案:
在接口访问层对用户做校验,如接口传参、登陆状态、n秒内访问接口的次数;
利用布隆过滤器,将数据库层有的数据key存储在位数组中,以判断访问的key在底层数据库中是否存在;
第一种解决方案很好理解,这里介绍一下第二种方案,在前一篇文章中我们介绍了Redis的布隆过滤器,我们知道布隆过滤器可以判断key一定不在集合内以及key极有可能在集合内。
基于布隆过滤器,我们可以先将数据库中数据的key存储在布隆过滤器的位数组中,每次客户端查询数据时先访问Redis:
如果Redis内不存在该数据,则通过布隆过滤器判断数据是否在底层数据库内;
如果布隆过滤器告诉我们该key在底层库内不存在,则直接返回null给客户端即可,避免了查询底层数据库的动作;
如果布隆过滤器告诉我们该key极有可能在底层数据库内存在,那么将查询下推到底层数据库即可;
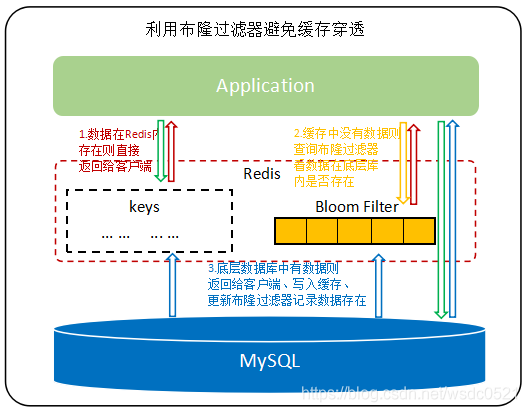
布隆过滤器有误判率,虽然不能完全避免数据穿透的现象,但已经可以将99.99%的穿透查询给屏蔽在Redis层了,极大的降低了底层数据库的压力,减少了资源浪费。
缓存击穿
缓存击穿和缓存穿透从名词上可能很难区分开来,它们的区别是:穿透表示底层数据库没有数据且缓存内也没有数据,击穿表示底层数据库有数据而缓存内没有数据。当热点数据key从缓存内失效时,大量访问同时请求这个数据,就会将查询下沉到数据库层,此时数据库层的负载压力会骤增,我们称这种现象为"缓存击穿"。
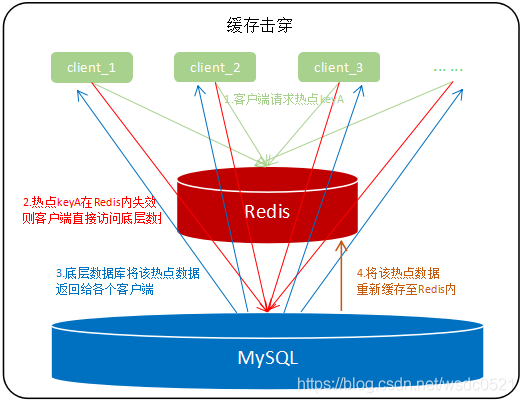
解决方案:
延长热点key的过期时间或者设置永不过期,如排行榜,首页等一定会有高并发的接口;
利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的这个数据,一旦查到数据就缓存至Redis内,避免其他大量请求同时穿过Redis访问底层数据库;
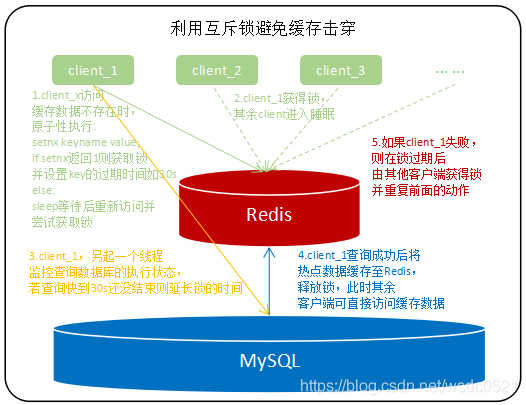
在使用互斥锁的时候需要避免出现死锁或者锁过期的情况:
使用前面文章介绍过的lua脚本或事务将获取锁和设置过期时间作为一个原子性操作(如:set kk vv nx px 30000),以避免出现某个客户端获取锁之后宕机导致的锁不被释放造成死锁现象;
另起一个线程监控获取锁的线程的查询状态,快到锁过期时间时还没查询结束则延长锁的过期时间,避免多次查询多次锁过期造成计算资源的浪费;
缓存雪崩
