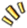面试官:换人!他连进程线程协程这几个特点都说不出

前言
很早之前就在构思这篇文章的主题,进程线程可以说是操作系统基础,看过很多关于这方面知识的文章都是纯理论讲述,编程新手有些难以直接服用。
于是写下这篇文章,用图解的形式带你学习和掌握进程、线程、协程,文字力求简单明了,对于复杂概念做到一个概念一张图解,即使你是编程小白也能看的明明白白,妈妈再也不用担心你的学习。
Go 基础教程系列教程更新已接近尾声,对 Go 语言学习感兴趣但还没看过的的同学,可以点击这个传送门:手把手教你 Golang 基础
Go 基础教程接下来会进入并发编程和 Go 协程部分,为了更好的理解这部分内容,带大家先了解 Linux 系统基础和进程、线程以及协程的差异与特点。
在操作系统课程的学习中,很多人对进程线程有大体的认识,但操作系统教材更偏向于理论叙述,本文会结合 Linux 系统实现分析,更加印象深刻。
同时,大部分人都接触进程和线程比较多,对协程知之甚少,然而最近协程并发编程技术火热起来,希望读完本文你对协程也有一个基本的了解。
话不多说,我们马上进入本文的学习。
进程
关于进程和内存管理我之前有一篇文章单独讲解过,感兴趣的同学点这里《别再说你不懂Linux内存管理了,10张图给你安排的明明白白!》 这里再挑选一部分和本文相关的内容学习,温故而知新。
首先还是说下「程序」的概念,程序是一些保存在磁盘上的指令的有序集合,是静态的。进程是程序执行的过程,包括了动态创建、调度和消亡的整个过程,进程是程序资源管理的最小单位。
进程与资源
