
经验之谈|处理不平衡数据集的7个技巧
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Ye Wu & Rick Radewagen
编译:ronghuaiyang
具体的领域中的数据集是什么样的,银行中的欺诈检测,市场中的实时投标,网络中的入侵检测,常见吗?
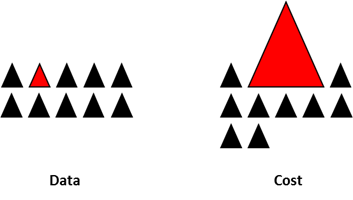
这些领域中的数据,常常只有不到1%的少数,但是“有兴趣”的事件(如信用卡欺诈,用户的广告点击或者扫描网络时的服务器的崩溃)。但是,大多数的机器学习的算法在非平衡数据集上表现的都不太好。下面的这些技巧可以帮助你,训练一个分类器来检测异常类。

在不均衡数据集上训练出来的模型,如果使用不合适的度量方法的话,是很危险的。想象一下,如果你的数据集是上面的图的情况,如果度量方法是准确率的话,那么一个模型如果对所有的样本预测都是0的话,准确率将达到非常好的99.8%,但是很显然,这种模型并没有什么鸟用。
这种情况下,可以使用一些替代的度量方法,例如:
精确度/特异性:正样本的预测准确率。
召回率/敏感性:所有预测为正样本的数据的准确率。
F1得分:精确率和召回率的调和平均。
MCC:真阳率(tpr)和假阳率(fpr)的关系。
除了使用不同的评价方法外,还可以想办法得到不同的数据集。有两个方法来得到平衡的数据集,一个是欠采样,一个是过采样。
欠采样通过减小多数类别的样本数量来得到平衡的数据集。这种方法用在数据量足够的情况下。保留所有的少数类别的样本,随机的抽取同样数量的多数类别样本,可以得到一个均衡的新的数据集,用来建模。
相反,过采样用在数据集不够的情况下。通过增加少数类的样本数量来得到平衡的数据集。这次我们不是丢掉多数类的样本,而是通过重复,自助抽样或者SMOTE (合成少数类过采样)来生成少数类的数据。
注意,这两种重新采样的方法并没有绝对的好坏之分。使用哪种方法取决于实际的数据集的情况。将两种方法组合使用也往往是可以的。
需要注意一下,当使用过采样来解决不均衡数据集的问题的时候,需要适当的使用交叉验证。
需要记住,过采样使用少数类的样本,使用自助抽样(有放回的随机抽样)是基于分布函数来生成新的随机数据。如果在过采样之后使用了交叉验证,基本上,我们所做的事情就是将模型过拟合成一个特定的人工采样的结果。这就是为什么需要在过采样数据之前使用交叉验证,就像如何来进行特征选择一样。只有在对数据进行重复采样的时候,才可以对数据集引入随机性来确保不会有过拟合的问题。
最简单的泛化模型的方法就是使用更多的数据。问题在于像逻辑回归和随机森林的分类器趋向于在泛化的时候忽略掉少数类。一个简单的最佳实践是使用所有的少数类和n个不同的多数类组成n个不同的数据集,构建模型。比如你要集成10个模型,你保留1000个少数类的样本,随机选取10000个多数类的样本,然后将这10000个多数类的样本分成10份,组成10个数据集,训练10个模型。
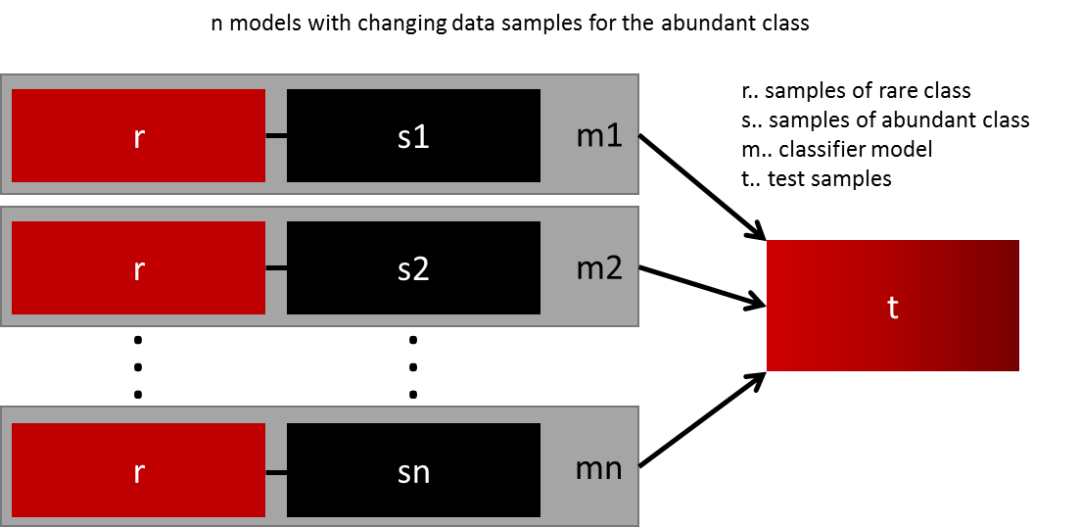
这个方法简单有效,适用于有很多数据,而且可以完美的横向扩展,因为你只需要在不同的集群的节点上训练和运行模型就可以了。集成的模型的泛化能力也会更好,这个方法简单易用。
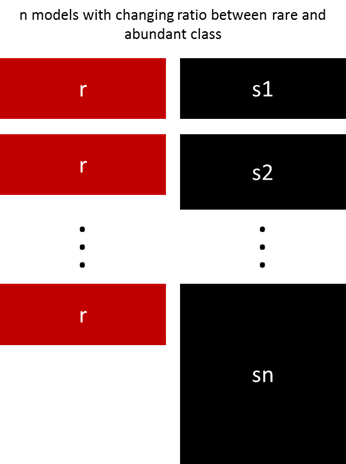
前面的方法可以通过调整少数和多数类的比例来微调。最佳的比例依赖于数据和使用的模型。不要使用同样的比例训练模型来集成,可以试试集成不同的比例。所以,如果训练了10个模型,那么使用模型具有1:1,1:2,甚至2:1,取决于用的模型,这个可以影响到一个类别得到的权值。
Sergey提出了一个优雅的方法。不是通过随机采样的方式来覆盖训练样本的多样性,他建议将多数类聚类成r个组,这个r是样本的数量。对于每一个组,样本中心保留下来,然后使用少数类和样本中心进行模型的训练。
以上所有的方法聚焦在数据上,将模型作为一个固定的部分。但是实际上,如果模型本身就是适用于非均衡数据的话,就不需要对数据进行重复的采样了。著名的XGBoost就是一个很好的尝试,如果类别不是非常的不均衡的话,因为这个算法内部本身就有在不均衡数据上集成学习的功能,当然,也会做重复采样,只不过是悄悄做的。
设计一个损失函数,对于错误分类的少数类的样本的惩罚要比多数类更大,设计许多的模型,自然的支持少数类别的泛化,也是可行的。例如,修改一下SVM中对少数类的错误分类的惩罚,设为多数样本数量和少数样本数量的比例。
这个并不是所有的技巧,只是一个处理不均衡数据的开端。没有哪个方法或者模型可以解决所有的问题,建议尝试不同的方法和模型来对工作进行评估。试着去创造和组合不同的方法。还有一点很重要,在许多的场景中(欺诈检测,实时投标),但出现不均衡类别的时候,“市场规则”是不断在变的,看看之前的数据是不是已经失效了。
英文原文链接:https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~