
「中国达芬奇」机器人火了!除了缝葡萄皮,还有这些脑洞大开的操作

新智元报道
新智元报道
编辑:好困 小咸鱼
【新智元导读】最近机器人很火,从能遛弯的狗到能骑的马,甚至还有能缝葡萄皮的机械臂!如果我说,能让机器人自己学会各种「骚操作」,你信么?


没条胳膊也算机器人?



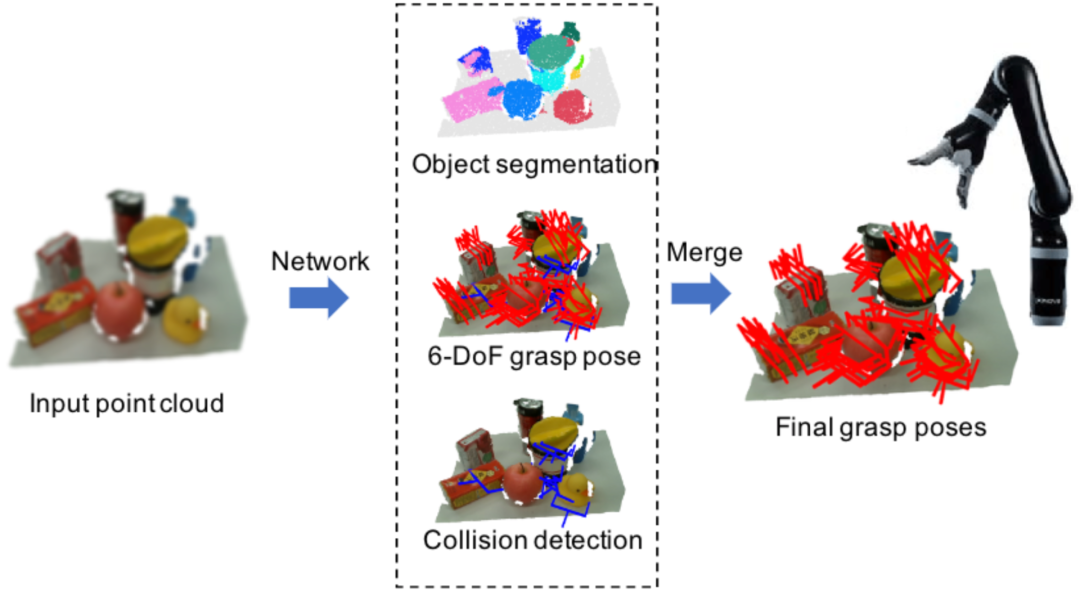
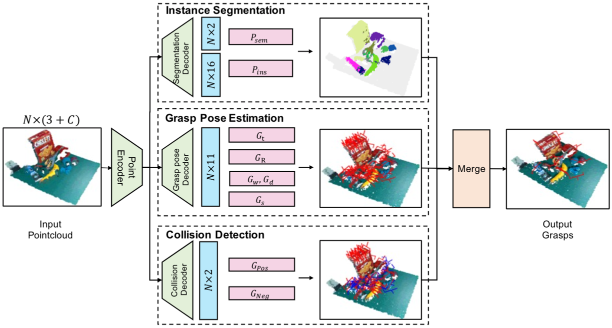
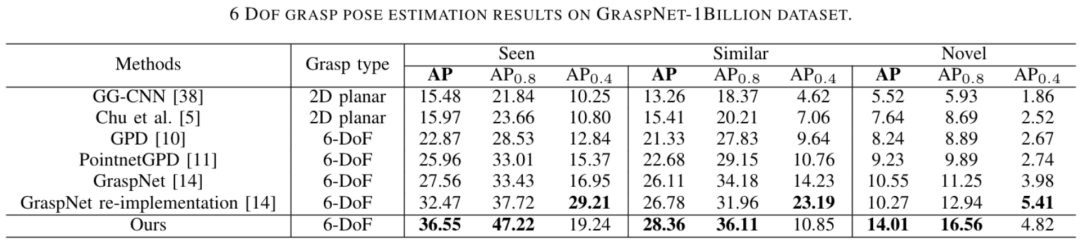
实例分割分支
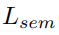 ,可以对背景和前景进行分类。
,可以对背景和前景进行分类。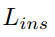 通过一个判别损失函数
通过一个判别损失函数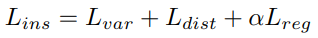 来计算:方差损失
来计算:方差损失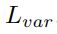 可以让属于同一个实例的点尽量向实例中心点靠近,而距离损失
