真假难辨!AI人像生成再进化!HyperHuman:基于隐式结构扩散的超逼真人像生成
大家好,今天和大家分享最新的一篇 AI生成相关的工作,本文的重点在于对于人像生成的优化,之前的工作,例如stable diffusion等,对于真人生成效果存在一定的缺陷,基于此为出发点,本文贡献了新的数据集,并提出一个新的隐式结构扩散模型结合姿态图、深度图等,生成更逼真的人像图片。
 好久没更新原创啦,兄弟们点点赞,以后多多更新,fighting!!!
好久没更新原创啦,兄弟们点点赞,以后多多更新,fighting!!!
欢迎大家留言,你更想看到的内容,实战?论文?或经验分享?
https://snap-research.github.io/HyperHuman/
https://github.com/snap-research/HyperHuman
https://snap-research.github.io/HyperHuman/content/hyperhuman.pdf
标题:HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion

背景:
现在文本到图像模型取得了重大进展,但实现超逼真的人类图像生成仍然是一项理想但尚未解决的任务。现有模型(例如stable diffusion和 DALL·E 2)往往会生成部分不连贯或姿势不自然的人像图片。为了应对这些挑战,作者认为,人类图像本质上是跨多个粒度的结构,从粗粒度的身体骨骼到细粒度的空间几何。因此,在一个模型中捕获显式外观和隐式结构之间的这种相关性对于生成连贯且自然的人像图片至关重
主要贡献:
提出了一个统一的框架 HyperHuman,它可以生成高度真实和多样化布局的开放场景下的人像图片。具体如下:
1)首先构建以人类为中心的大规模数据集,名为 HumanVerse,它由 3.4 亿张图像组成,具有人体姿势、深度和表面法向量等详细标注。
2)提出了一种隐式结构扩散模型(Latent Structural Diffusion Model),该模型可以同时对深度和表面法向量以及合成的 RGB 图像进行去噪。模型在统一网络中强制执行图像外观、空间关系和几何形状的联合学习,其中模型中的每个分支在结构意识和纹理丰富性方面相互补充。
3)最后,为了进一步提高视觉质量,提出了一种结构引导细化器来组合预测条件,以更详细地生成更高分辨率。大量的实验表明,我们的框架具有SOTA的性能,可以在不同的场景下生成超逼真的人类图像。
效果展示:






和其他算法对比:

整体框架:
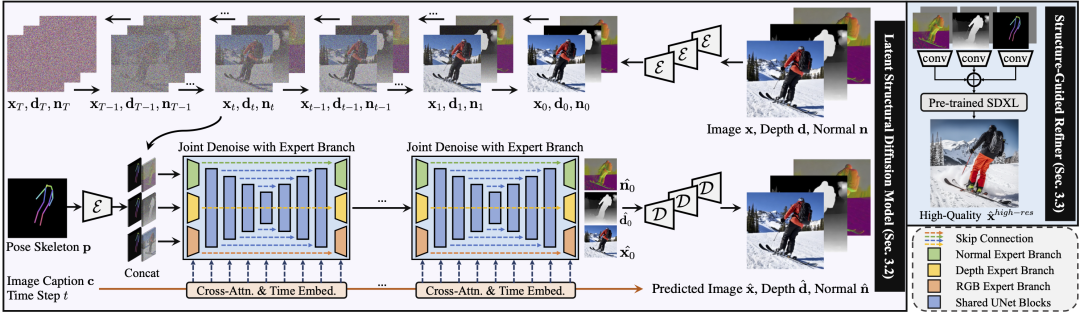
HyperHuman 框架概述。在潜在结构扩散模型(紫色)中,图像 x、深度 d 和表面法线 n 对图片描述 c 和姿势骨架 p 进行联合去噪调节。在结构引导精炼器(蓝色)中,我们构建了更高分辨率生成的预测条件。请注意,灰色图像是指随机丢弃条件,以实现更稳健的训练。
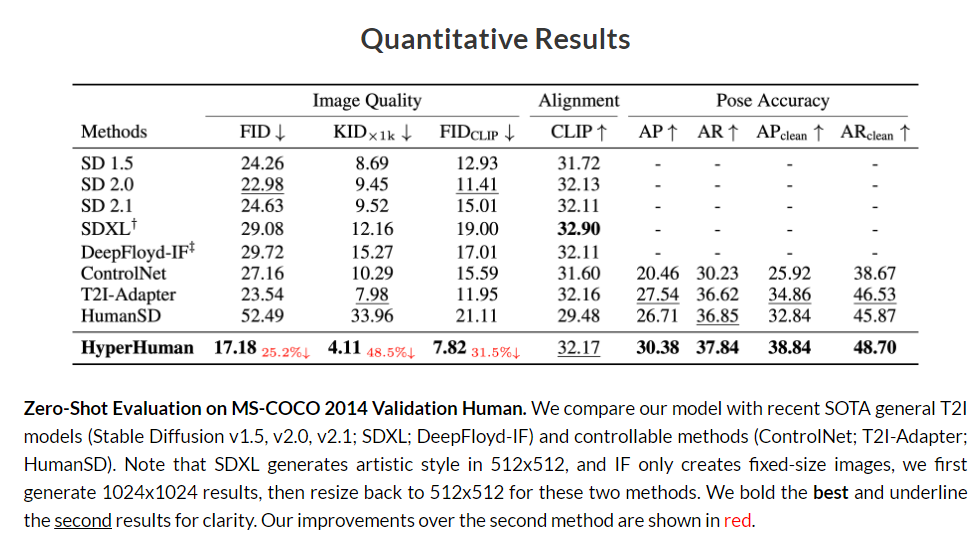
定量分析结果: