
写给前端的编译原理科普
昊昊是一个前端工程师,最近涉及到工程化领域,想了解一些编译的知识。恰好我比他研究的早一些,所以把我了解的东西给他介绍了一遍,于是就有了下面的对话。
什么是编译啊?
昊昊:最近想了解一些编译的东西,光哥,编译到底是什么啊?
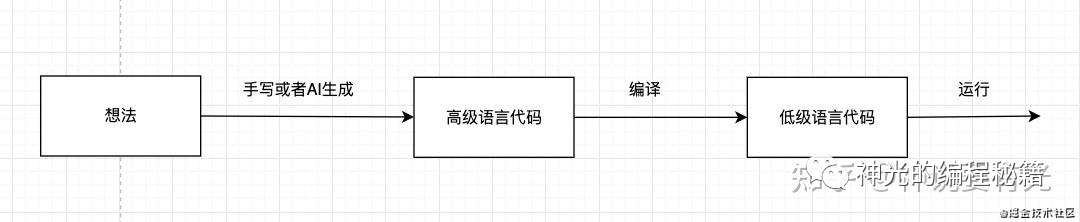
我:编译啊就是一种转换技术,从一门编程语言到另一门编程语言,从高级语言转换成低级语言,或者从高级语言到高级语言,这样的转换技术。
昊昊:什么是高级语言,什么是低级语言啊?
我: 低级语言是与机器有关的,涉及到寄存器、cpu指令等,特别“低”,描述具体在机器上的执行过程,比如机器语言、汇编语言、字节码等。高级语言则没有这些具体执行的东西,主要用来表达逻辑,而且提供了条件、循环、函数、面向对象等特性来组织逻辑,然后通过编译来把这些描述好的高级语言逻辑自动转换为低级语言的指令,这样既能够方便的表达逻辑,又不影响具体执行。说不影响执行也不太对,因为如果直接写汇编,能写出效率最高的代码,但是如果是高级语言通过编译来自动转换为低级语言,那么就难以保证生成代码的执行效率了,需要各种编译优化,这是编译领域的难点。
其实想想,我们把脑中的想法,把制订好的方案转换为高级语言代码,这个过程是不是也是转换,可不可以自动化呢,这就涉及到ai了。现在有理解需求文档生成代码的智能化技术的研究方向。
昊昊:那具体是怎么转换的呢?
我:要转换首先得了解转换的双方,要转换的是什么,转换到什么。比如高级语言到高级语言,要转换的是字符串,按照一定的格式组织的,这些格式分别叫做词法、语法,整体叫做文法,那要转换的目标呢,目标如果也是高级语言那么要了解目标语言的格式,如果目标是低级语言,比如汇编,那要了解每条指令时干啥的。然后就要进行语义等价的转换,注意这个“语义等价”,通过一门语言解释另一门语言,不能丢失或者添加一些语义,一定要前后一致才可以。
知道了转换的双方都是什么,就可以进行转换了,首先得让计算机理解要转换的东西,什么叫“计算机理解“呢?就是把我们规定的那些词法、语法格式告诉计算机,怎么告诉呢?就是数据结构,要按照一定的数据结构把源码字符串解析后的结果组织起来,计算机就能处理了。这个过程叫做 parse,要先分词,再构造成语法树。
其实不只是编译领域需要“理解”,很有很多别的领域也要“理解”:
全文搜索引擎也要先把搜索的字符串通过分词器分词,然后根据这些词去用同样分词器分词并做好索引的数据库中去查,对词的匹配结果进行打分排序,这样就是全文搜索。
人工智能领域要处理的是自然语言,他也要按照词法、语法、句法等等去“理解”,变成一定的数据结构之后,计算机才懂才能处理,然后就是各种处理算法的介入了。
分词是按照状态机来分的(有限状态机 DFA),这个是干啥的,为啥分词需要它,我知道你肯定有疑问。因为词法描述的是最小的单词的格式,比如标识符不能以数字开头,然后后面加字母数字下划线等,这种,还有关键字 if、while、continue 等,这些不能再细分了,再细分没意义啊。分词就是把字符串变成一个个的最小单元的不能再拆的单词,也叫 token,因为不同的单词格式不同,总不能写if else来处理不同的格式吧。其实还真可以,wenyan 就是if else,吐槽一下。但是当有100中单词的格式要处理,全部写成if else,我的天,那代码还能看么。所以要把每个单词的处理过程当成一种状态,处理到不同的单词格式就跳到不同的状态,跳转的方式自然是根据当前处理的字符来的,处理一个字符串从开始状态流转到不同的状态来处理,这样就是状态自动机,每个token识别完了就可以抛出来,最终产出的就是一个token数组。