那么进程都管理哪些资源呢?通常包括内存资源、IO资源、信号处理等部分。
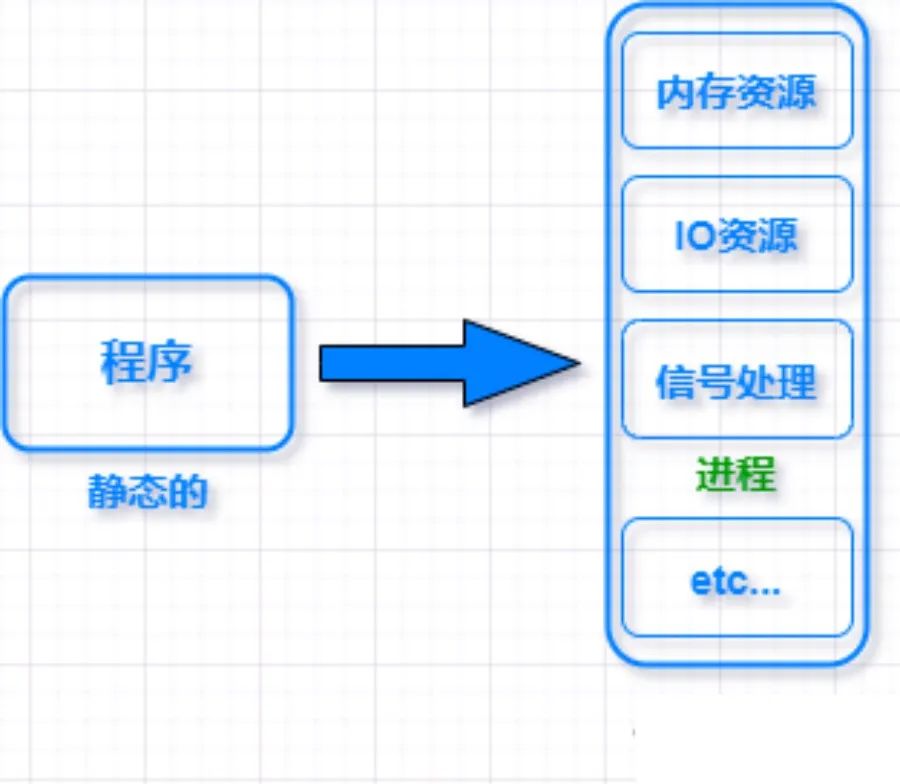
篇幅有限着重说一下内存管理,进程运行起来必然会涉及到对内存资源的管理。内存资源有限,操作系统采用虚拟内存技术,把进程虚拟地址空间划分成用户空间和内核空间。
地址空间
4GB 的进程虚拟地址空间被分成两部分:用户空间和内核空间
用户空间
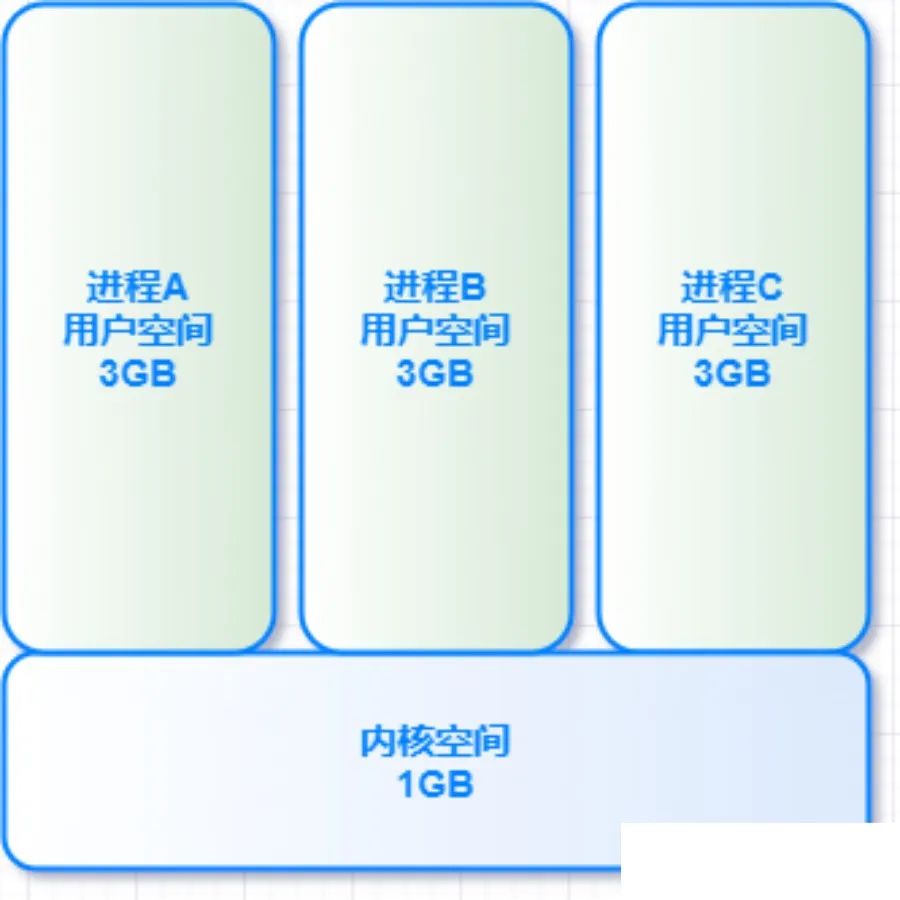
用户空间按照访问属性一致的地址空间存放在一起的原则,划分成 5个不同的内存区域。访问属性指的是“可读、可写、可执行等 。
代码段
代码段是用来存放可执行文件的操作指令,可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,它是不可写的。
数据段
数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。
BSS段
BSS段包含了程序中未初始化的全局变量,在内存中bss段全部置零。堆 heap
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈 stack
栈是用户存放程序临时创建的局部变量,也就是函数中定义的变量(但不包括
static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
上述几种内存区域中数据段、BSS 段、堆通常是被连续存储在内存中,在位置上是连续的,而代码段和栈往往会被独立存放。堆和栈两个区域在 i386 体系结构中栈向下扩展、堆向上扩展,相对而生。

