本文约5000字,建议阅读10分钟
本文将介绍如何为成功的面试做准备的,以及可以帮助我们面试的一些资源。
在这篇文章中,将介绍如何为成功的面试做准备的,以及可以帮助我们面试的一些资源。
代码开发基础
如果你是数据科学家或软件开发人员,那么应该已经知道一些 Python 和 SQL 的基本知识,这对数据科学家的面试已经足够了,因为大多数的公司基本上是这样的——但是,在你的简历中加入 Spark 是一个很好的加分项。- 处理df(pandas),例如读取、加入、合并、过滤
- 操作字符串,例如使用正则表达式、搜索字符串包含的内容
在你的编程面试中,掌握 SQL 和 Python 是很重要的。了解数据结构和算法
这是一个重要的问题,可能不像对软件开发人员那么重要,但是对数据结构和算法有很好的理解肯定会让你与众不同。以下是一个好的开始:下面进入本文的正题,将介绍一些基本的ML面试相关资料,可以作为笔记收藏。线性回归
我关于线性回归的大部分笔记都是基于《统计学习导论》这本书。
Logistic 回归
它是一种广泛使用的技术,因为它非常高效,不需要太多计算资源,高度可解释,不需要缩放输入特征,不需要任何调整,易于正则化,并且它输出经过良好校准的预测概率。与线性回归一样,当删除与输出变量无关的属性以及彼此非常相似(相关)的属性时,逻辑回归的效果会更好。所以特征工程在逻辑和线性回归的性能方面起着重要作用。Logistic 回归的另一个优点是,它非常容易实现并且训练效率很高。我通常从逻辑回归模型作为基准开始,然后尝试使用更复杂的算法。由于其简单性以及可以相对容易和快速地实现的事实,逻辑回归是一个很好的基准可以使用它来衡量其他更复杂算法的性能。它的一个最主要的缺点是我们不能用它解决非线性问题,因为它的决策面是线性的。逻辑回归的假设:首先,逻辑回归不需要因变量和自变量之间的线性关系。其次,误差项(残差)不需要服从正态分布。第三,不需要同方差性。最后,逻辑回归中的因变量不是在区间或比率尺度上测量的。首先,二元逻辑回归要求因变量是二元的,而序数逻辑回归要求因变量为序数。其次,逻辑回归要求观察结果彼此独立。换言之,观察结果不应来自重复测量或匹配数据。第三,逻辑回归要求自变量之间很少或没有多重共线性。这意味着自变量之间的相关性不应太高。第四,逻辑回归假设自变量和对数几率是线性的。虽然这种分析不要求因变量和自变量线性相关,但它要求自变量与对数几率线性相关。最后,逻辑回归通常需要大样本量。对于模型中的每个自变量,一般情况下至少需要 10 个结果频率最低的样本。聚类
使用 GMM 有两个好处。首先,GMM 在集群协方差方面比 K-Means 灵活得多;由于标准偏差参数,簇可以呈现任何椭圆形状,而不是仅限于圆形。K-Means 实际上是 GMM 的一种特殊情况,其中每个集群在所有维度上的协方差都接近 0。其次,由于 GMM 使用概率,因此每个数据点可以属于多个簇。因此,如果一个数据点位于两个重叠集群的中间,我们可以简单地定义它的类,方法是说它属于类 1 的 X 百分比和属于类 2 的 Y 百分比。随机森林和提升树
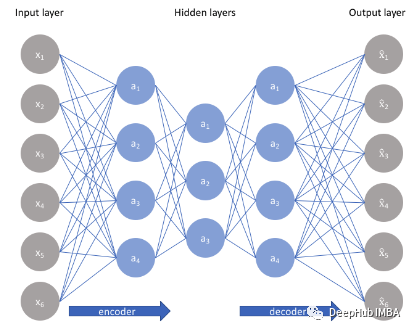
自编码器
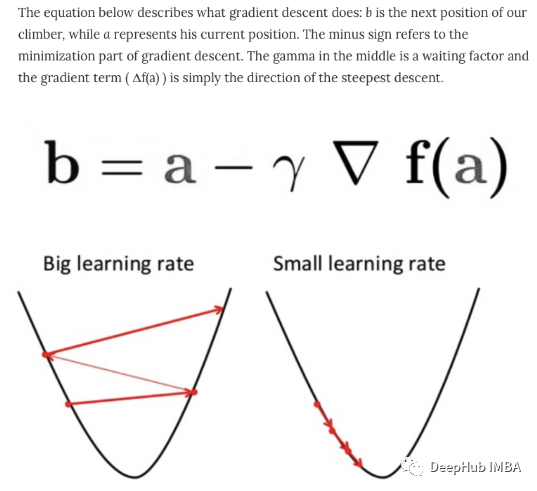
自编码器是一种无监督学习技术,利用神经网络来完成表示学习的任务。具体来说,设计一个神经网络架构,以便我们在网络中包含一个瓶颈层(压缩),强制原始输入的压缩知识表示。如果输入特征彼此独立,那么这种压缩和随后的重建将是一项非常困难的任务。但是如果数据中存在某种结构(即输入特征之间的相关性),则可以学习这种结构,从而在强制输入通过网络瓶颈时加以利用。如上图所示,我们可以将一个未标记的数据集构建为一个监督学习问题,其任务是输出 x̂ ,即原始输入 x 的重建。可以通过最小化重建误差 (x,x̂ ) 来训练该网络,该误差衡量我们的原始输入与后续重建之间的差异。瓶颈层是我们网络设计的关键属性;在不存在信息瓶颈的情况下,我们的网络可以很容易地学会通过网络传递这些值来简单地记住输入值。注意:事实上,如果我们要构建一个线性网络(即在每一层不使用非线性激活函数),我们将观察到与 PCA 中观察到的相似的降维。因为神经网络能够学习非线性关系,这可以被认为是比 PCA 更强大的(非线性)泛化。PCA 试图发现描述原始数据的低维超平面,而自动编码器能够学习非线性流形(流形简单地定义为连续的、不相交的表面)。梯度下降