其实状态也不只一级的,你想想比如一个 html 标签的开始标签,可以作为一个状态来处理,但这个状态内部又要处理属性、开始标签等,这就是二级状态,属性又可以再细分几个状态来处理,这是三级状态,这是分治的思想,一层层的处理。
分词之后我们拿到了一个个的单词,之后要把这些单词进行组装,生成 ast,为啥一定要ast呢?我知道你肯定想问。其实高级语言的代码都是嵌套的,你看低级语言比如汇编,就是一条条指令,线性的结构,但是高级语言呢,有函数、if、else、while等各种块,块之间又可以嵌套。所以自然要组织成一棵树形数据结构让计算机理解,就是Abtract Syntaxt Tree,语法树、而且是抽象的,也就是忽略了一些没有含义的分隔符,比如html的<、>、</等字符,js的{ }() [] ;就是细节,不需要关心,注释也会忽略掉,注释只是分词会分出来,但是不放到ast里面。
怎么组装呢,还是嵌套的组装,那是不是要递归组装,是的,你想的没错需要递归,不只是这里的ast组装需要递归,后面的处理也很多递归,除非到了线性的代码的阶段,就像汇编那样,你递归啥,没嵌套的结构可以递归了。
词法我们刚才分析了,就是一个个的字符串格式,语法呢,是组装格式,是单词之间的组合方式。这也是为啥我们刚刚要先分词了,要是直接从字符串来组装ast,那么处理的是字符串级别,而从token开始是单词级别, 这就像让你用积木造个城堡,但是积木也要你自己用泥巴造,那你怎么造呢,可以先把一个个积木造好,然后再去组装成城堡,也可以边造积木边组装。不过小汽车的话你可以边制作积木,边组装,城堡级别的边做积木边组装你能理清要造啥积木么,就很难,所以还是要看情况。用这两种方式来做parser的都有,简单的可以边词法分析,分析出热乎乎的单词然后马上组装到ast中, 比如html、css这种,但是像js、c++这种,如果不先分词,直接从字符串开始造ast,我只能说太生猛了。
说了半天积木和组装,那么怎么组装呢,从左到右的处理token,遇到一个token怎么知道他是啥语法呢,这就像怎么知道一块积木是属于那个部件的。也有两种思路,一种是你先确定这个积木是属于那个部件,然后找到那个部件的图纸,按照图纸来组装,另一种是你先组装,组装完了再看看这个是啥部件。这就是两种方式,先根据一两个积木确定是哪个部件,再按照图纸组装这个部件,这种是 ll 的方式,先组装,组装完了看看是啥部件,这种是 lr 的方式。ll的方式要确定组装的是啥ast节点要往下看几个,根据要看几个来确定组装的是什么就分别是LL(1),LL(2)等算法。ll也就是递归下降,这是最简单的组装方式,当然有人觉得lr的方式也挺简单。ll有个问题还必须得用lr解决,那就是递归下降遇到了左边一直往下递归不到头的情况,要消除左递归,也就是你按照图纸来组装搞不定的时候,就先组装再看看组装出来的是啥吧。这其实和人生挺像的,一种方式是往下看两步然后决定当前怎么走,另一种方式是先走,走到哪步再说。其实我就属于第二种,没啥计划性。
经过词法、语法分析之后就产生了ast。用一棵树形的数据结构来描述源代码,从这里开始就是计算机可以理解的了,后续可以解释执行、可以编译转换。不管是解释还是编译都需要先parse,也就是要先让计算机理解他是什么,然后再决定怎么处理。
后面把树形的ast转换为另一个ast,然后再打印成目标代码的字符串,这是转译器,把ast解释执行或者专成线性的中间代码再解释执行,这是解释器,把ast转成线性中间代码,然后生成汇编代码,之后做汇编和链接,生成机器码,这是编译器。
编译器是咋处理AST的?
