
这个关于连接池的结论,你绝对想不到
Part1 前言
在开源网站github上,有一段关于JDBC连接池的视频,演示了同等业务压力下,不同的连接池线程数设置对数据库性能的影响,并用文字进行了深入分析,得出在部分情况下,连接数/并发数并不一定是越高越好这样有意思的结论,本文主要内容为英文原文的翻译(推荐阅读原文,原文链接见文末)。
连接池是创建和管理一个连接的缓冲池的技术,这些连接准备好被任何需要它们的线程使用。
Part2 一个1万用户的测试
开发者在配置连接池的时候经常会犯下一些错误,因为理解了一些连接池参数的意义之后,实际配置的数值可能是反直觉的。
假设有一个网站总是有 10000 个用户在访问,并且 TPS 为 20000,一般都会这么考虑:连接池需要设置成多大才能承载这个业务压力?但是真相可能会非常令人意外:需要考虑的是连接池需要设置成多小。
第一轮测试使用了 2048 个线程作为连接池的配置,测试结果如下图:
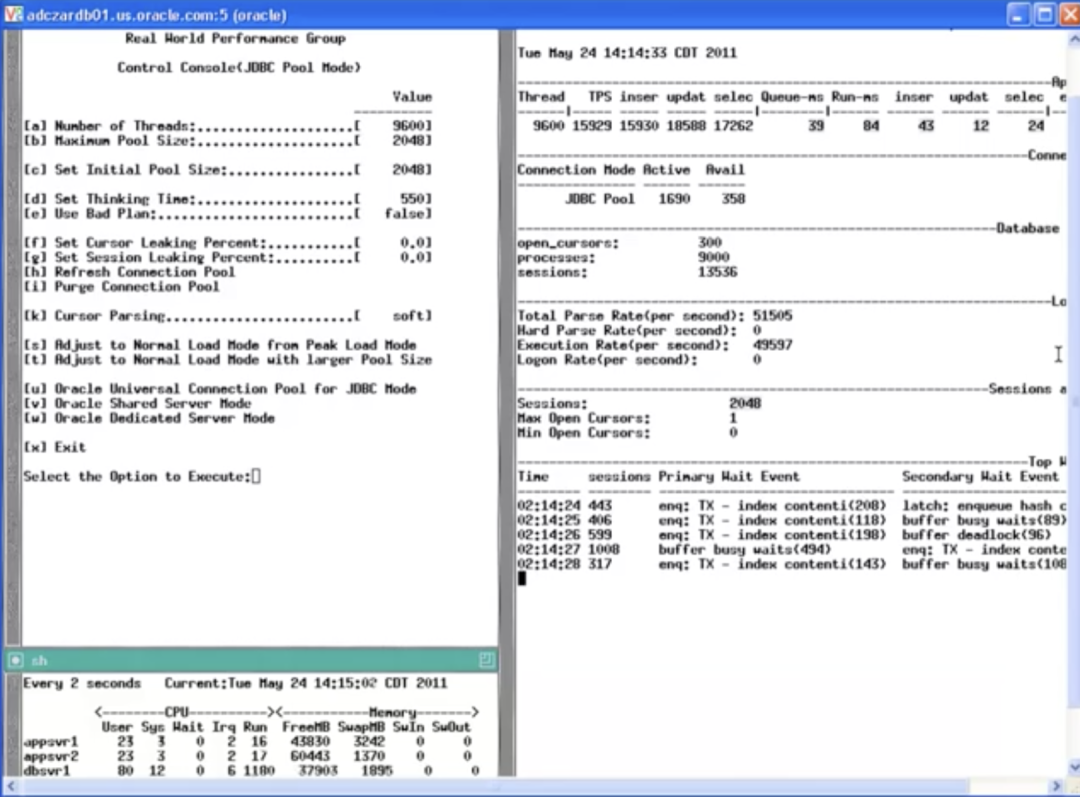
2048线程
TPS 约 160k 左右,实际 SQL 执行的时间是 78ms,在连接池队列的等待时间为 39ms,截图最下方展示了等待事件的 TOP 5,数据库层面有很多的等待事件。CPU 的使用率也很高(dbsvr1):
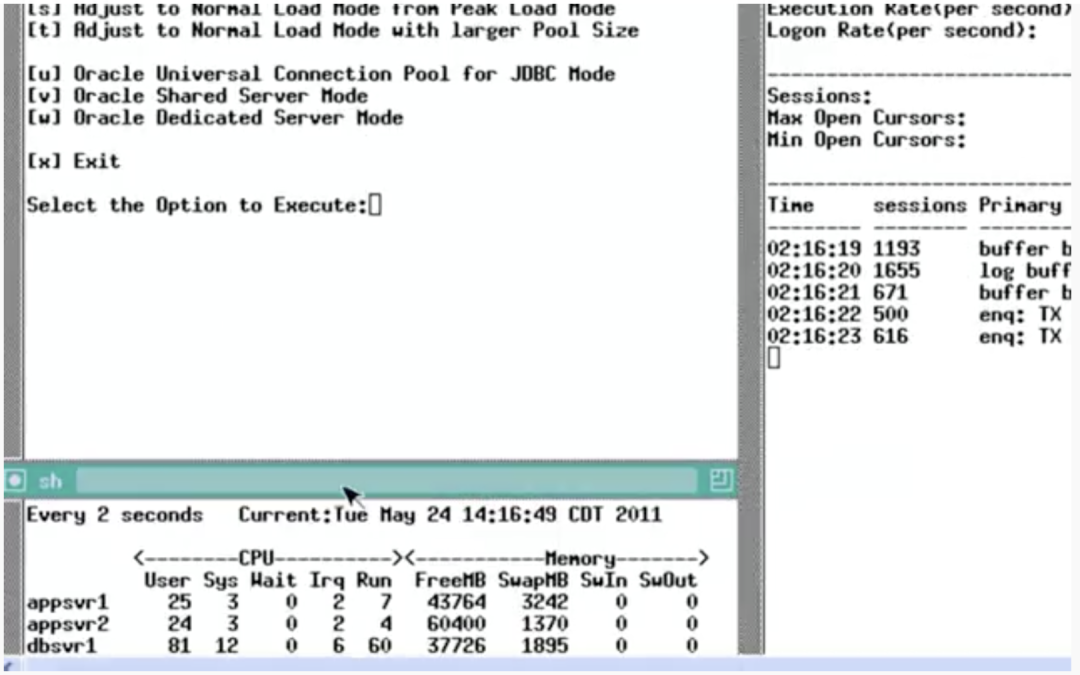
当连接池的线程数降到 1024 的时候,测试结果如下图:
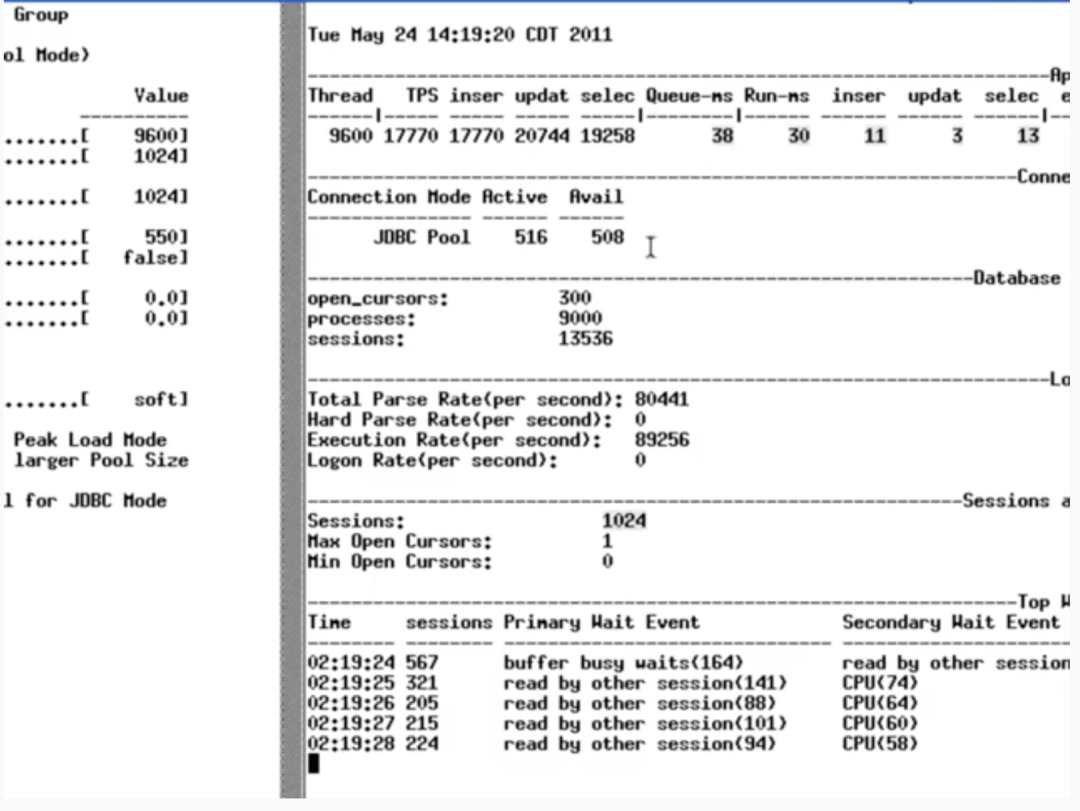
TPS 约 170k 左右,没有明显的变化,队列等待时间有少量下降,但是 SQL 的执行时间从 78ms 降到了 38ms,效果很明显。而等待事件中,CPU 等待事件也变多了。
当连接池的线程数降到 96 的时候,测试结果如下图:
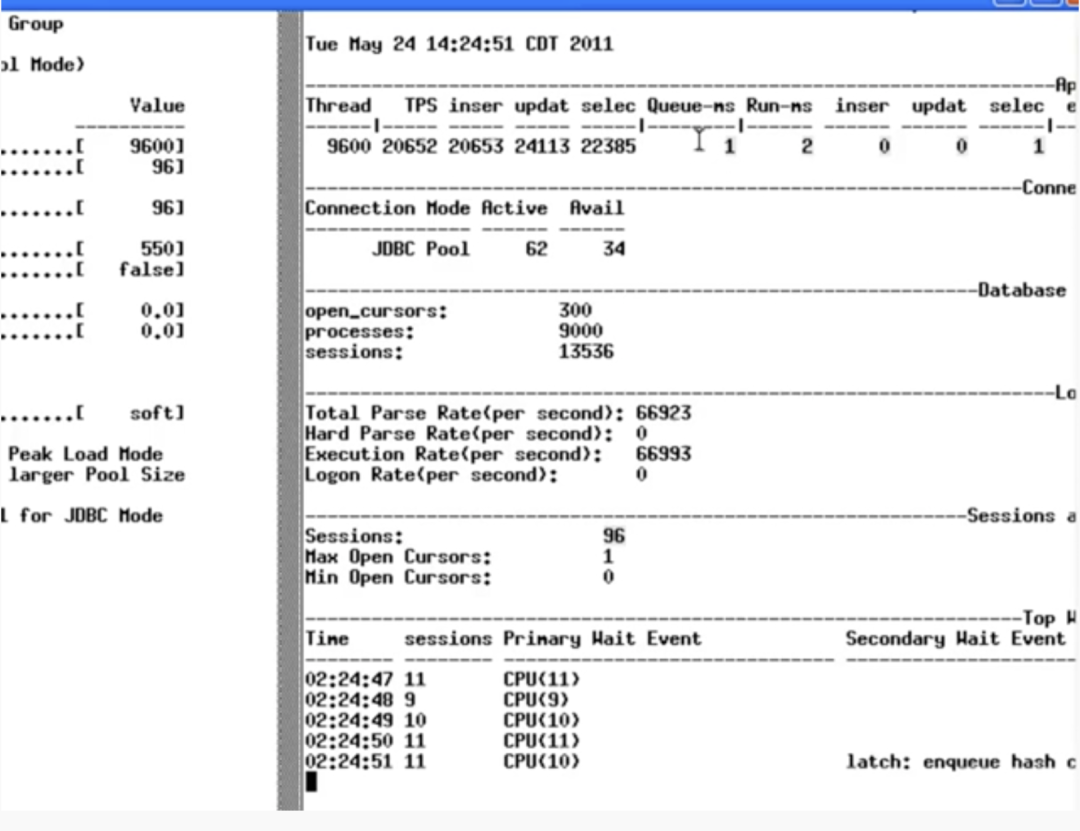
TPS 约 200k 左右,提升了约 20%,队列等待时间和 SQL 执行时间都有大幅度的下降,等待事件中全部变成了 CPU 等待。
Part3 原因是什么?