可以让属于同一个实例的点尽量向实例中心点靠近,而距离损失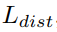 是为了增加不同实例中心之间的距离,正则化损失
是为了增加不同实例中心之间的距离,正则化损失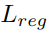 约束所有实例朝向原点,以保持激活有界。
约束所有实例朝向原点,以保持激活有界。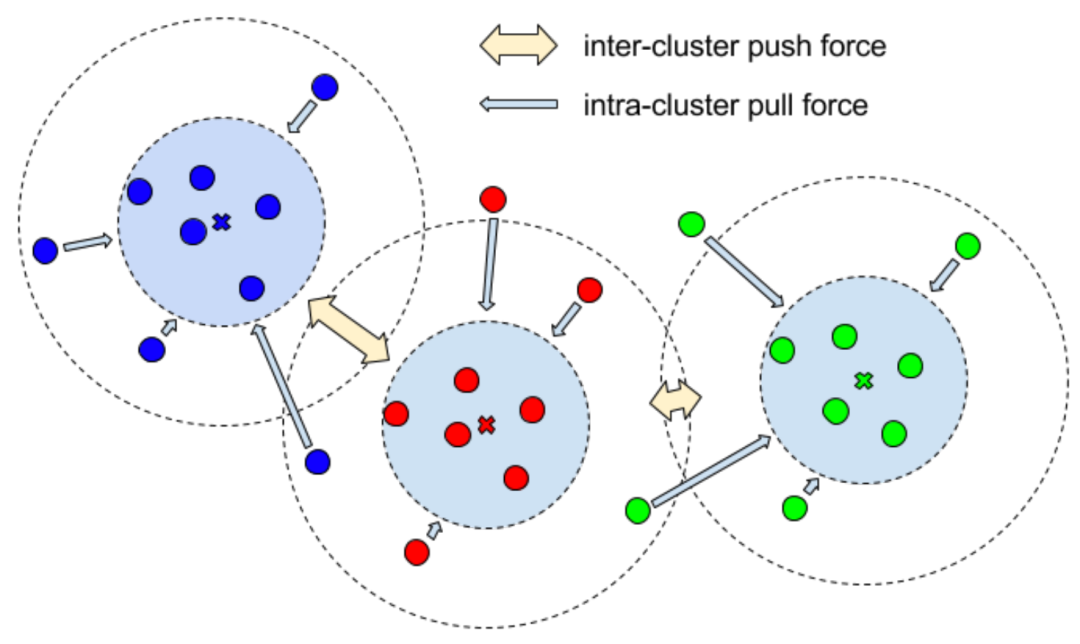
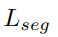 为语义损失和实例损失之和。
为语义损失和实例损失之和。六自由度抓取姿态估计分支
 ,抓持宽度损失
,抓持宽度损失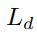 和抓持质量得分损失
和抓持质量得分损失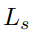 ,以此进行监督训练。
,以此进行监督训练。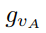 和手爪闭合的方向
和手爪闭合的方向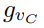 。
。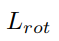 分为三个部分:偏移损失