缓存雪崩是缓存击穿的"大面积"版,缓存击穿是数据库缓存到Redis内的热点数据失效导致大量并发查询穿过redis直接击打到底层数据库,而缓存雪崩是指Redis中大量的key几乎同时过期,然后大量并发查询穿过redis击打到底层数据库上,此时数据库层的负载压力会骤增,我们称这种现象为"缓存雪崩"。事实上缓存雪崩相比于缓存击穿更容易发生,对于大多数公司来讲,同时超大并发量访问同一个过时key的场景的确太少见了,而大量key同时过期,大量用户访问这些key的几率相比缓存击穿来说明显更大。
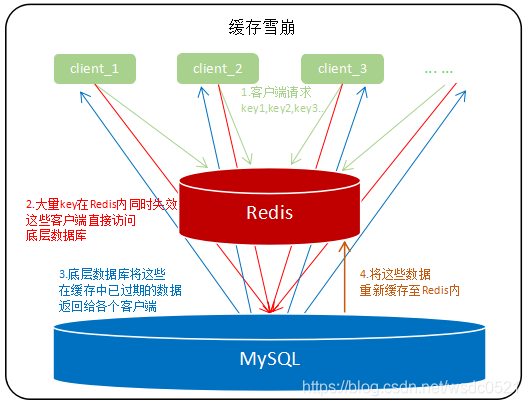
解决方案:
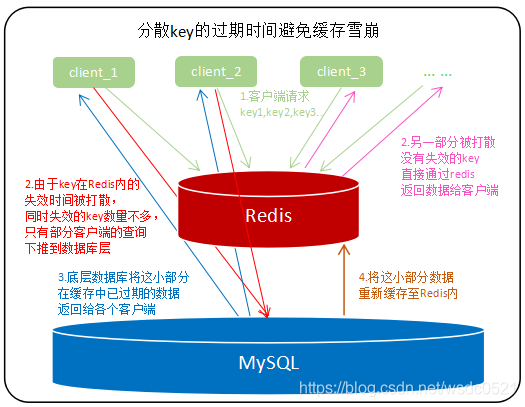
在可接受的时间范围内随机设置key的过期时间,分散key的过期时间,以防止大量的key在同一时刻过期;
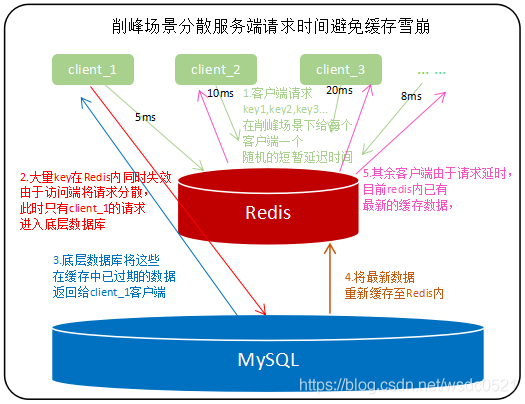
对于一定要在固定时间让key失效的场景(例如每日12点准时更新所有最新排名),可以在固定的失效时间时在接口服务端设置随机延时,将请求的时间打散,让一部分查询先将数据缓存起来;
延长热点key的过期时间或者设置永不过期,这一点和缓存击穿中的方案一样;
缓存预热
缓存预热如字面意思,当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
缓存预热的实现方式有很多,比较通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内。
缓存更新
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。如何解决并发场景下更新操作的双写一致是缓存系统的一个重要知识点。
第二步操作异常:缓存和数据的操作顺序中,第二个动作报错。如数据库被更新, 此时失效缓存的时候出错,缓存内数据仍是旧版本;
缓存更新的设计模式有四种:
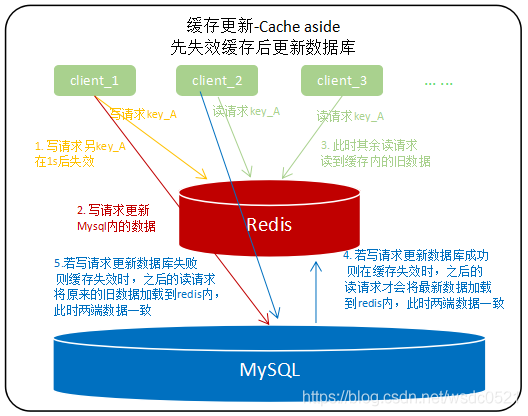
Cache aside:查询:先查缓存,缓存没有就查数据库,然后加载至缓存内;更新:先更新数据库,然后让缓存失效;或者先失效缓存然后更新数据库;
Read through:在查询操作中更新缓存,即当缓存失效时,Cache Aside 模式是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载;
Write through:在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库;
Write behind caching:俗称write back,在更新数据的时候,只更新缓存,不更新数据库,缓存会异步地定时批量更新数据库;
Cache aside:
为了避免在并发场景下,多个请求同时更新同一个缓存导致脏数据,因此不能直接更新缓存而是另缓存失效。