不止数据库,其他的软件也有类似情况,比如 4 线程的 Nginx web-server 为什么会比 100 线程的 Apache web-server 性能要好。这实际上和计算机 CPU 和系统的特点有关,有时候,线程少比线程多要好。
现实情况中,即便只有一核,看起来也能处理数十个或者是数百个线程。但是很多人(应该要)知道这是是操作系统的时分(时间分片)技术带来的效果。
实际上一个核心是只能执行一个线程的工作的,但是操作系统通过上下文切换让 CPU 的核心把工作内容切换成其他线程的任务,通过不停的切换,达到了“并行处理工作”的效果。
从理论上说,先执行完工作 A,再执行工作 B 是比通过上下文切换“并行”执行要快,因为上下文切换是会浪费时间的。因此一旦线程的数量超过了 CPU 的核心数,继续加线程数只会让任务处理越来越慢。
一、有限的资源
当然,实际情况并不会像上文描述一样那么简单,但是变慢的现象一般还是存在的。
可能成为数据库瓶颈的,一般就是三大基础资源:CPU,磁盘,网络。内存其实也是应该考虑的一项资源,不过内存的带宽和磁盘,网络要差上几个数量级,所以一般不会先遇到瓶颈。
假设磁盘和网络都没有瓶颈,那么事情会变得很简单:在一个 8 核的服务器上,8 个线程是最佳的性能,超过 8 线程之后就会因为上下文切换导致性能被浪费。
当加上磁盘和网络的影响之后,事情就不是那么简单了,传统的机械盘由于存在碟片转动以及寻道时间等消耗,如果一个核心一直在处理一个线程的任务,那么就会有不少时间处于“IO 等待”,触发这个等待事件的时候 CPU 核心是空闲状态的,因此通过上下文切换,去执行其他线程的任务能够高效的利用 CPU 核心的计算能力。
因此在现实中,存在线程数高于 CPU 核心数时,性能在继续提升的现象。
那么到底线程数设置为多少会比较好?从上面的描述可以知道,这个数字取决于磁盘系统,由于 SSD 存储的普及,现在的磁盘存储已经没有寻道时间或者碟片转动的消耗了。那么因为 SSD 的“IO 等待”很少,所以能设置更高的线程数?
结论可能是 180 度反转的。正因为“IO 等待”很少,所以 CPU 在处理线程任务的时候,空闲(即被 IO 阻塞)的时间很少,所以线程数越接近核心数,性能越好。更多的线程适合于经常被阻塞的场景,因为大量的空闲、阻塞时间可以用来执行其他线程的任务。
网络方面的情况也和磁盘比较类似,当写入的数据超过网卡的写入/发送队列的上限时,也会出现阻塞的情况,使用高流量,比如 10G 的网卡比 1G 的网卡更不容易出现阻塞。不过网络瓶颈的优先级较低,一般是最后才会考虑到的,甚至有一些人会完全忽略网络瓶颈的可能性(取决于网络环境建设能力)。
图表比文字更形象,可以参考如下测试结果图:
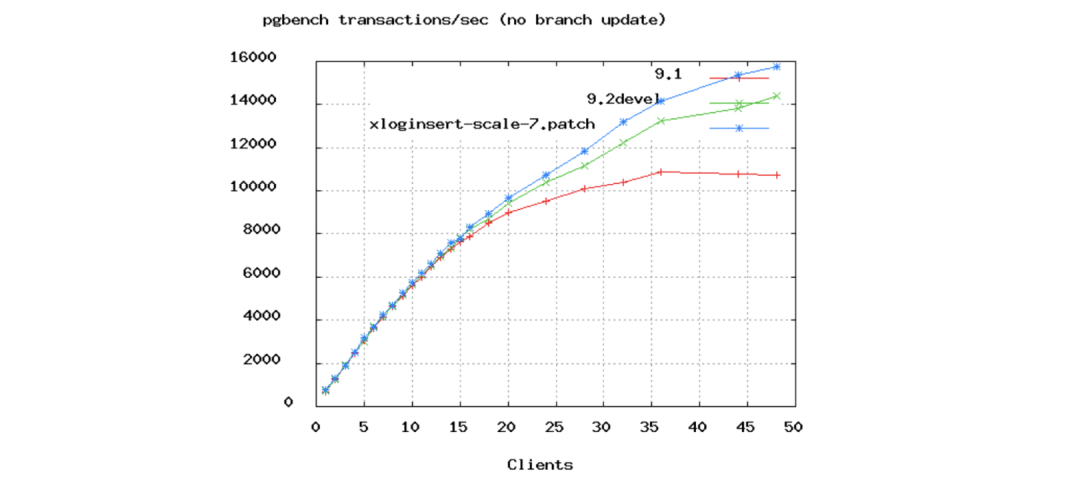
二、测试结果
这个测试结果来自于 PostgreSQL 基准测试,纵坐标是 TPS,横坐标是 Client 数量,从 1 到 50 个线程的并发,虽然测试中展示了线程数从 2048 降到 96 的测试结果,但是 96 实际上都太高了,除非服务器上的核心数有 16 个或者 32 个。
三、计算公式
PostgreSQL 项目组给了一个计算公式来计算并发的连接数,计算出来的值可以作为最初的参考设置。这个计算方式其实对大多数数据库都有参考价值。具体的设置建议以参考值为基准,尽量在接近生产压力的环境下进行测试和调整。
计算公式为:connections = ((core_count * 2) + effective_spindle_count)
