快速获取数据集的秘诀居然是……
很久很久没有动手写点什么了,近期有幸参加了 ModelArts 开发者社区组织的关于 AIGallery 的会议,AIGallery ,这是一个开放的平台,在这里可以学习和分享算法、模型、数据、Notebook、文章、课程、论文……从AI小白到大神的成长之路(PS:可惜不才没有上道,依旧是小白)。因此,希望在这里也能记录下自己的成长之路,给大家带来我以为好用的数据集生成之道,献丑了!
前言
【FBI Warning:本方法目前只局限于从某度图片获取数据且非常适合图像分类但不一定适用于实际应用场景!!!】
前端时间想体验一下零基础体验美食分类的AI应用开发,需要一个美食数据集,因此找了一些工具来获取我想要的美食图片,最终选定了 Github 上某个前端项目来批量下载指定关键字的图片到本地。本文将详细介绍那一百来行的代码究竟有何“魔力”能够助我一臂之力从某度下载大量的图片。
代码
首先,先介绍一下源代码来源:tangzihan-git/baiduImg-spider , 这是一份托管在大名鼎鼎的全球最大同性交友网站 Github 上的“开源”代码,虽然作者不曾定义该项目的 License ,姑且认为可以直接拿过来用。当然如果要将代码拷贝到本地,我们可能需要用到 Git 这个软件。废话不多说,先看看代码。
目录结构
从目录结构来看,出去 Git 忽略配置文件 .gitignore、自述说明文档 README.md 以及前端 npm 包依赖文件 package.json,核心文件也就两个:baidu-img.js 用来访问网页并输入关键字获取图片列表, imgload.js 用来下载图片。我们查看 package.json 就能看到所需的 npm 包,这里的 npm 包可以理解为引入外部的依赖,让我们的程序能够快速获得某种能力。package.json 如下:
{
"name": "spider",
"version": "1.0.0",
"description": "",
"main": "req.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start":"node baidu-img"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"axios": "^0.19.2",
"bufferutil": "^4.0.1",
"cheerio": "^1.0.0-rc.3",
"optimist": "^0.6.1",
"puppeteer": "^5.2.1",
"utf-8-validate": "^5.0.2"
}
}
dependencies 字段中定义了我们依赖的外部包,其中axios是前端项目中常用的基于Promise的HTTP客户端,可用于浏览器和node.js,我们可以理解为以前 JQuey 中的 Ajax ;Puppeteer是谷歌开源的可调用高级API来通过DevTools协议控制无头Chrome或Chromium的工具,这里用来提供一个无头的浏览器进行访问指定网页。至于其它的依赖包,代码中并没有用到,我们可以先忽略。接下来,看看代码实现。
关键代码
baidu-img.js
// 引入依赖
const puppeteer = require('puppeteer')
const url = require('url')
const path = require('path')
const imgLoad = require('./imgload')
// 定义访问地址
const httpUrl = 'https://image.baidu.com/'
var argv = require('optimist').argv;
// 入参
let options = {
word:argv.word || '图片',
num:argv.num || 60,
dir:argv.dir || 'images',
delay:argv.delay || 600
}
;( async function(){
// Puppeteer 配置
let config = {
headless:true,//无界面操作 ,false表示有界面
defaultViewport:{
width:820,
height:1000,
},
}
// 运行浏览器
let browser = await puppeteer.launch(config)
// 打开 https://image.baidu.com/
let page = await browser.newPage()
await page.goto(httpUrl)
// 定位到输入框并输入关键字,点击搜索
// 这里的 #kw .s_newBtn .main_img 都是页面的元素
await page.focus('#kw')
await page.keyboard.sendCharacter(options.word);//搜索词
await page.click('.s_newBtn')
//页面搜索跳转 执行的逻辑
page.on('load',async ()=>{
console.warn('正在为你检索【'+options.word+'】图片请耐心等待...');
await page.evaluate((options)=>{
///获取当前窗口高度 处理懒加载
let height = document.body.offsetHeight