你也可以再 linux 下用size 命令查看编译后程序的各个内存区域大小:
[lemon ~]# size /usr/local/sbin/sshd
text data bss dec hex filename
1924532 12412 426896 2363840 2411c0 /usr/local/sbin/sshd
内核空间
在 x86 32 位系统里,Linux 内核地址空间是指虚拟地址从 0xC0000000 开始到 0xFFFFFFFF 为止的高端内存地址空间,总计 1G 的容量, 包括了内核镜像、物理页面表、驱动程序等运行在内核空间 。
线程
线程是操作操作系统能够进行运算调度的最小单位。线程被包含在进程之中,是进程中的实际运作单位,一个进程内可以包含多个线程,线程是资源调度的最小单位。

线程资源和开销
同一进程中的多条线程共享该进程中的全部系统资源,如虚拟地址空间,文件描述符文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈、寄存器环境、线程本地存储等信息。
线程创建的开销主要是线程堆栈的建立,分配内存的开销。这些开销并不大,最大的开销发生在线程上下文切换的时候。
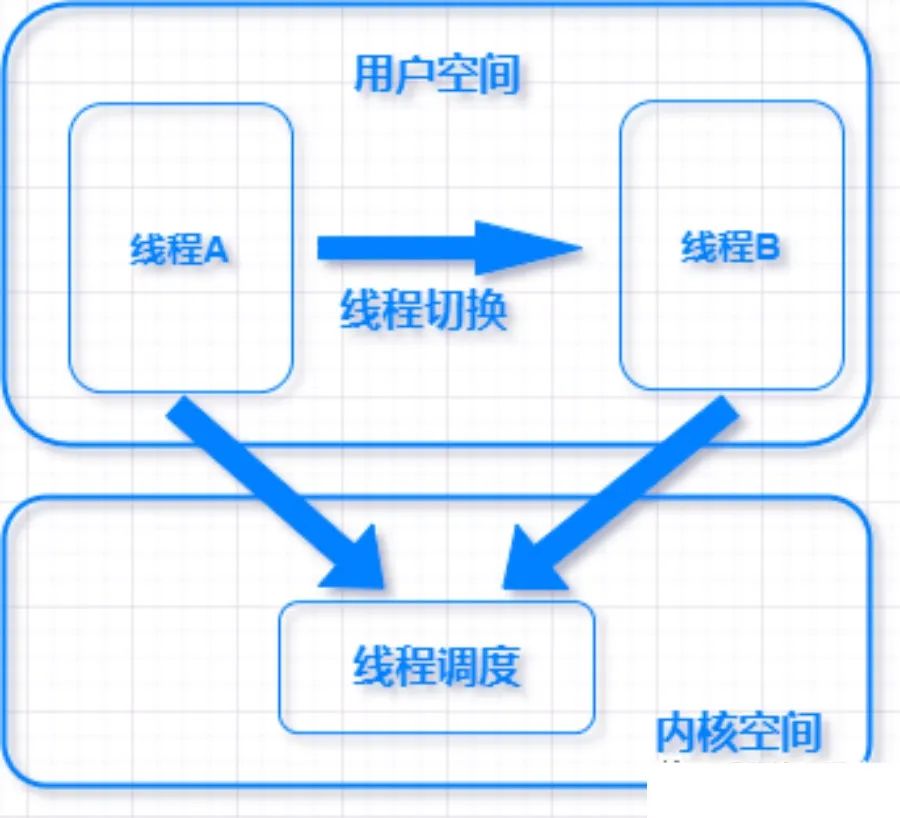
线程分类
还记得刚开始我们讲的内核空间和用户空间概念吗?线程按照实现位置和方式的不同,也分为用户级线程和内核线程,下面一起来看下这两类线程的差异和特点。
