
十四年后重返中国,SIGMOD 背后的数据库技术变迁






2000 年,我们使用了开源的数据库;随着社交增值业务的爆发增长,当时业界的开源产品包括国外的商业数据库产品,都无法满足我们的需求,2007 年,我们开始进入自研阶段,做一个像 NoSQL 这样的系统,解决高并发、金融级场景下系统面临的可用性问题,即打造了 7*24 小时高可用、高性能弹性扩展能力;2012 年,随着腾讯业务进一步发展,腾讯进入第三个阶段,即开源定制和自研,打造一个通用型的分布式数据库产品。TDSQL 从 2014 年的时候对外已经在微众银行核心系统上使用,并且逐步推广到更多的银行、保险、互联网、电商等行业企业,得到了更广泛的使用和场景验证。之后腾讯又进入了一个新的阶段,这个新的阶段就是深度开源定制 + 完全自研。直至 2017 年腾讯数据库开始重点投入基础技术研究,来从基础理论层面出发,布局前沿数据库技术创新突破。

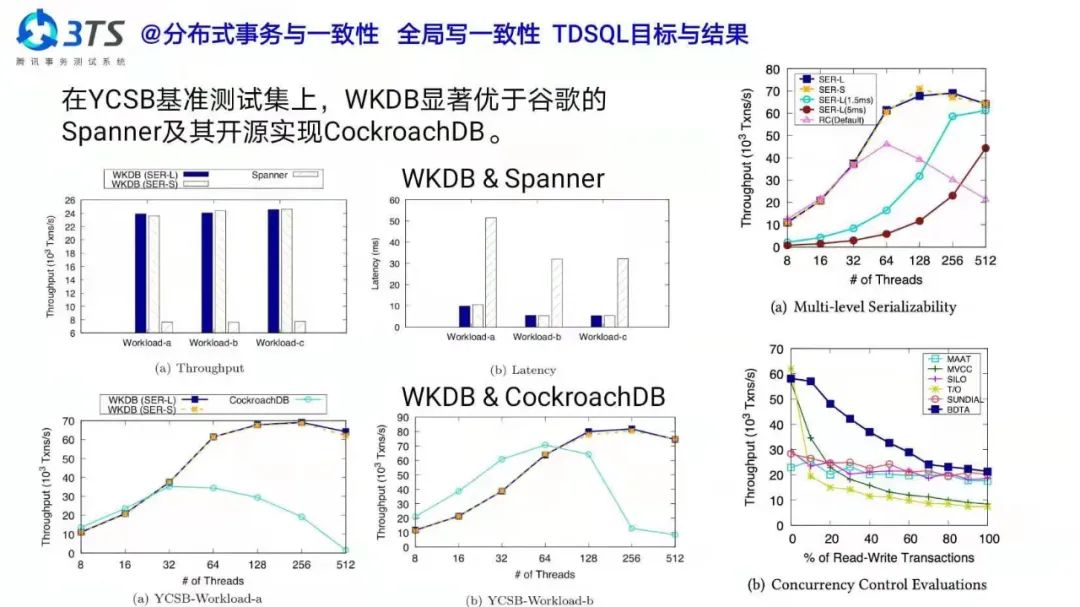
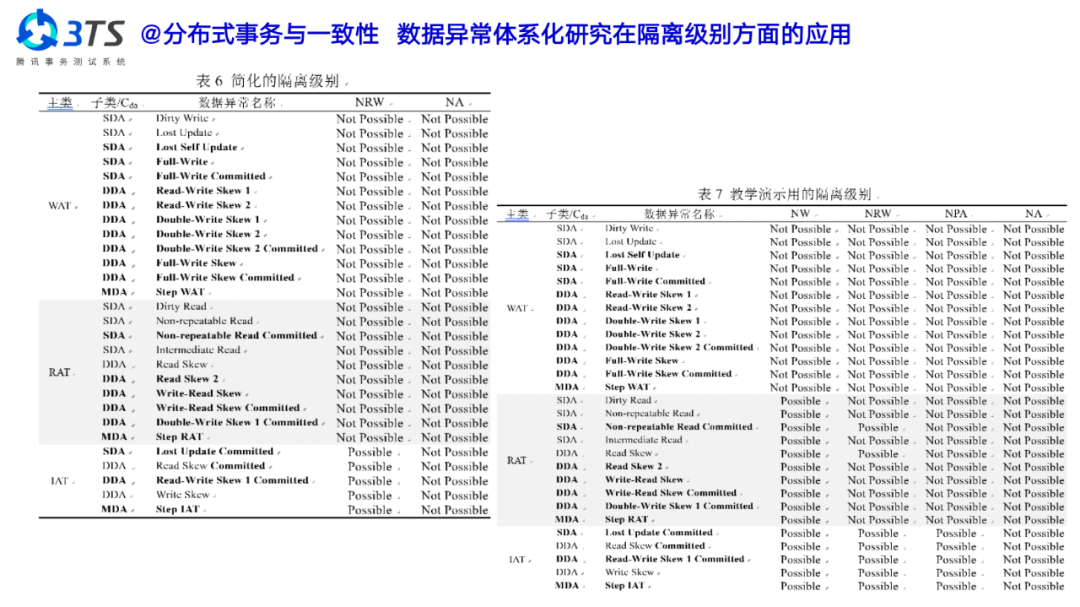
秦建斌:先看一点背景,2007 年 SIGMOD 第一次在中国北京举办,当时论文接收率仅为 14.6%;时隔了 14 年,今年第二次在中国举办,今年工程型与研究型论文接收率都有所提高。其实这背后是 SIGMOD 代表的数据管理技术本身的一些变化,随着云计算、大数据、智能计算等技术演进,作为底层技术,数据库从传统的只关注 Management Of Data 开始向 Data Science 还有 Data Engineering 方面进行了拓展。




﹀
﹀
﹀
-- 更多精彩 --

TDSQL战绩 | 微众银行断网演练,秒级切换业务零感知

首个全省一体化金融级项目,江苏人社为何选择TDSQL?
点击 阅读原文 了解更多优惠福利!!
评论