分为三个部分:偏移损失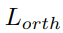 ,分别用于约束位置、角度预测和正交性。抓持宽度损失和抓持质量得分损失用均方误差(MSE)损失进行优化。
,分别用于约束位置、角度预测和正交性。抓持宽度损失和抓持质量得分损失用均方误差(MSE)损失进行优化。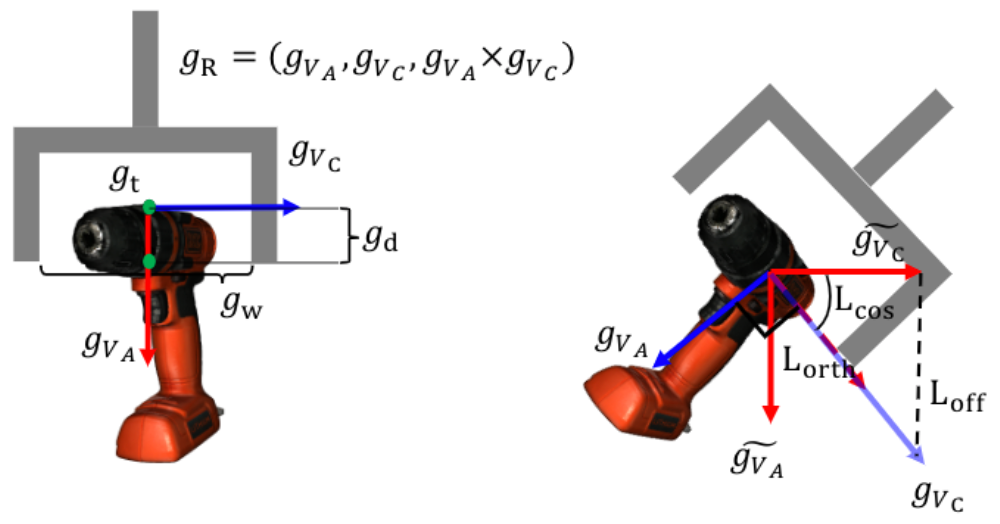
碰撞检测分支
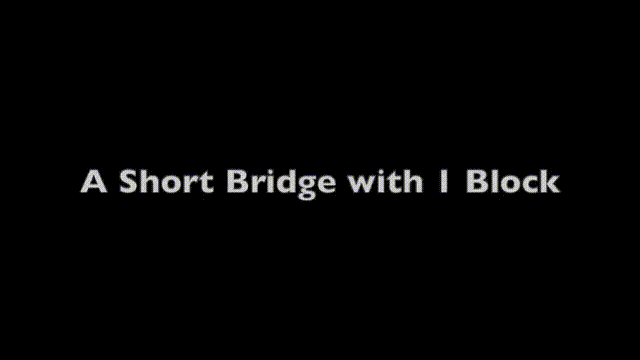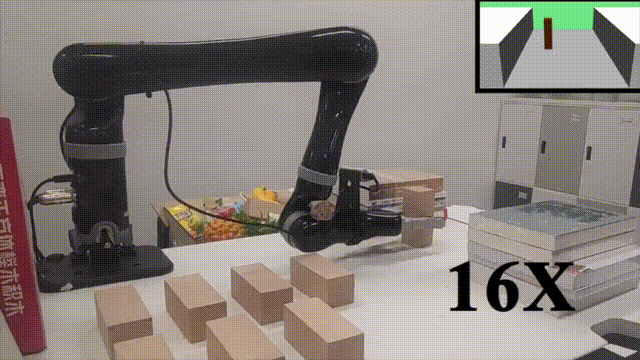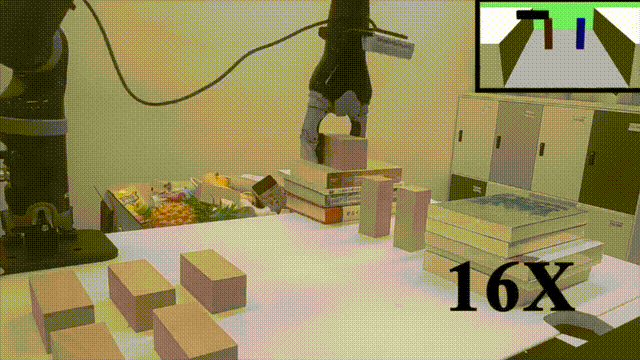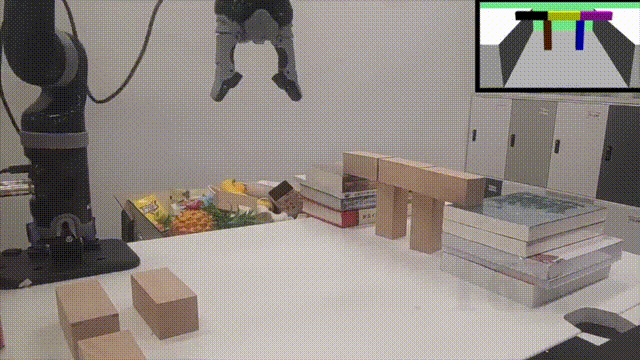

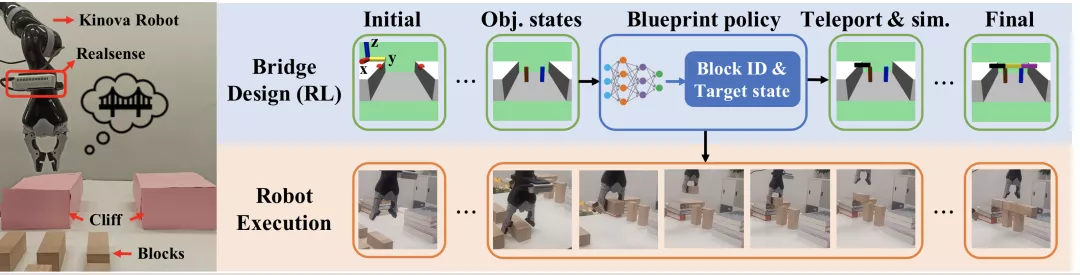
高层蓝图策略
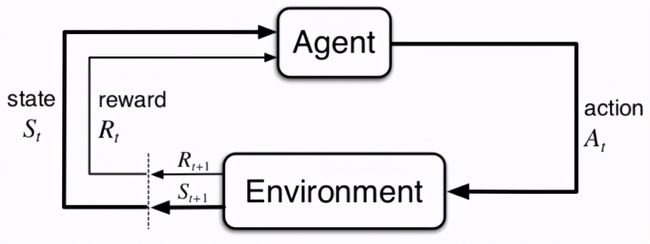
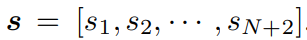 ,
,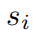 是包含三维位置、欧拉角、笛卡尔速度、角速度、表示物体是否为积木的一维物体类型指示器和一维时间组成的向量。