昊昊:光哥,那编译器是怎么处理ast的啊?
我:有了ast之后,计算机就能理解高级语言代码了,但是编译器要产生低级语言,比如汇编代码,直接从ast开始距离比较远。因为一个是嵌套的、树形的,一个是线性的、顺序的,所以啊,需要先转成一种线性的代码,再生成低级代码。我觉得ast也可以算一种树形IR,IR是immediate representation中间表示的意思。要先把AST转成线性IR,然后再生成汇编、字节码等。

咋翻译,树形的结构咋变成线性的呢?明显要递归啊,按照语法结构递归ast,进行每个节点的翻译,这叫做语法制导翻译,用线性IR中的指令来翻译AST节点的属性。每个节点的翻译方式,if咋翻译、while咋翻译等可以去看下相关资料,搜中间代码生成就好了。
但是ast不能上来就转中间代码。
昊昊:为啥,ast不就能表示源码信息了么,为啥不能直接翻译成线性ir?
我:因为还没做语义检查啊,结构对不一定意思对,就像“昊昊是只猪”,这个符合语法吧,但是语义明显不对啊,这不是骂人么,所以要先做语义检查。还有就是要推导出一些信息来,才能做后续的翻译。
语义分析要检查出语义的错误,比如类型是否匹配、引用的变量是否存在、break是否在while中等,主要要做作用域分析、引用消解、类型推导和检查、正确性检查等。
作用域分析就是分析函数、块等,这些作用域内的变量都有啥,作用域之间的联系是怎样的,其实作用域是一棵树,从顶层作用域到子作用域可以生成一个树形数据结构。我记得有个做scope分析的webpack插件,他是把模块也给链接起来了,形成了一个大的 scope graph,然后做分析。
作用域中有各种声明,要把它们的类型、初始值、访问修饰符等信息记录下来,保存这个信息的结构叫符号表,这相当于是一个缓存,之后处理这个符号的时候直接去查符号表就行,不用再次从ast来找。
引用消解呢就是对每个符号检查下是否都能查找到定义,如果查找不到就报错。类型方面你比较熟,js的源码中肯定不可能都写类型,很多地方可以直接推导出来,根据ast可以得出类型的声明,记录到符号表中,之后遍历ast,对各种节点取出声明时的类型来进行检查,不一致就报错。还有其他一些琐碎的检查,比如continue、break只能出现在while中等等一些检查。
昊昊:语义分析我懂了,就是检查错误和记录一些分析出的信息到符号表,那语义分析之后呢?
语义分析之后就代表着程序已经没有语法和语义的错误了,可以放心进行各种后续转换,不会再有开发者的错误。之后先翻译成线性IR,然后对线性IR进行优化,需要优化就是因为自动生成的代码难免有很多冗余,需要把各种没必要的处理去掉。但是要保证语义不变。比如死代码删除、公共子表达式删除、常量传播等等。
线性IR的分析要建立流图,就是控制流图,控制流就是根据if、while、函数调用等导致的程序跳转,把顺序执行的代码和跳转到的代码之间连接起来就是一个图,顺序执行的代码看成一个整体,叫做基本快。之后根据这个流图做数据流分析,也就是分析一个变量流经了那些代码,然后基于这些做各种优化。
这个部分叫做程序分析,或者静态分析,是一个专门的方向,可以用于代码漏洞的静态检查,可以用于编译优化,这个是比较难的。研究这个的博士都比较少。国内只有北大和南大开设程序分析课程。
优化之后的线性IR就可以生成汇编代码了,然后通过汇编器转成机器码,再链接一些标准库,比如v8目录下可以看到builtins目录,这里就是各种编译好的机器码文件,可以静态链接成一个可执行文件。
昊昊:哦,感觉汇编和链接这两步前端接触不到啊。
我:对的,因为js是解释型语言,直接从源码解释执行,不要说js了,java的字节码也不需要静态链接。像c、c++这些生成可执行文件的才需要通过汇编器把代码专成机器码然后链接成一个文件。而且如果目标平台有这些库,那么不需要静态链接到一起,可以动态链接。你可能听过.dll和.so这就分别是windows和linux的用于运行时动态加载的保存机器码的文件。
你说的没错,前端领域基本不需要汇编和链接,就算是wasm,也是生成wasm 字节码,之后解释执行。前端主要还是转译器。
转译器是咋处理AST的?
