
帮小姐姐写个爬虫,赢得她请我喝下午茶,Nice啊!

不知道大家是否关注到,我的文章经常在csdn的华为云博客中进行转载,没办法人缘好,认识她们运营的小姐姐啊!但是前几天她和我说到了一个自己的困扰。领导让她每周统计一次华为云发布的所有文章数据,包括类型(原创/转载)、标题、链接、访问量、评论数。
听起来就够麻烦了,等我登陆csdn看到他们居然收录了1600多篇文章的时候,更懵逼了...小姐姐问Python能否获取数据,那还用说当然OK了。刚好周末在家看了下csdn的网站结构,觉得蛮简单的梳理了下思路,写了些片段的代码。
今天,小姐姐突然说要请我喝下午茶,原来是领导又催她统计csdn数据了。
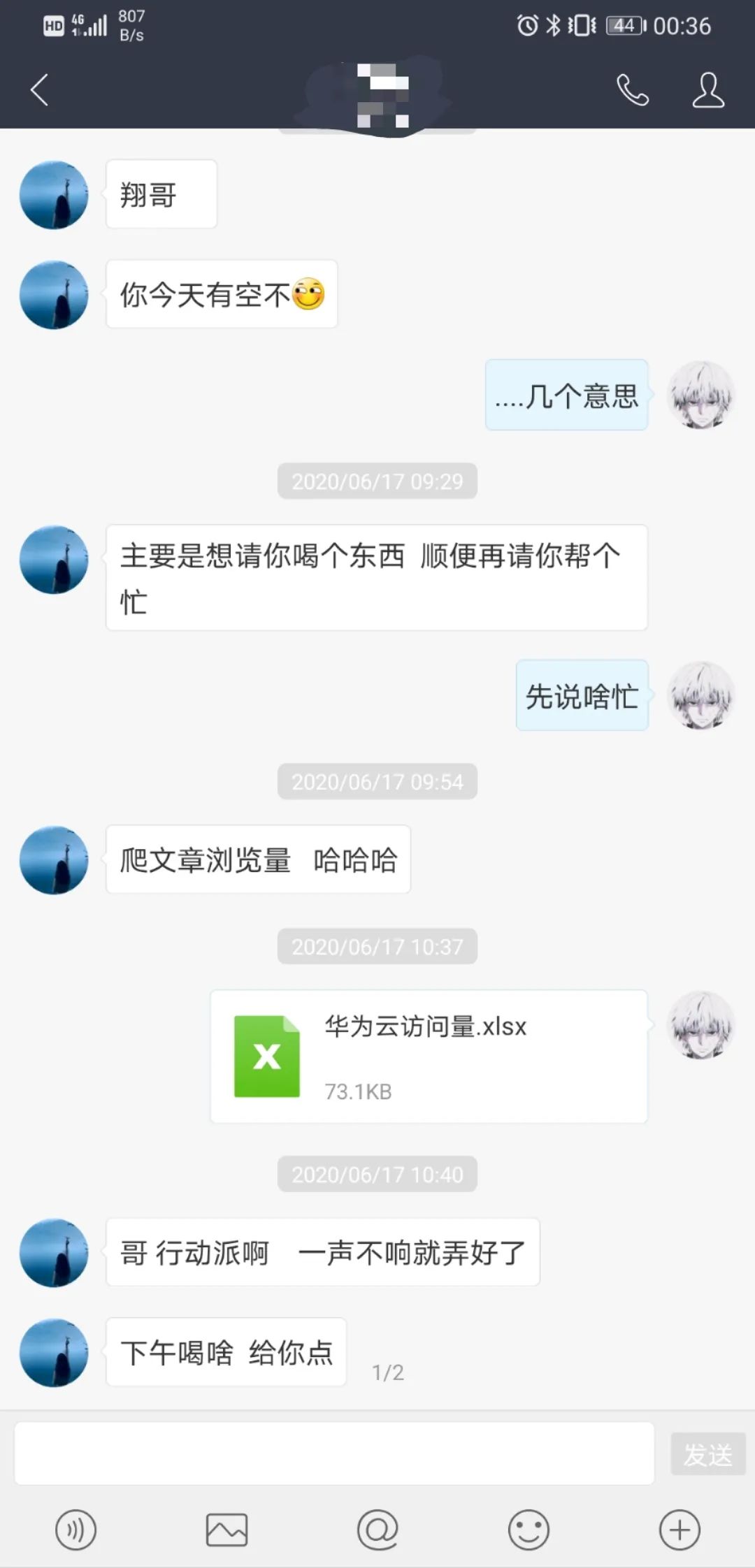
作为从小扶老奶奶过马路的新时代活雷锋,这个下午茶 ,不, 这个忙我肯定要帮的啊!之前已经准备了一些代码片段,重新梳理思路、优化逻辑,不到半小时就整理了一份excel数据。然后你懂得,当然是下午茶喽...不贪心,一杯瑞幸纳瑞冰,哈哈!