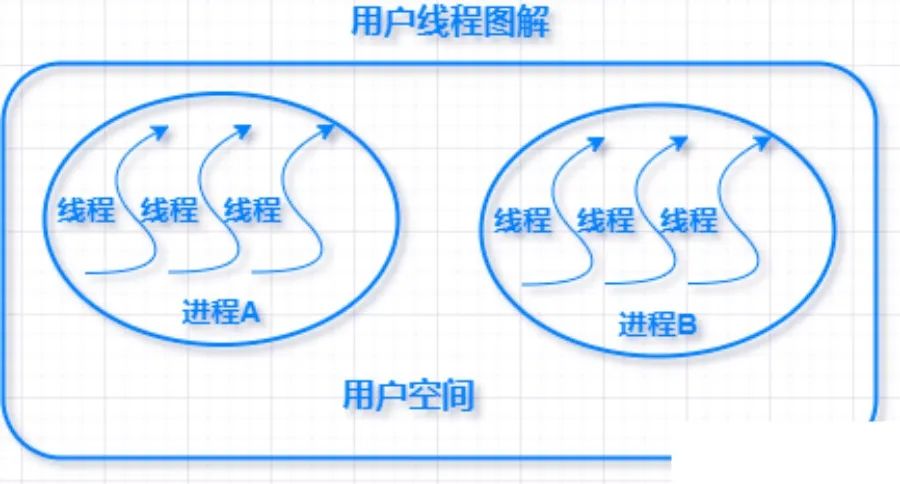
用户级线程
实现在用户空间的线程称为用户级线程。用户线程是完全建立在用户空间的线程库,用户线程的创建、调度、同步和销毁全由用户空间的库函数完成,不需要内核的参与,因此这种线程的系统资源消耗非常低,且非常的高效。
特点
用户线级线程只能参与竞争该进程的处理器资源,不能参与全局处理器资源的竞争。 用户级线程切换都在用户空间进行,开销极低。 用户级线程调度器在用户空间的线程库实现,内核的调度对象是进程本身,内核并不知道用户线程的存在。
缺点
如果触发了引起阻塞的系统调用的调用,会立即阻塞该线程所属的整个进程。 系统只看到进程看不到用户线程,所以只有一个处理器内核会被分配给该进程 ,也就不能发挥多核 CPU 的优势 。
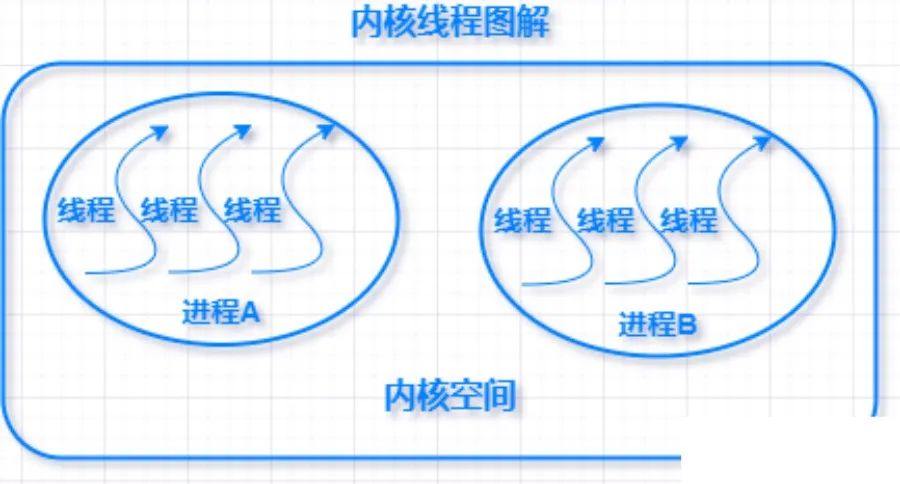
内核级线程
内核线程建立和销毁都是由操作系统负责、通过系统调用完成,内核维护进程及线程的上下文信息以及线程切换。
特点
内核级线级能参与全局的多核处理器资源分配,充分利用多核 CPU 优势。 每个内核线程都可被内核调度,因为线程的创建、撤销和切换都是由内核管理的。 一个内核线程阻塞与他同属一个进程的线程仍然能继续运行。
缺点
内核级线程调度开销较大。调度内核线程的代价可能和调度进程差不多昂贵,代价要比用户级线程大很多。 线程表是存放在操作系统固定的表格空间或者堆栈空间里,所以内核级线程的数量是有限的。
Linux 线程实现
Linux 并没有为线程准备特定的数据结构,因为 Linux只有task_struct这一种描述进程的结构体。在内核看来只有进程而没有线程,线程调度时也是当做进程来调度的。Linux所谓的线程其实是与其他进程共享资源的轻量级进程。