昊昊:那转译器在ast之后又做了哪些处理呢?
我:转译器的目标代码也是高级语言,也是嵌套的结构,所以从高级语言到高级语言是从树形结构到树形结构,不像翻译成低级的指令方式组织的语言,还得先翻译成线性IR,高级到高级语言的转换,只需要ast,对ast做各种转换之后,就可以做代码生成了。
昊昊:我说呢,我就没听说babel中有线性IR的概念。
我:对的,不管是跨语言的转换,比如 ts 转 rust,还是同语言的转换js转js都不需要线性结构,两棵树的转换要啥线性中间代码啊。所以一般转译器都是 parse、transform、generate 这3个阶段。

parse 广义上来说包含词法、语法和语义的分析,狭义的parse单指语法分析。这个不必纠结。
transform 就是对ast的增删改,之后generator再把ast打印成字符串,我们解析ast的时候把[]{} () 等分隔符去掉了,generate的时候再把细节加回来。
其实前端领域主要还是转译器,因为主流js引擎执行的是源代码,但是这个源代码和我们写的源代码还不太一样,所以前端很多源码到源码的转译器来做这种转换,比如babel、typescript、terser、eslint、postcss、prettier等。
babel 是把高版本es代码转成低版本的,并且注入polyfill。typescript是类型检查和转成js代码。eslint是根据规范检查,但--fix也可以生成修复后的代码。prettier也是用于格式化代码的,比eslint处理的更多,不只限于js。postcss主要是处理css的,posthtml用于处理html。相信你也用过很多了。taro这种小程序转译器就是基于babel封装的。
解释器是咋处理AST的?
昊昊:哦,光哥,我大概知道编译器和转译器都对ast做了啥处理了,这俩都是生成代码的,那解释器呢?
我:对,首先转译器也是编译器的一种,只不过比较特殊,叫做 transpiler,一般的编译器叫做compiler。解释器和编译器的区别确实是是否生成代码,提前编译成机器代码的叫做 AOT 编译器,运行时编译成机器代码的叫做 JIT 编译器,
解释器并不生成机器代码,那它是怎么执行的呢?知道你肯定有疑问。
其实解释器是用一门高级语言来解释另一门高级语言,比如c++,一般都用c++来写解释器,因为可以做内存管理。用c++来写js解释器,像v8、spidermonkey等都是。我们在有了ast并且做完语义分析之后就可以遍历ast,然后用c++来执行不同的节点了,这种叫做tree walker解释器,直接解释执行ast,v8引擎在17年之前都是这么干的。但是在17年之后引入了字节码,因为字节码可以缓存啊,这样下次再直接执行字节码就不需要parse了。字节码是种线性结构,也要做ast到线性ir的转换,之后在vm上执行字节码。
一般解释线性代码的比如汇编代码、字节码等这种的程序才叫做虚拟机,因为机器代码就是线性的,其实从ast开始就可以解释了,但是却不叫vm,我觉得就是因为这个,和机器码比较像的线性代码的解释器才叫 vm。
不管是解释 ast 也好,还是转成字节码再解释也好,效率都不会特别高,因为是用别的高级语言来执行当前语言的代码,所以要提高效率还是得编译成机器代码,这种运行时编译就是JIT编译器,编译是耗时的,所以也不是啥代码都JIT,要做热度的统计,到达了阈值才会做JIT。然后把机器码缓存下来,当然也可能是缓存的汇编代码,用到的时候再用汇编器转成机器码,因为机器代码占的空间比较大。
可以对比v8来理解,v8 有parser、ignation解释器、turbofan编译器,还有gc。