let timer = setInterval(()=>{
//窗口每次滚动当前窗口的2倍
height=height*2
window.scrollTo(0,height);
},2000)
window.onscroll=function(){
let arrs = document.querySelectorAll('.main_img')
//符合指定图片数
if(arrs.length>=options.num){
clearInterval(timer)
console.log(`为你搜索到${arrs.length}张【${options.word}】相关的图片\n准备下载(${options.num})张`);
}
}
},options)
})
await page.on('console',async msg=>{
console.log(msg.text());
//提取图片的src
let res = await page.$$eval('.main_img',eles=>eles.map((e=>e.getAttribute('src'))))
res.length = options.num
res.forEach(async (item,i)=>{
// 下载图片
await page.waitFor(options.delay*i)//延迟执行
await imgLoad(item,options.dir)
})
// 关闭浏览器
await browser.close()
})
})()
以上的代码,类似于人的操作:打开网页-->输入关键字-->点击搜索-->浏览结果并下载。
imgload.js
const path = require('path')
const fs = require('fs')
const http = require('http')
const https = require('https')
const {promisify} = require('util')
const writeFile = promisify(fs.writeFile);
module.exports = async (src,dir)=>{
if(/\.(jpg|png|jpeg|gif)$/.test(src)){
await urlToImg(src,dir)
} else {
await base64ToImg(src,dir)
}
}
const urlToImg = (url,dir)=>{
const mod = /^https:/.test(url)?https:http
const ext = path.extname(url)
fs.mkdir(dir,function(err){
if(!err){
console.log('成功创建目录')
}
})
const file = path.join(dir, `${Date.now()}${ext}`)
//请求图片路径下载图片
mod.get(url,res=>{
res.pipe(fs.createWriteStream(file))
.on('finish',()=>{
console.log(file+' download successful');
})
})
}
//base64-download
const base64ToImg = async function(base64Str,dir){
//data:image/jpg;base64,/fdsgfsdgdfghdfdfh
try{
const matches = base64Str.match(/^data:(.+?);base64,(.+)$/)
const ext = matches[1].split('/')[1].replace('jpeg','jpg')//获取后缀
fs.mkdir(dir,function(err){
if(!err){
console.log('成功创建'+dir+'目录')
}
})
const file = path.join(dir, `${Date.now()}.${ext}`)
const content = matches[2]
await writeFile(file,content,'base64')
console.log(file+' download successful');
}catch(e){
console.log(e);
}
}
不得不佩服作者的鬼斧神工,一百来行代码就解决了我的需求!
运行
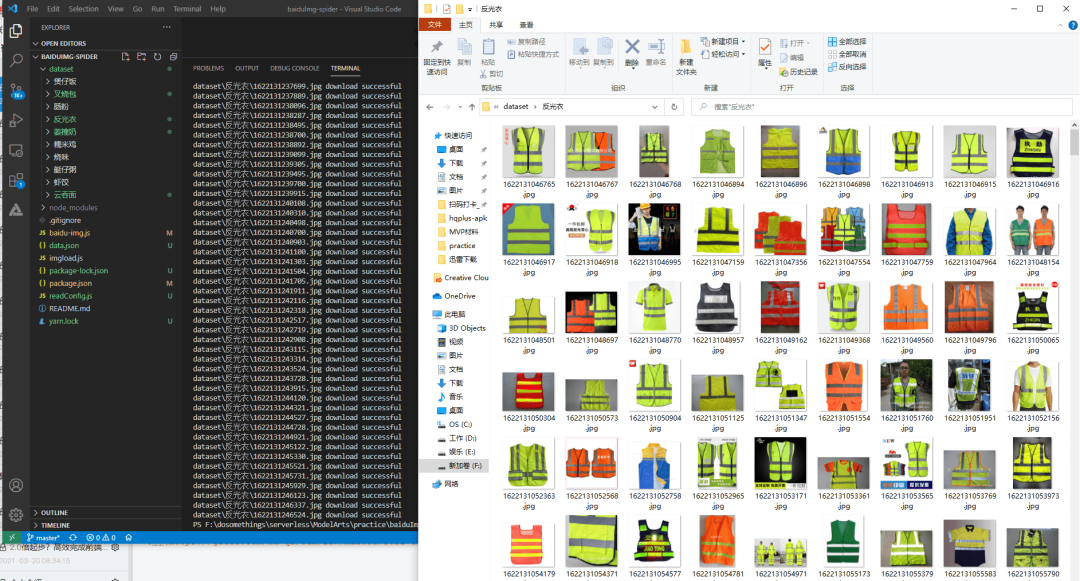
按照前端的惯例,一般需要安装一下 NodeJS ,好比业界流传的“无Node不前端”的调侃,NodeJS 是 JavaScript 的运行时,提供了服务端的能力。我们把代码下载下来之后,先安装 NodeJS,接着运行npm install安装依赖,再运行node .\baidu-img.js --word=反光衣 --num=1000 --dir=./dataset/反光衣 --delay=200就能够下载1000张反光衣的图片了,当然,往往理想是丰满的,现实往往需要我们再打磨打磨。


好像就这么简单,分享到此结束……
最后,如果您没有数据集,可以来 AIGallery 逛一逛,说不定就有合适的数据集,甚至可以直接用来训练!我在 huaweicloud.ai ,期待您的参与!