
湖仓一体 | 网易湖仓一体的探索与实践
背景介绍
数据分析从上世纪 80 年代兴起以来,大体经历了企业数仓(EDW)、数据湖(Data Lake)、以及现在的云原生数仓、湖仓一体等过程。
企业数仓是数据仓库最原始的版本,主要用于企业内部的决策支持和商业分析(BI)。企业数仓的数据放置于集中式仓库当中,并以 schema-on-write(写时模式)的方式写入。从当前的视角来看,企业数仓存在着只能处理结构化数据、集中式的存储和计算、以及成本昂贵等缺点。
数据湖是伴随着数据爆炸式增长而出现的技术,它能够存储结构化以及非结构化的数据、拥有分布式的存储、以及经济的成本。但由于其“不管后面用不用,先存储起来”的理念(schema-on-read 模式),在数据治理、数据质量方面有很多的缺失,因此在后续实际的使用当中会面临较多的问题。
湖仓一体是当前较新的理念,它的目标是解决上述企业数仓和数据湖的主要缺点,并提供企业数仓和数据湖融合的优势。使其拥有数据湖的多样化结构支持、分布式存储、低成本以及企业数仓的数据治理能力,高速 SQL 访问性能等两者的优点。同时,作为一个新兴的形态,湖仓一体自身也带来了一系列增强的功能,如事务支持(ACID),支持数据 UPDATE/DELETE,更高的数据实时性甚至流式数据的生产和消费支持等等。
在业内,最早提出湖仓一体的是 Databricks,其在 2020 年初的时候介绍了 “Lakehouse” 概念[1],可以算是业内对湖仓一体概念最早的定义和说明。在技术层面上,不同的实现方案也争相出现,目前开源且活跃度较高的湖仓一体实现方案就已有 Delta Lake、Apache Hudi 及 Apache Iceberg 等。此外阿里云、华为云等也都根据自身的技术栈提供了湖仓一体解决方案。
网易在 2020 年上半年即开始湖仓一体的探索,设计并开发了 Arctic 系统。Arctic 支持数据 update/delete,兼容用户原有 hive 表并能赋予 hive 表小时级甚至分钟级数据延迟能力。在数据实时性及能效成本方面相对原有的方案能取得大幅的提升。Arctic 相关的实现也在实际业务场景中取得了落地,积累了一定的实践经验。在实现新的湖仓一体方案过程当中,我们结合自身业务场景的需求,做了很多探索。本次我们分享一下实现过程中的一些核心功能点的思路和经验。
数据高效 update/delete
2.1 动态哈希结构
支持数据的 update / delete 可以有效的支持数据修正及支持业务 CDC 场景等,也是实现 “One Data” 应对多种上层应用场景的基础。而要在分布式海量数据存储上实现数据更新和删除功能,我们首先要面对的问题是:如何高效的定位所需修改/删除的数据?