梯度下降是一种用于寻找可微函数的局部最小值的优化算法。梯度下降通过最小化成本函数的方法找到函数参数(系数)的值。这是一个迭代逼近的过程。梯度只是衡量所有权重相对于误差变化的变化。也可以将梯度视为函数的斜率。梯度越高,斜率越陡,模型学习的速度就越快。但是如果斜率为零,模型就会停止学习。在数学术语中,梯度是关于其输入的偏导数。批量梯度下降:批量梯度下降,也称为普通梯度下降,计算训练数据集中每个示例的误差,但只有在评估了所有训练示例之后,模型才会更新。这整个过程就像一个循环,称为一个训练轮次。批量梯度下降的一些优点是它的计算效率,它产生稳定的误差梯度和稳定的收敛。缺点是稳定的误差梯度有时会导致收敛状态不是模型所能达到的最佳状态。它还要求整个训练数据集都在内存中并且可供算法使用。随机梯度下降:相比之下,随机梯度下降 (SGD) 对数据集中的每个训练示例执行此操作,这意味着它会一一更新每个训练示例的参数。这可以使 SGD 比批量梯度下降更快。但是频繁更新比批量梯度下降方法的计算成本更高。每一个样本都计算梯度也会收到噪声的影响,导致不是向着梯度的方向移动导致训练时间的增加。小批量梯度下降:小批量梯度下降是首选方法,因为它结合了 SGD 和批量梯度下降的概念。它只是将训练数据集分成小批,并为每个批执行更新。这在随机梯度下降的鲁棒性和批量梯度下降的效率之间建立了平衡。常见的 mini-batch 大小在 50 到 256 之间,但与任何其他机器学习技术一样,没有明确的规则,因为它因不同的应用程序而异。这是训练神经网络时的首选算法,也是深度学习中最常见的梯度下降类型。独热编码与标签编码
我们应该如何处理分类变量呢?事实证明,有多种处理分类变量的方法。在本文中将讨论两种最广泛使用的技术:标签编码是一种用于处理分类变量的流行编码技术。在这种技术中,每个标签都根据字母顺序分配一个唯一的整数。让我们看看如何使用 scikit-learn 库在 Python 中实现标签编码,并了解标签编码的挑战。第一列 Country 是分类特征,因为它由对象数据类型表示,其余的是数字特征,因为它们由 int64 表示。# Import label encoderfrom sklearn import preprocessing# label_encoder object knows how to understand word labels.label_encoder = preprocessing.LabelEncoder()# Encode labels in column ‘Country’.data[‘Country’]= label_encoder.fit_transform(data[‘Country’])print(data.head())
在上述场景中,国家名称没有顺序或等级。但是很可能会因为数字本身导致模型很有可能捕捉到印度<日本<美国等国家之间的关系,这是不正确的。那么如何才能克服这个障碍呢?这里出现了 One-Hot Encoding 的概念。One-Hot Encoding 是另一种处理分类变量的流行技术。它只是根据分类特征中唯一值的数量创建附加特征。类别中的每个唯一值都将作为特征添加。在这种编码技术中,每个类别都表示为一个单向量。让我们看看如何在 Python 中实现 one-hot 编码:# importing one hot encoderfrom sklearn from sklearn.preprocessing import OneHotEncoder# creating one hot encoder objectonehotencoder = OneHotEncoder()#reshape the 1-D country array to 2-D as fit_transform expects 2-D and finally fit the objectX = onehotencoder.fit_transform(data.Country.values.reshape(-1,1)).toarray()#To