为什么说是轻量级呢?在于它只有一个最小的执行上下文和调度程序所需的统计信息,它只带有进程执行相关的信息,与父进程共享进程地址空间 。
轻量级进程
轻量级线程 Light-weight Process简称LWP ,是一种由内核支持的用户线程,每一个轻量级进程都与一个特定的内核线程关联。
它是基于内核线程的高级抽象,系统只有先支持内核线程才能有 LWP。每一个进程有一个或多个 LWPs ,每个LWP 由一个内核线程支持,在这种实现的操作系统中 LWP 就是用户线程。
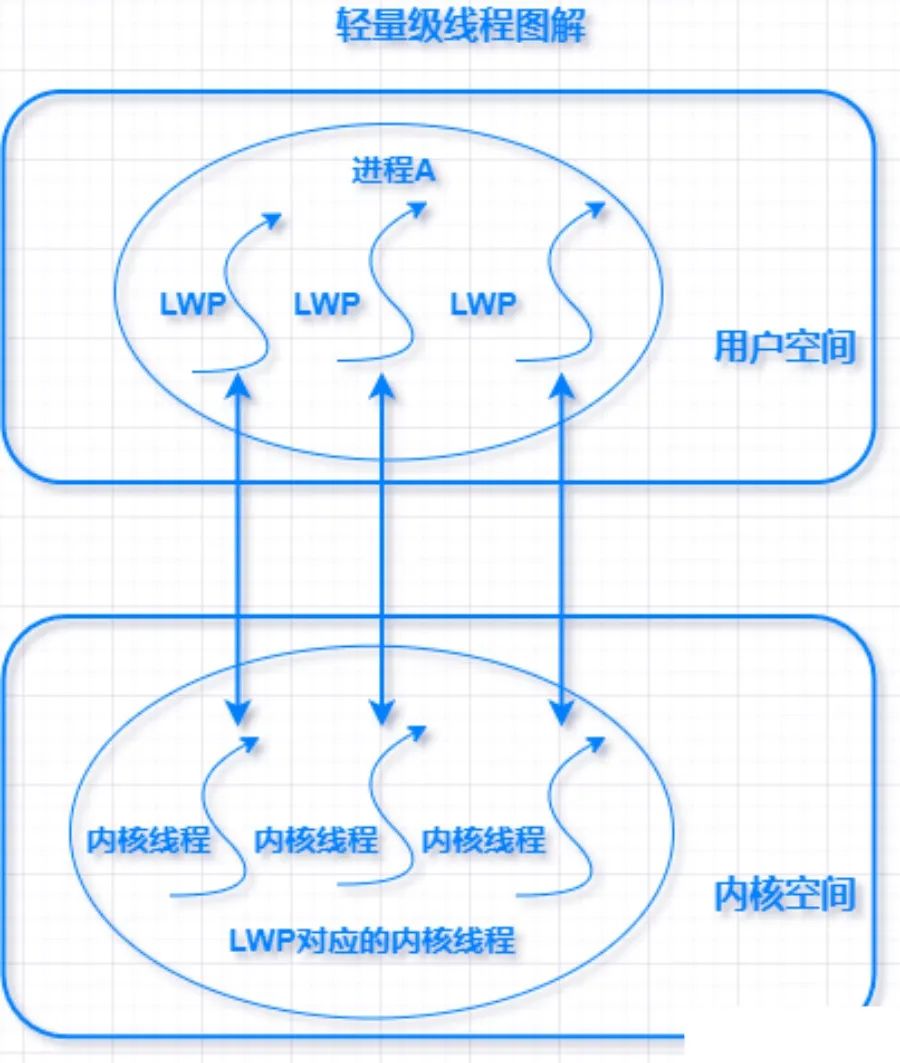
轻量级进程最早在Linux 内核 2.0.x 版本就已实现,应用程序通过一个统一的 clone() 系统调用接口,用不同的参数指定创建的进程是轻量进程还是普通进程。
特点和缺点
由于轻量轻量级进程基于内核线程实现,因此它的特点和缺点就是内核线程的缺点,这里不再赘述。
查看 LWP 信息
轻量级线程也没什么神秘的,还记得我在这篇文章《资深程序员总结:分析Linux进程的6个方法,我全都告诉你》教你的方法吗?我们用 Linux 的 pstack 命令可以查看进程的轻量级线程 LWP 信息。下图的黄色字体就是打印出的轻量级线程 ID ,以及该线程的调用堆栈信息,从最新的栈帧开始往下排列。
用法示例:pstack pid

协程
协程的知名度好像不是很高,在以前我们谈论高并发,大部分人都知道利用多线程和多进程部署服务,提高服务性能,但一般不会提到协程。其实协程的概念出来的比线程还早,只不过最近才被人们更多的提起。