下面就来说说代码的实现过程吧...
CSDN网站分析
首先,每个用户都有一个自己的主页,比如我的CSDN地址:https://blog.csdn.net/BreezePython
其实平时都是在简书上写文章的,然后csdn使用博客搬家功能自动从简书同步。个人还是比较喜欢简书的书写风格,但没办法谁让小姐姐他们领导要搞csdn呢。盘它就完了!进入首页后,我们拖动到底部会看到第几页第几页的数字,我们随便选择后面的页码,跳转后我们的url变成了下面这样:https://blog.csdn.net/BreezePython/article/list/2
这逻辑简直不要太简单,非常适合新手们用作爬虫练习。我们只需要for循环构造页码,然后一页一页的爬下去就好了。那么什么时候结束呢?当你的url获取页码后展示如下,就可以根据返回内容结束代码了,是不是so easy!
html解析
为什么说csdn比较适合Python新手学习爬虫呢,让我们再来通过他的页面结构了解下,如下图:
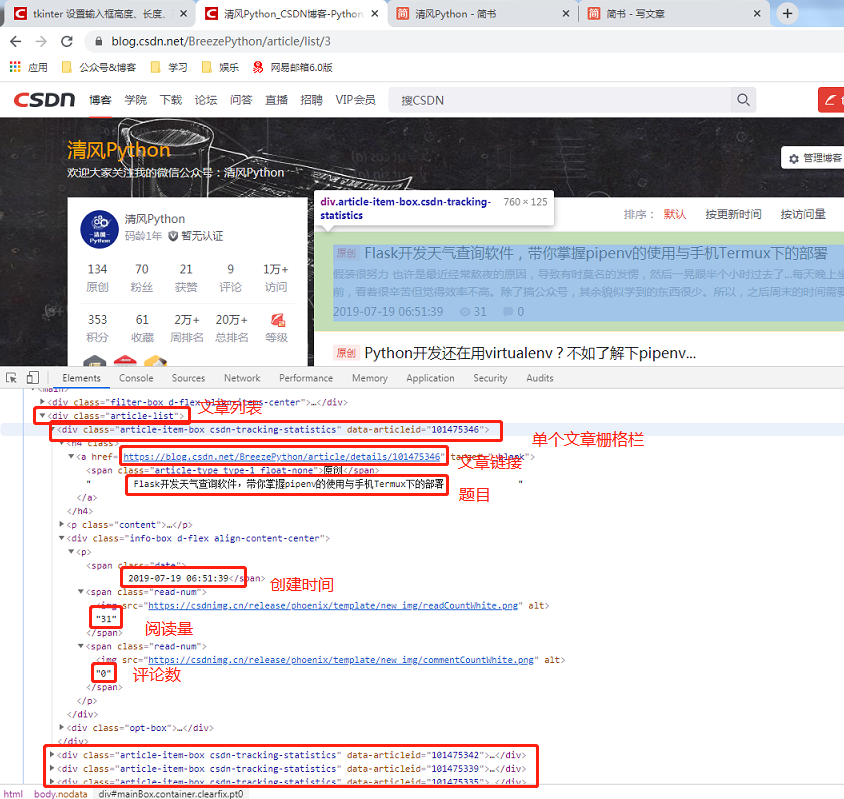
看清楚就会发现,csdn的网站结构清晰明了。我们只需要分别获取每一页的url后定位到article-list,然后遍历每一个article-item-box。在每一个栅格栏内部标注的位置,获取到对应的数据即可!这里唯一有一点麻烦的是
<a href="https://blog.csdn.net/BreezePython/article/details/101475346" target="_blank">
<span class="article-type type-1 float-none">原创span>
“ Flask开发天气查询软件,带你掌握pipenv的使用与手机Termux下的部署 ”
a>
往常我们获取a标签的内容,直接使用a.text即可,但在a标签内部又设计到一个span标签,直接获取会得到一下结果:
原创 “ Flask开发天气查询软件,带你掌握pipenv的使用与手机Termux下的部署 ”
想使用什么child、next等方式都是无法实现仅获取标题内容的,所以可以尝试先获取文章类型,然后清空span标签,这样就可以得到最终的标题内容了,代码如下:
article_type = article.a.span.text
article_url = article.a["href"]
article_span = article.a.find_all('span')
for i in article_span:
i.clear()
分析完成,我们先跑一边代码,看看能否获取到所需数据,得到如下结果:
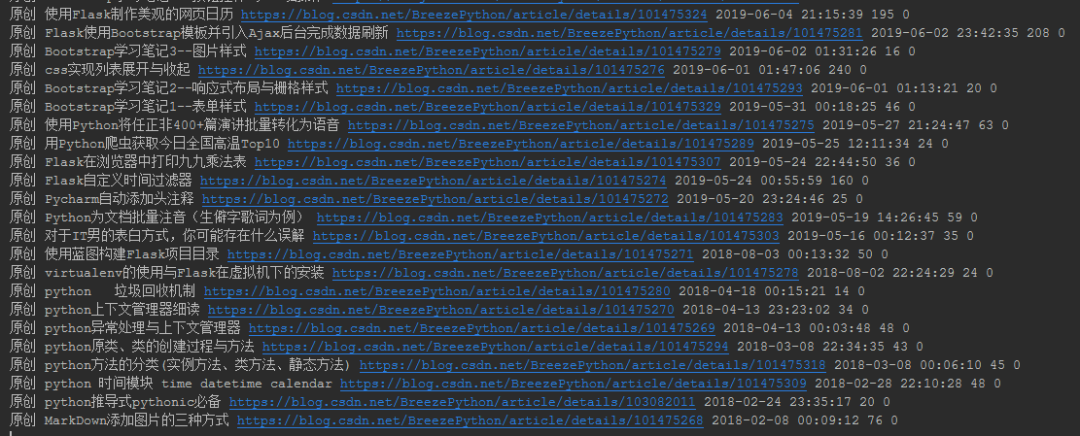
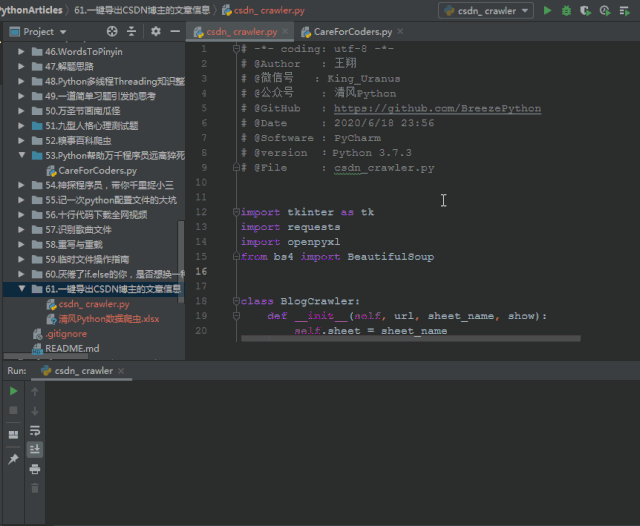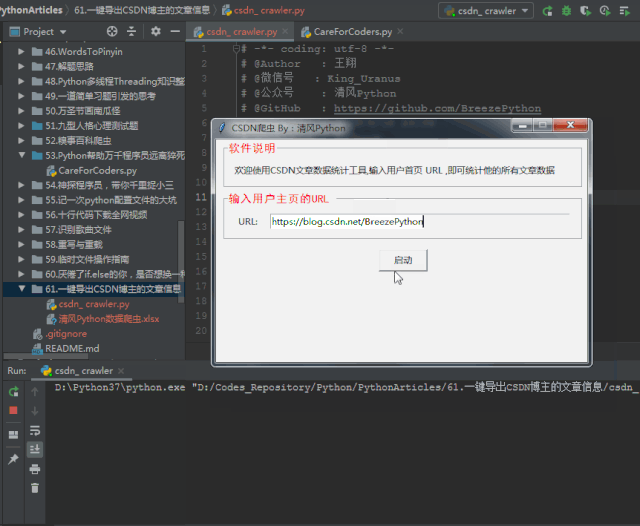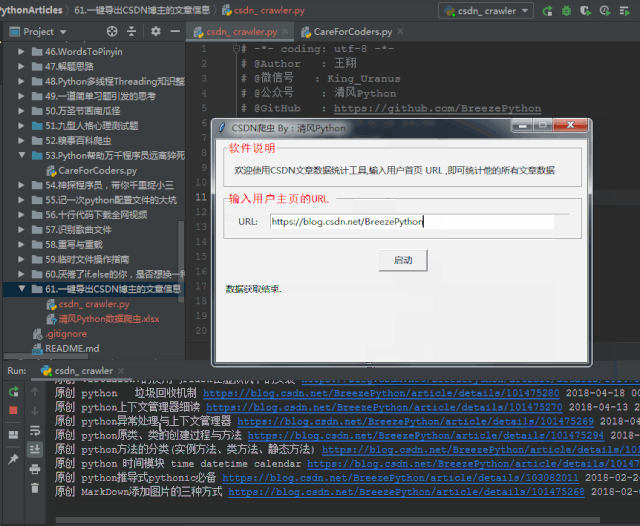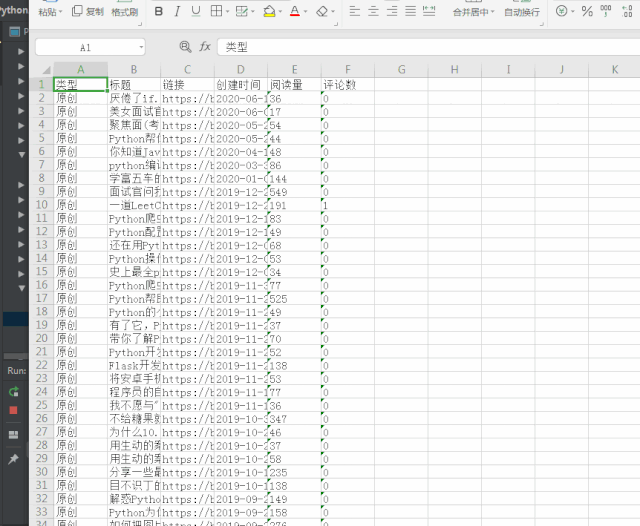
数据没问题了,那怎么保存呢?当然是excel了!