一种方案是维护所有数据的主键索引(比如通过文件级 bloom filter 或 HBase 存储),但显而易见的是在海量的数据规模上维护主键索引代价很大,且引入第三方组件的存储会给整个系统的实现和维护带来额外的复杂度。在 Arctic 实现中,我们通过维护一个动态 hash 二叉树结构(我们称之为 Arctic Tree),将数据根据主键的 hash 值进行划分,数据分布在二叉树的结点中。这个结构的好处是,我们只需要维护每个文件各自所属结点位置信息,并附加在文件的属性上即可。Arctic Tree 结构简单示意图:

理论上,随着树的层级加大,我们可以使每个树结点只拥有一个数据文件。这是文件划分的最极端的一种情况,此时经主键 hash 后同结点的数据必然落在此文件当中。当然,实际的情况当中大可不必如此,我们可以让一个结点保留多个数据文件,只要确保一个结点的文件作为一个计算任务的算子节点输入时,对内存的要求不超过节点限制即可。
另外,随着数据的增大或减少,Arctic Tree 的数据结点还可以进行分裂(1->2^n)或合并(2^n->1)。这也是我们称之为动态 hash 二叉树结构的原因。Arctic Tree 也是 Arctic 系统中实现很多后续功能的基础。
2.2 Delete 文件的拆分及数据顺序保证
在解决数据定位效率问题后,第二个问题随之而来。变更数据和普通新增数据混合在一起容易使需要读取到内存的文件过大,引起 OOM,我们需要将不同类型数据拆分开来。由于更新数据我们可以拆解为先删除后插入,因此我们只需要拆分两种类型的数据,Insert 和 Delete。
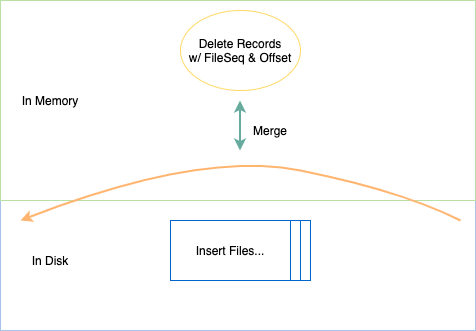
不过文件类型拆分后,如何确保数据先后顺序的正确性?由于 delete 数据和 insert 数据已分属不同的文件,我们无法简单判断其先后。如果将 delete 作用在整个 insert 文件上,那所有相关的插入数据都将被删除,导致最终错误的结果。在解决这个问题上,不同开源社区的实现走上了不同的道路。在 Arctic 中,我们通过维护一个 File Sequence + Record Offset 解决。File Sequence 由一次提交(commit)时递增生成且本次提交内的所有文件共享,并记录在 commit 元数据信息当中。Record Offset 由 Writer 在写入时赋予,只需保证单个 commit 周期内单调递增且唯一即可。File Sequence + Record Offset 就保证了数据的全局唯一性及先后顺序性。

有了 File Sequence 及 Record Offset 之后,即使插入数据与删除数据位于不同的文件,生成文件的时机不同,我们也可以根据 File Sequence + Record Offset 组成一条逻辑时间轴,以确定不同数据在时间轴上的前后顺序。另外,对于增量数据的回放而言,也只需要根据时间轴的顺序往下游进行输出即可。
数据实时性
在湖仓一体的设计当中,由于变更数据和插入数据分开进行了存放,因此,决定数据实时性的除了写入端的提交频率外,还有变更数据与插入数据的合并时机。对于两类数据的合并,我们通常有两种方式:写时复制(copy on write)和读时合并(merge on read),写时复制可以同步执行也可以异步执行,但出于写入端性能的考虑,我们一般选择异步后台执行。读时合并是实时性最优的操作类型,但由于上层在进行数据读取时,通常会有一个期望的响应时间阈值,而过多的读时合并操作会拖慢整个查询流程的性能,因此该如何去应用读时合并也需要做合理的权衡。
3.1 copy on write
在目前开源社区的实现中,copy on write 都单独设计为了一种 Action,需要用户主动调用来进行触发。而在 Arctic 中,有单独的后台服务进行 copy on write 管理,可以自动根据表中数据/文件的状态和用户的配置进行触发,对用户更加友好和更易使用。
除了调用时机可灵活配置外,在空间管理上,Arctic 也预留了不同的实现策略,比如 Arctic 支持只对表中的一个或部分分区进行 copy on write 操作,这样一来可以避免每次都对整个表进行操作,以致出现生成的整个任务过大,中间极易出现异常等问题。另外则可以满足用户某些情况下只需要及时更新某些分区数据的要求。此外,由于 copy on write 需要将所有相关文件读出,再合并写入,整体上是一个写很重的操作,也较容易引起写放大的问题。因此,对于 copy on write,一般不会频繁的去触发。总体上而言,copy on write 是一个主要面向数据小时级或 10 分钟以上级别延迟的操作。
3.2 merge on read
相对于 copy on write 而言,想要更高的实时性,就需要由 merge on read 来完成。merge on read 的实现内嵌于数据查询流程当中,在执行具体读取时进行文件范围的筛选,任务 plan 及数据合并等操作,且依赖不同的查询执行器实现略有不同。这里简单以 Arctic 中基于 Spark SQL 3.0 实现的 merge on read 介绍下实现原理。
实现 merge on read 需要对 Spark SQL 所做的扩展主要有两块,自定义 Catalog 及自定义 DataSource 数据源。Spark SQL 对于用户实现自己的扩展比较友好,都已经预留好了接口。有的人可能比较好奇,为何还要扩展 Catalog 呢?其实这是由 Arctic 需要兼容用户原有的 Hive 表所致的,因为我们需要通过自定义实现的 Catalog 进行区分用户原有的 hive 表和 Arctic 表。Spark SQL 3.x 支持了 Multiple Catalog,我们只要在 SQL 解析流程中,加入一个 ArcticCatalog,并作为用户首选的 catalog,所有的 sql 请求,都首先经过 ArcticCatalog 进行甄别,Arctic 表由 ArcticCatalog 处理,非 Arctic 表则由 ArcticCatalog 分配至默认的 SparkCatalog 进行处理即可。
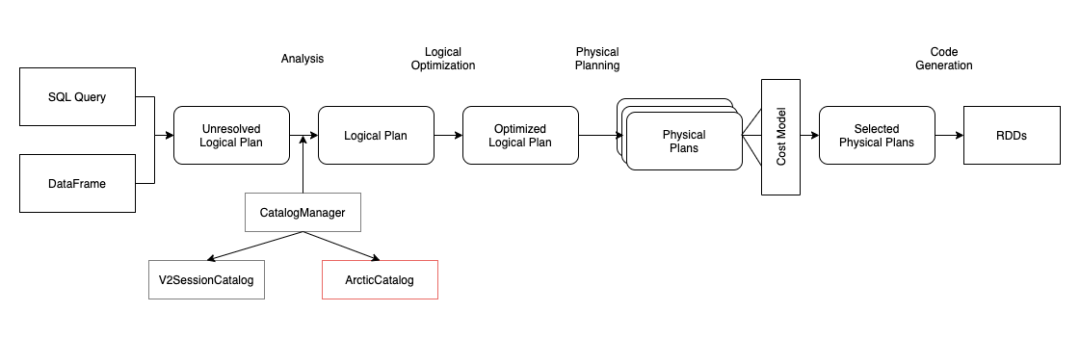
对于数据源的扩展,主要是依赖 DataSourceV2 接口。其中的核心点是扩展 spark 的 partition reader,在数据读取时,需要加上 insert/delete 数据合并逻辑。最终返回给用户一致的、正确的数据。
其他功能
除上述的几个功能外,Arctic 还支持从业务数据库(MySQL/Oracle)全自动同步全量/增量数据至 Arctic 表,支持文件治理、数据访问权限控制、ACID 特性等功能,已基本具备了作为湖仓一体基础设施的能力。
未来展望
湖仓一体技术正在蓬勃的发展,所适配的应用场景也肯定会越来越丰富。目前大家对于湖仓一体设施主要印象还是应用于 OLAP 数据分析场景,但对于我们期待的 “One Data Fit All” 的目标来说,用户的需求远不止如此。比如我们遇到的湖仓一体中的数据在满足实时性的同时,还需要能满足推荐等业务的数据”点查“需求,这也是 Arctic 后续发力的方向。未来湖仓一体技术不仅能满足高效 OLAP 的需求,还将能满足机器学习、科学计算等多种场景业务需求。
此外,Arctic 还会完善 AP 端生态,覆盖 Spark SQL,Presto 等多种查询引擎。同时也会与内部的有数大数据平台集成,基于有数平台成熟的增强可视化建模等技术,进一步降低用户的使用门槛。对于 SQL 查询性能,Arctic 也会考虑设计更优的二级索引,或是引入优秀的开源实现如 Alluxio 等作为查询缓存存储,以进一步缩短响应时间,更好的提升用户体验。
[1] https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
大鲸,网易实时数仓开发工程师,曾从事搜索系统、实时计算平台等相关工作。