协程之所以最近被大家熟知,个人觉得是 Python 和 Go 从语言层面提供了对协程更好的支持,尤其是以 Goroutine 为代表的 Go 协程实现,很大程度上降低了协程使用门槛,可以说是后起之秀了!

why 协程
当今无数的 Web 服务和互联网服务,本质上大部分都是 IO 密集型服务,什么是 IO 密集型服务?意思是处理的任务大多是和网络连接或读写相关的高耗时任务,高耗时是相对 CPU 计算逻辑处理型任务来说,两者的处理时间差距不是一个数量级的。
IO 密集型服务的瓶颈不在 CPU 处理速度,而在于尽可能快速的完成高并发、多连接下的数据读写。
以前有两种解决方案:
如果用多线程,高并发场景的大量 IO 等待会导致多线程被频繁挂起和切换,非常消耗系统资源,同时多线程访问共享资源存在竞争问题。
如果用多进程,不仅存在频繁调度切换问题,同时还会存在每个进程资源不共享的问题,需要额外引入进程间通信机制来解决。
协程出现给高并发和 IO 密集型服务开发提供了另一种选择。
当然,世界上没有技术银弹。在这里我想把协程这把钥匙交到你手中,但是它也不是万能钥匙,最好的解决方案是贴合自身业务类型做出最优选择,不一定就选择一种模型,有时候是几种模型的组合,比如多线程搭配协程是常见的组合。
什么是协程
那什么是协程呢?协程 Coroutines 是一种比线程更加轻量级的微线程。类比一个进程可以拥有多个线程,一个线程也可以拥有多个协程,因此协程又称微线程和纤程。
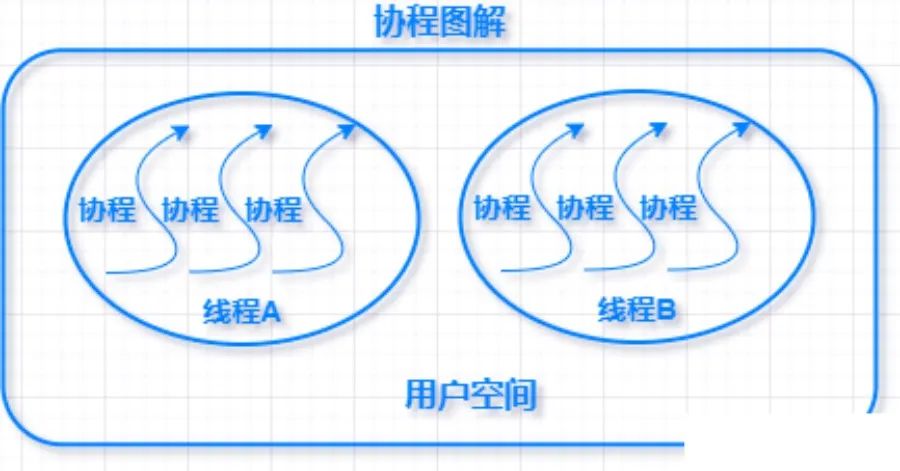