是包含三维位置、欧拉角、笛卡尔速度、角速度、表示物体是否为积木的一维物体类型指示器和一维时间组成的向量。
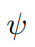 将对象和相互间关系的归纳偏差整合,传送给策略网络和价值网络,并使用PPG算法来有效地训练策略。
将对象和相互间关系的归纳偏差整合,传送给策略网络和价值网络,并使用PPG算法来有效地训练策略。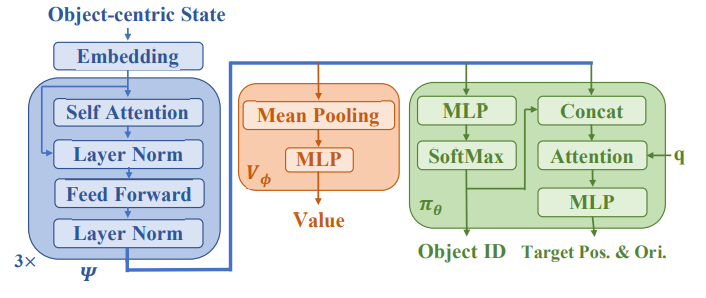
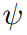 ,后接策略头
,后接策略头 和价值头
和价值头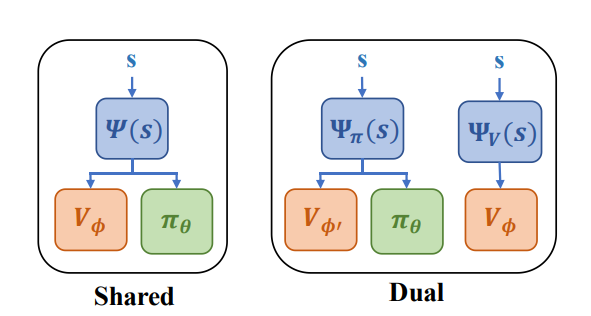
低层运动执行策略
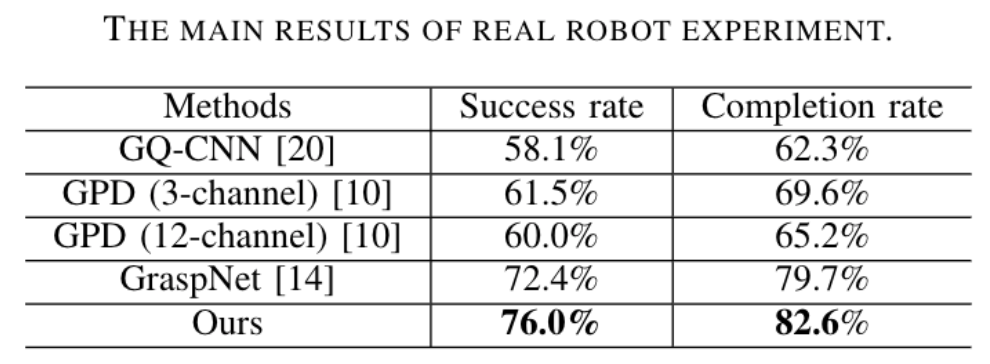
真实机器人实验

「老司机」领进门,修行在个「机器人」
接近衣架 抓取衣架 移动衣架到挂杆附近 将衣架挂在杆子上

长序列操作任务

方法实现
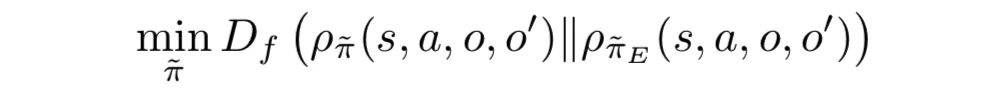
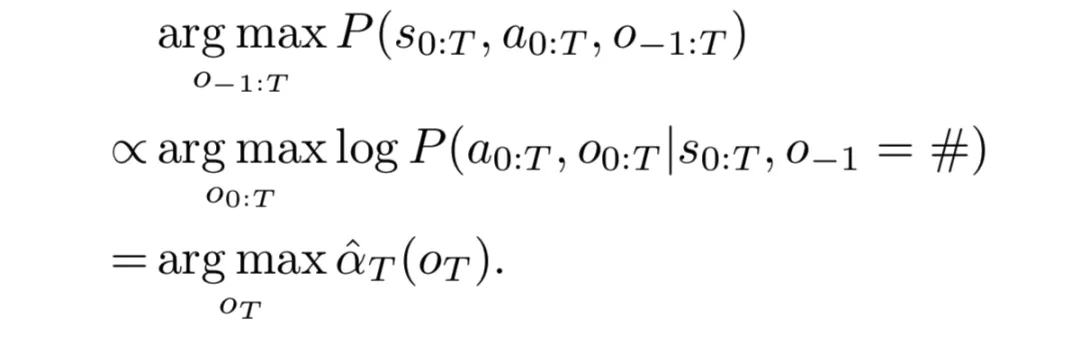