Python保存excel
python操作excel的库很多,之前专门总结过一波:
个人比较中意的是openpyxl,具体的操作就不在这赘述了,来看看最后的统计效果:
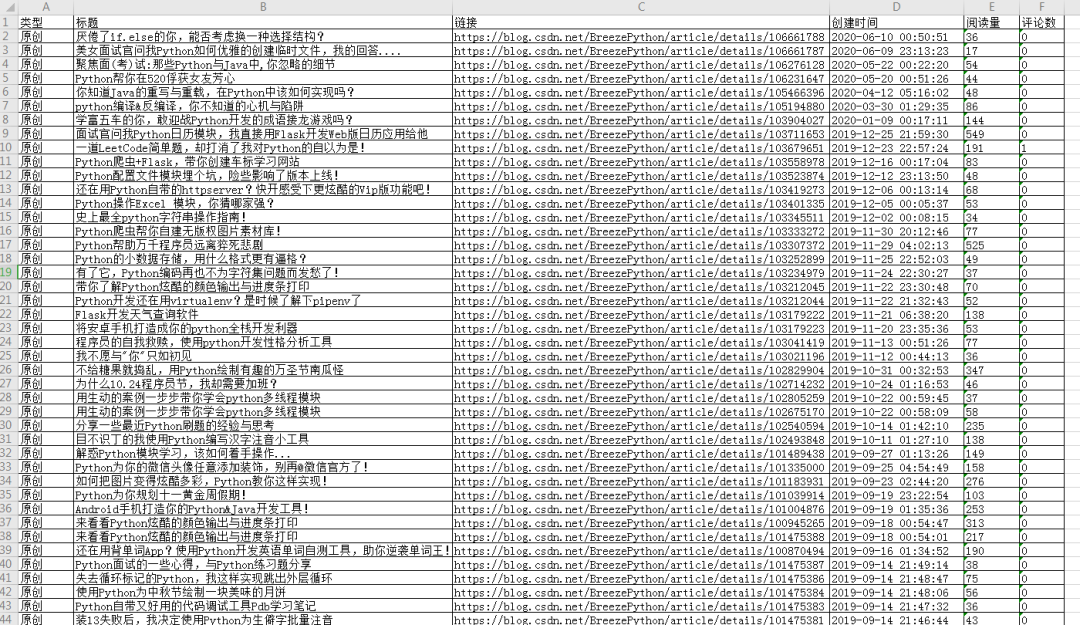
以为这样就结束了?怎么可能...
打包可执行文件
既然喝了小姐姐的下午茶,总不能每周统计的时候,都敲诈一波小姐姐吧。可是代码发给她,她一不会python、二没有环境,这可如何是好?那么,我们为什么不尝试去把代码打包成windows下的可执行文件呢?
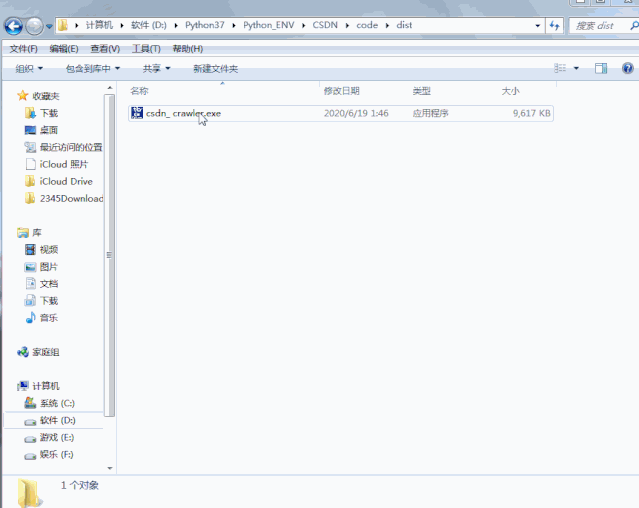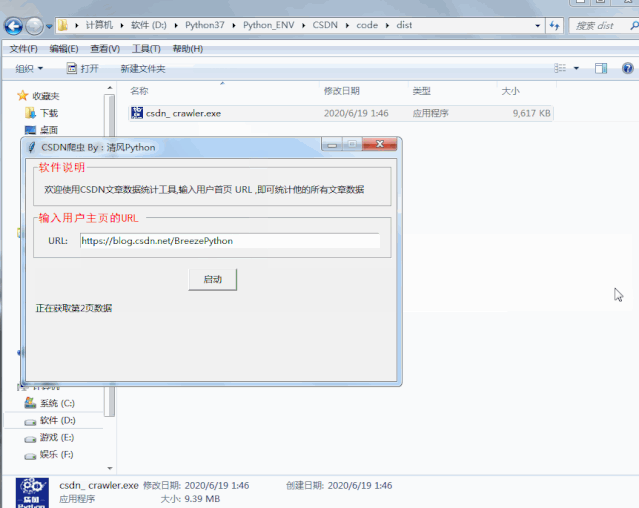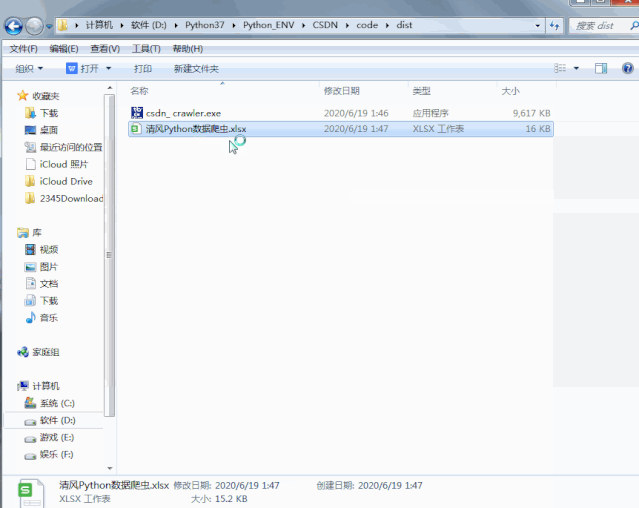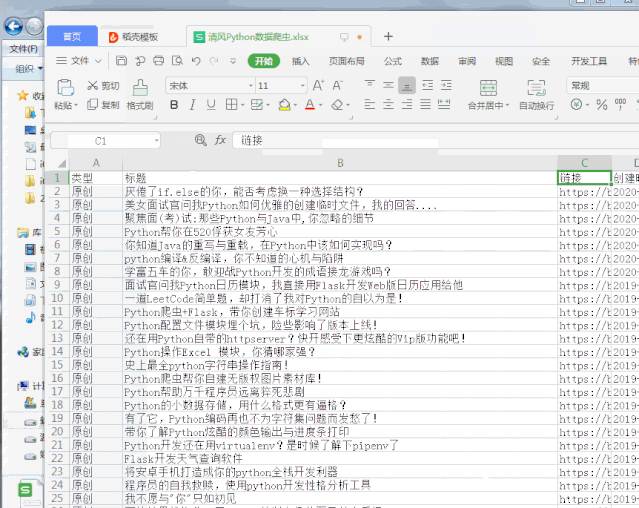
既然我们只要随便输入一个用户的首页url,就能全篇爬取他的文章内容,我们就来做一个简单的GUI功能吧:
最后我们只需要将它打包成exe工具,脱离环境直接运行即可!
有些朋友说打包的exe工具很大,因为pyinstaller在打包时,会把可能依赖到的库全部打进去,经过我多年验证,你可以单独创建一个venv,只安装你需要的几个模块这样打包会很小。对比下图是我使用主python环境和虚拟环境打包后的大小,可见一斑啊!
好了,今天的文章就到这里,代码太长就不在文章中占篇幅了,如需获取代码和exe工具,可以在公众号后台回复:csdn,即可获取代码下载链接。
关注恋习Python,Python都好练
推荐阅读:
好文章,我在看❤️