先更新数据库后失效缓存:并发场景下,推荐使用延迟失效(写请求完成后给缓存设置1s过期时间),在读请求缓存数据时若redis内已有该数据(其他写请求还未结束)则不更新。当redis内没有该数据的时候(其他写请求已另该缓存失效),读请求才会更新redis内的数据。这里的读请求缓存数据可以加上失效时间,以防第二步操作异常导致的不一致情况。
先失效缓存后更新数据库:并发场景下,推荐使用延迟失效(写请求开始前给缓存设置1s过期时间),在写请求失效缓存时设置一个1s延迟时间,然后再去更新数据库的数据,此时其他读请求仍然可以读到缓存内的数据,当数据库端更新完成后,缓存内的数据已失效,之后的读请求会将数据库端最新的数据加载至缓存内保证缓存和数据库端数据一致性;在这种方案下,第二步操作异常不会引起数据不一致,例如设置了缓存1s后失效,然后在更新数据库时报错,即使缓存失效,之后的读请求仍然会把更新前的数据重新加载到缓存内。
推荐使用先失效缓存,后更新数据库,配合延迟失效来更新缓存的模式
四种缓存更新模式的优缺点:
Cache Aside:实现起来较简单,但需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository);
Read/Write Through:只需要维护一个数据存储(缓存),但是实现起来要复杂一些;
Write Behind Caching:与Read/Write Through 类似,区别是Write Behind Caching的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。优点是
直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
缓存本身就是通过牺牲强一致性来提高性能,因此使用缓存提升性能,就会有数据更新的延迟性。这就需要我们在评估需求和设计阶段根据实际场景去做权衡了。
缓存降级
缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用。可以将其他次要服务的数据进行缓存降级,从而提升主服务的稳定性。
降级的目的是保证核心服务可用,即使是有损的。如去年双十一的时候淘宝购物车无法修改地址只能使用默认地址,这个服务就是被降级了,这里阿里保证了订单可以正常提交和付款,但修改地址的服务可以在服务器压力降低,并发量相对减少的时候再恢复。
降级可以根据实时的监控数据进行自动降级也可以配置开关人工降级。是否需要降级,哪些服务需要降级,在什么情况下再降级,取决于大家对于系统功能的取舍。


版权声明:
文章不错?点个【在看】吧! ?