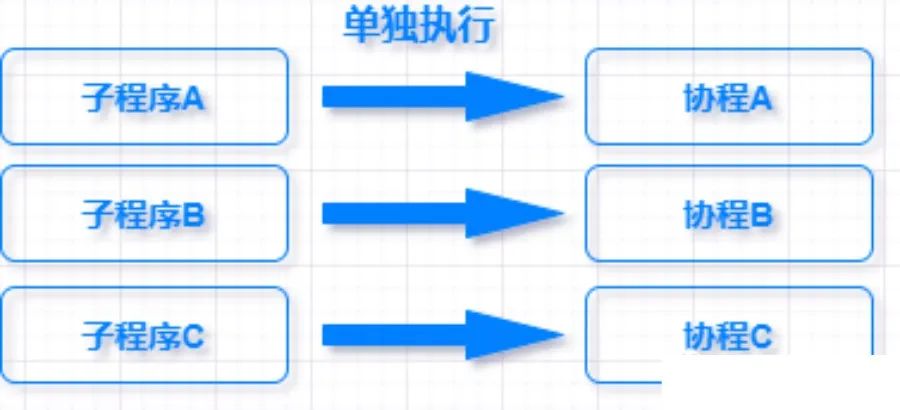
可以粗略的把协程理解成子程序调用,每个子程序都可以在一个单独的协程内执行。
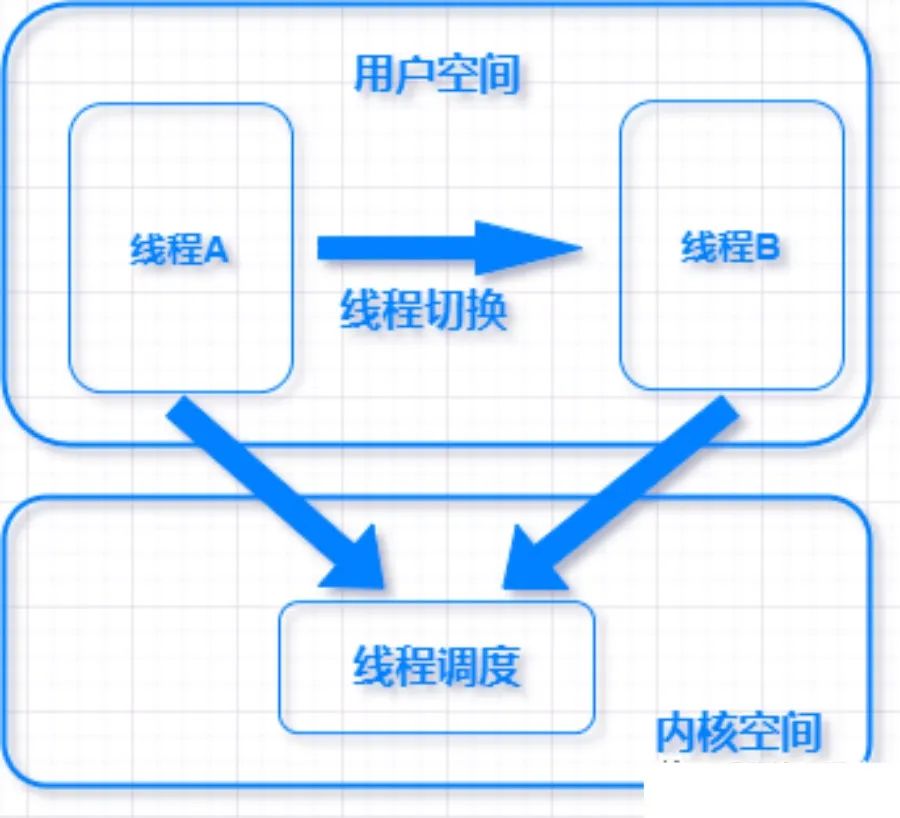
调度开销
线程是被内核所调度,线程被调度切换到另一个线程上下文的时候,需要保存一个用户线程的状态到内存,恢复另一个线程状态到寄存器,然后更新调度器的数据结构,这几步操作设计用户态到内核态转换,开销比较多。
协程的调度完全由用户控制,协程拥有自己的寄存器上下文和栈,协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作用户空间栈,完全没有内核切换的开销。
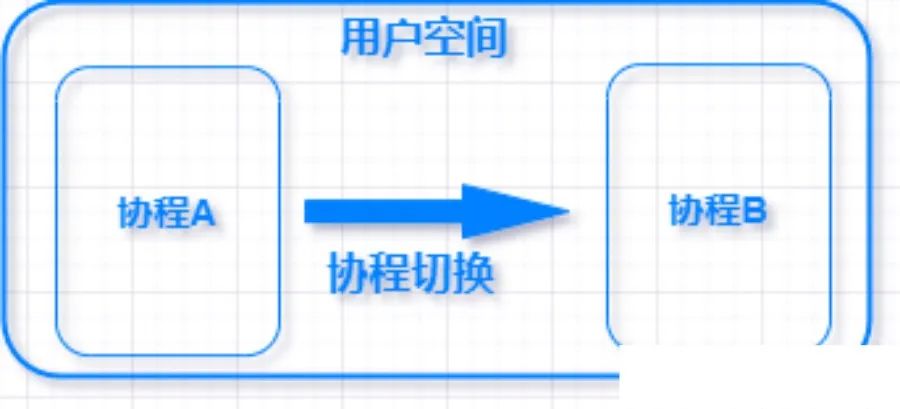
动态协程栈
协程拥有自己的寄存器上下文和栈,协程调度切换时将寄存器上下文和栈保存下来,在切回来的时候,恢复先前保存的寄存器的上下文和栈。
Goroutine 是 Golang 的协程实现。Goroutine 的栈只有 2KB大小,而且是动态伸缩的,可以按需调整大小,最大可达 1G 相比线程来说既不浪费又灵活了很多,可以说是相当的nice了!
线程也都有一个固定大小的内存块来做栈,一般会是 2MB 大小,线程栈会用来存储线程上下文信息。2MB 的线程栈和协程栈相比大了很多。
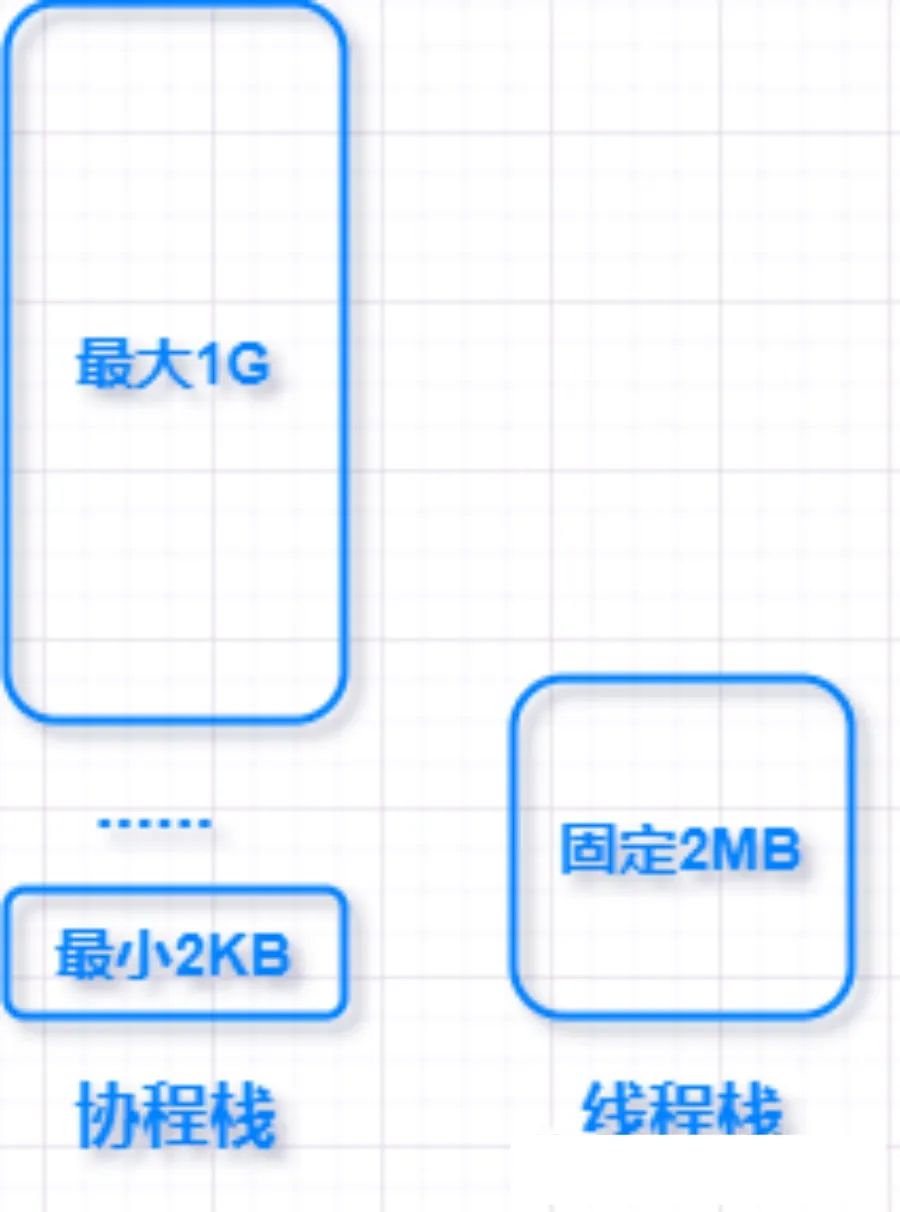
协程实现
Python协程实现
python 2.5 中引入 yield/send 表达式用于实现协程,但这种通过生成器的方式使用协程不够优雅。