core_count:不是“超线程”技术之后看到的核心数,而是实际的核心数。
effective_spindle_count:如果数据可以完全 cache 到内存则取 0,否则随着 cache 命中率降低,则这个数值会变高。MySQL 方面,可以认为是 innodb_buffer_pool 的命中率。
所以一个 4 核的酷睿 I7 服务器只有一块磁盘的情况下,连接池的线程数可以设置成:9 = ((4 * 2) + 1),用 10 作为一个取整的数值就不错。
看起来有点低?可以试试看,可以打个赌,这个设置可以轻松支撑 3000 前端用户,接近 6000 TPS 的简单查询。用同样的硬件配置,当连接数设置得比 10 高很多的时候,可以从压力测试中看到 TPS 开始下降,前端用户的响应时间开始攀升。
四、公理
应用需要一个小的“池子”,和等待使用这个池子中连接的应用线程。
如果有个网站有 10000 个前端用户,连接池设置成 10000 会非常的疯狂,1000 也会很恐怖,甚至 100 都过量了。
实际上连接池的线程数只需要几十就够了,剩下的应用线程只需要在连接池那里等待连接可用就行了。如果连接池的线程数参数已经好好优化过,那么这个设置一般不会比 core_count * 2 高,或者不会高很多。
然而在实际情况中,内部 web 应用会使用一些“令人惊奇”的设置:比如,仅有几十个用户在周期性的执行一些操作,但是连接池的线程数设置为 100。请不要过度配置这些参数和数据库。
五、Pool-locking
Pool-locking 被关注的原因是会出现单个应用层线程同时使用多个数据库连接的情况,这个问题更多的是应用层需要考虑的。
当然,增加连接池的线程数可以减少这种场景下互相抢占连接池线程的几率,但是强烈建议先在应用侧考虑如果解决这个问题,而不是直接增大连接池的线程数。
比如最大有 N 个应用层的线程,每个应用层的线程需要使用 M 个数据库连接,那么连接池想要避免 Pool-locking 就至少需要N x (M - 1) +1个数据库连接。在某些场景下,使用 JTA(Java Transaction Manager)可以显著的减少当个应用层线程需要的数据库连接数,因为getConnection()这个函数会返回当前事务已经持有的数据库连接。
Part5 结论
连接池的线程数和实际的情况是紧密相关的,连接数/并发数并不一定是越高越好。
比如一套系统中,一部分业务逻辑使用长连接,一部分业务使用短连接,最好的办法是创建两个连接池,而不是考虑怎么去优化一个池子的设置。
另外一些系统则存在外部原因会限制数据库连接数,比如业务层的 JOB 并发数量是有上限的,或者是固定的,那么连接池的线程数就可以参考这些“外部原因”的限制,设置成一样的值,或者是在这个数量附近浮动。
声明:本文由腾讯云数据库产品团队整理翻译,原内容来自于github(原文链接:https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing),作者Leo Bayer@HikariCP。翻译目的在于传递更多全球最新数据库领域相关信息,侵权请联系删除。
- End -
《腾讯云数据库专家服务》是由腾讯云数据库技术服务团队维护的社区专栏,涵盖了各类数据库的实际案例,最佳实践,版本特性等内容。目前专栏文章仍在持续丰富中,欢迎在文章末尾留言互动,给出宝贵的建议。

用数据库的三大糟心时刻,你中招了吗

98%的DBA不知道的数据库内存知识点
↓↓一年19.9特惠数据库点这儿~