add this back into the original dataframedfOneHot = pd.DataFrame(X, columns = [“Country_”+str(int(i)) for i in range(data.shape[1])])df = pd.concat([data, dfOneHot], axis=1)#droping the country columndf= df.drop([‘Country’], axis=1)#printing to verifyprint(df.head())
One-Hot Encoding 会导致虚拟变量陷阱,因为可以借助其余变量轻松预测一个变量的结果。虚拟变量陷阱导致称为多重共线性的问题。当独立特征之间存在依赖关系时,就会发生多重共线性。多重共线性是线性回归和逻辑回归等机器学习模型中的一个严重问题。因此,为了克服多重共线性问题,必须删除其中虚拟变量。下面将实际演示在执行 one-hot 编码后如何引入多重共线性问题。检查多重共线性的常用方法之一是方差膨胀因子 (VIF):最后说明:如果使用的树型模型,使用标签编码就足够了,使用线性模型建议还是使用独热编码。超参数调优
通常,我们对最佳超参数只有一个模糊的概念,因此缩小搜索范围的最佳方法是评估每个超参数值。使用 Scikit-Learn 的 RandomizedSearchCV 方法,我们可以定义超参数范围的网格,并从网格中随机采样,对每个值组合执行 K-Fold CV。from sklearn.model_selection import RandomizedSearchCV# Number of trees in random forestn_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]# Number of features to consider at every splitmax_features = [‘auto’, ‘sqrt’]# Maximum number of levels in treemax_depth = [int(x) for x in np.linspace(10, 110, num = 11)]max_depth.append(None)# Minimum number of samples required to split a nodemin_samples_split = [2, 5, 10]# Minimum number of samples required at each leaf nodemin_samples_leaf = [1, 2, 4]# Method of selecting samples for training each treebootstrap = [True, False]# Create the random gridrandom_grid = {‘n_estimators’: n_estimators,‘max_features’: max_features,‘max_depth’: max_depth,‘min_samples_split’: min_samples_split,‘min_samples_leaf’: min_samples_leaf,‘bootstrap’: bootstrap}pprint(random_grid){‘bootstrap’: [True, False],‘max_depth’: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, None],‘max_features’: [‘auto’, ‘sqrt’],‘min_samples_leaf’: [1, 2, 4],‘min_samples_split’: [2, 5, 10],‘n_estimators’: [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]}# Use the random grid to search for best hyperparameters# First