python 3.5 之后引入async/await ,简化了协程的使用并且更加便于理解。
Go语言协程实现
Golang 在语言层面实现了对协程的支持,Goroutine 是协程在 Go 语言中的实现, 在 Go 语言中每一个并发的执行单元叫作一个 Goroutine ,Go 程序可以轻松创建成百上千个协程并发执行。
Go 协程调度器有三个重要数据结构:
G 表示
Goroutine,它是一个待执行的任务;M 表示操作系统的线程,它由操作系统的调度器调度和管理;
P 表示处理器
Processor,它可以被看做运行在线程上的本地调度器;
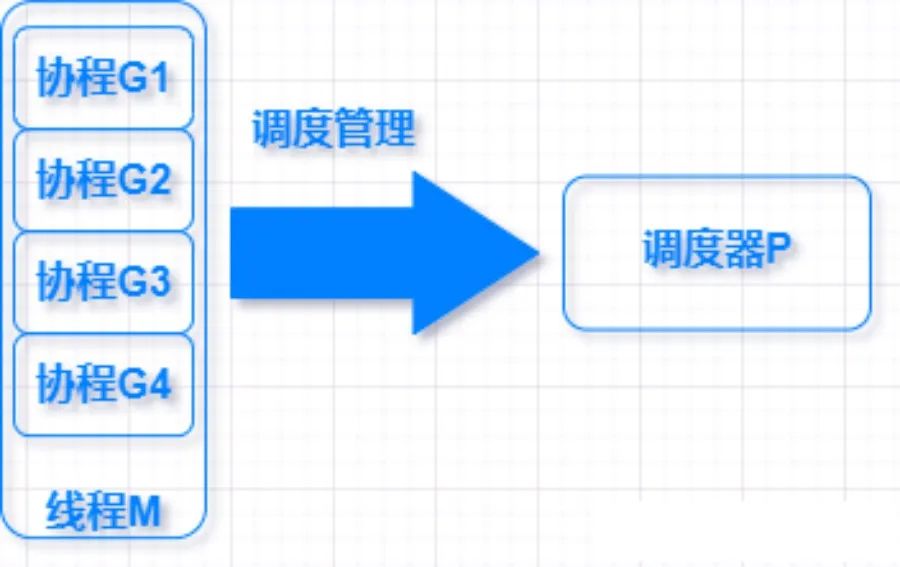
Go 调度器最多可以创建 10000 个线程,但可以通过设置 GOMAXPROCS 变量指能够正常运行的线程数, 这个变量的默认值 等于 CPU 个数,也就是线程数等于 CPU 核数,这样不会触发操作系统的线程调度和上下文切换,所有的调度由 Go 语言调度器触发,都是在用户态,减少了非常多的调用开销。
总结
这篇文章讲解和对比了进程、线程的概念,同时通过进程窥探到操作系统内存管理的冰山一角,另外还讲解了具体到 Linux 系统下线程的实现现状,顺势引出了轻量级进程的概念。最后着重说明了大部分同学不太了解的协程,通过对比不同的服务模型,带你了解协程的特点。
说明一下,文中的图片都是我手绘的,原图我没打水印方便阅读,不过微信发出去之后会对图片压缩和打上水印,对知识的理解有时候真的是一图胜千言,也是我文章的价值所在.