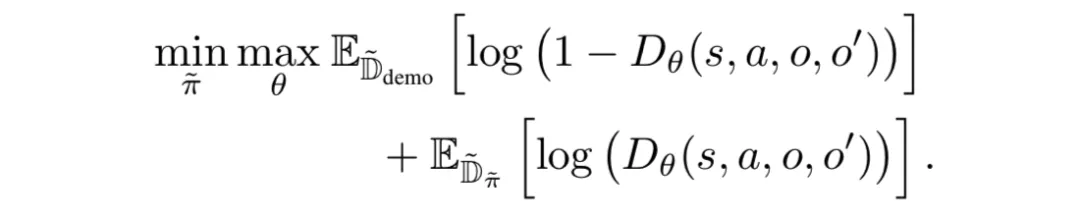
实验结果
控制单足、双足机器人运动,机器人需要在迈腿、弹跳等不同行为模式之间切换才能稳健行走; 控制蚂蚁机器人先推开迷宫里的障碍物才能走到终点; 控制机械臂关微波炉门,机械臂要靠近微波炉,抓住炉门把手,最后绕门轴旋转到关闭。
BC(纯动作克隆):只在演示数据上做监督学习,不和环境交互,也没有任何层次化的结构信息; GAIL:有在演示数据之外自己和环境交互,但没有利用长周期任务的结构信息; H-BC(层次化动作克隆):建模了层次化结构,但自己不和环境交互; GAIL-HRL:在占用率测度匹配的过程中不考虑option。
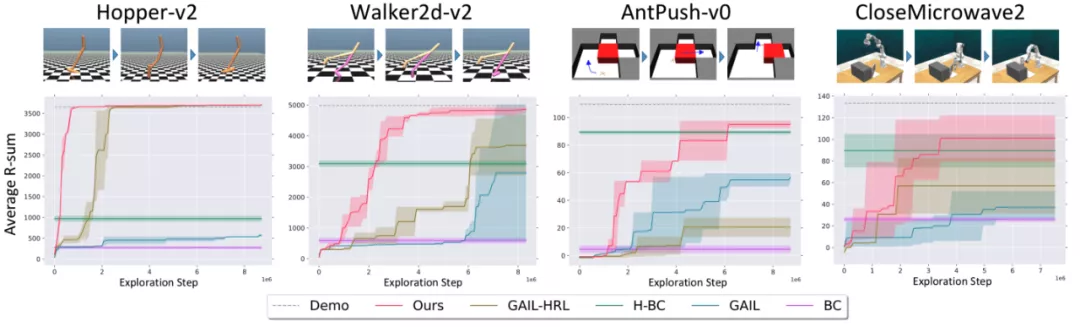
不如,一起来鼓捣机器人!
不过,技术研究到产业化落地还有很长的路要走,这就需要长期的投入和探索。希望大厂们继续努力,让机器人早日真正走进我们的生活。
参考资料:
https://mp.weixin.qq.com/s/FuC4XvgWYNMVYUjG9XoMGw
https://arxiv.org/pdf/2108.02425.pdf
https://arxiv.org/pdf/2108.02439.pdf
https://arxiv.org/pdf/2106.05530.pdf

评论