create the base model to tunerf = RandomForestRegressor()# Random search of parameters, using 3 fold cross validation,# search across 100 different combinations, and use all available coresrf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)# Fit the random search modelrf_random.fit(train_features, train_labels)
RandomizedSearchCV中最重要的参数是n_iter,它控制要尝试的不同组合的数量,cv是用于交叉验证的分折次数(我们分别使用100和3)。更多的迭代将覆盖更大的搜索空间,更多的cv折叠将减少过拟合的机会,但提高每一个将增加运行时间。机器学习是一个权衡取舍的领域,性能与时间是最基本的权衡之一。rf_random.best_params_{‘bootstrap’: True,‘max_depth’: 70,‘max_features’: ‘auto’,‘min_samples_leaf’: 4,‘min_samples_split’: 10,‘n_estimators’: 400}
随机搜索允许缩小每个超参数的范围。也可以显式地指定要尝试的每个设置组合。使用GridSearchCV来实现这一点,该方法不是从一个分布中随机抽样,而是评估我们定义的所有组合。为了使用网格搜索,我们根据随机搜索提供的最佳值创建另一个网格:from sklearn.model_selection import GridSearchCV
# Create the parameter grid based on the results of random searchparam_grid = {‘bootstrap’: [True],‘max_depth’: [80, 90, 100, 110],‘max_features’: [2, 3],‘min_samples_leaf’: [3, 4, 5],‘min_samples_split’: [8, 10, 12],‘n_estimators’: [100, 200, 300, 1000]}
# Create a based modelrf = RandomForestRegressor()
# Instantiate the grid search modelgrid_search = GridSearchCV(estimator = rf, param_grid = param_grid,cv = 3, n_jobs = -1, verbose = 2)
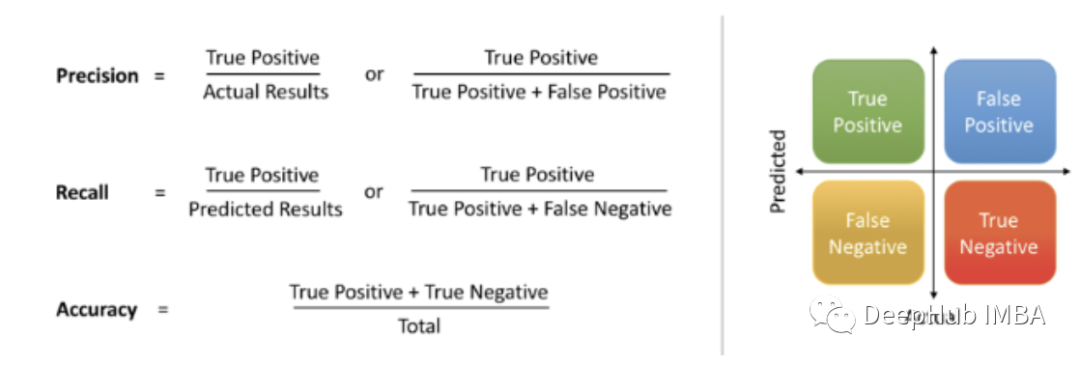
精度和召回
这些指标表示了模型在数据集中找到所有相关案例的能力:
损失函数
在数学上,如果目标变量的分布是高斯分布,则它是最大似然推理框架下的首选损失函数。首先要想到并且可以使直接使用损失函数,只有在有充分理由的情况下才建议使用其他的损失函数。在一些回归问题中,目标变量的分布可能主要是高斯分布,但可能有异常值,例如平均值的大值或小值距离很远。在这种情况下,平均绝对误差或 MAE 损失是一个合适的损失函数,因为它对异常值更稳健。它被计算为实际值和预测值之间的绝对差的平均值。交叉熵:交叉熵将计算一个分数,该分数总结了预测类 1 的实际概率分布和预测概率分布之间的平均差异,完美的交叉熵值为 0。对于二元分类问题,交叉熵的替代方法是Hinge Loss,主要开发用于支持向量机 (SVM) 模型。它旨在与目标值在集合 {-1, 1} 中的二进制分类一起使用。Hinge Loss鼓励示例具有正确的符号,当实际和预测的类值之间的符号存在差异时分配更多错误。Hinge Loss的性能报告是混合的,有时在二元分类问题上比交叉熵有更好的性能。最后总结
本文分享了一些在面试中常见的问题,后续我们还会整理更多的文章,希望这篇文章对你有帮助,并祝你为即将到来的面试做好准备!编辑:王菁