ignation解释器就是把parse出的ast转成字节码,然后解释执行字节码,热度到达阈值之后会交给turbofan编译为汇编代码之后生成机器代码,来加速。gc是独立的做内存管理的。
turbofan是涡轮增压器,这个名字就能体现出 JIT 的意义。但JIT提升了执行速度,也有缺点,比如会使得js引擎体积更大,占用内存更大,所以轻量级的js引擎不包含jit,这就是运行速度和包大小、内存空间之间的权衡。架构设计也经常要做这种两边都可以,但是要做选择的trade off,我们叫做方案勾兑。
说到权衡,我想起rn的js引擎hermes就改成支持直接执行字节码了,在编译期间把js代码编译成字节码,然后直接执行字节码,这就是在跨端领域的js引擎的trade off。
前端领域都有哪些地方用到编译知识?
昊昊:哦,光哥,我明白解释器、编译器、转译器都干啥的了,那前端领域都有那些地方用到编译原理的知识呢?
我:其实你也肯定有个大概的了解了,但是不够明确,我列一下我知道的。
工程化领域各种转译器:babel、typescript、eslint、terser、prettier、postcss、posthtml、taro、vue template compiler等
js引擎:v8、javascriptcore、quickjs、hermes等
wasm:llvm可以生成wasm字节码,所以c++、rust等可以转为llvm ir的语言都可以做wasm开发
ide 的 lsp:编程语言的语法高亮、智能提示、错误检查等通过language service protocol协议来通信,而lsp服务端主要是基于parser对正在编辑的文本做分析
自己如何实现一门语言呢?
昊昊:我学了编译原理可以实现一门语言么?
我:其实编程语言主要还是设计,实现的话首先实现 parser 和语义分析,后面分为两条路,一种是解释执行的解释器配合JIT编译器的路,一种是编译成汇编代码码,然后生成机器码再链接成可执行文件的编译器的路。
parser部分比较繁琐,可以用 antlr 这种parser生成器来生成,语义分析要自己写,这个不太难,主要是对ast的各种处理。之后如果想做成编译器,可以用 llvm 这种通用的优化器和代码生成器,clang、rust、swift都是基于它,所以很靠谱,可以直接用。如果做解释器可以写 tree walker解释器,或者再进一步生成线性字节码,然后写个vm来解释字节码。JIT编译器也可以用llvm来做。要把ast转成llvm ir,也是树形结构转线性结构,这个还是编译领域很常见的操作。
其实编译原理只是告诉你怎么去实现,语言设计不关心实现,一门语言可以实现为编译型也可以实现为解释型,也可以做成 java 那种先编译后解释,你看 hermes(react native 实现的 js 引擎) 不就是先把 js 编译为字节码然后解释执行字节码么。语言不分编译解释,这个概念要有,c也有解释器,js也有编译器,我们说一门语言是编译型还是解释型主要是主流的方式是编译还是解释来决定的。
编程语言可以分为 GPL 和 DSL 两种。
GPL是通用编程语言,它是图灵完备的,也就是能够描述任何可计算问题,像c++、java、python、go、rust等这些语言都是图灵完备的,所以一门语言能实现的另一门语言都能实现,只不过实现难度不同。比如go语言内置协程实现,那么写高并发程序就简单,java没有语言级别的协程,那么就要上层来实现。你可能听到过设计模式是对语言缺陷的补充就是这个意思,不同语言设计思路不同,内置的东西也不同,有的时候需要运行时来弥补。、
编程语言有不同的设计思路,大的方向是编程范式,比如命令式、声明式、函数式、逻辑式等,这些大的思路会导致语言的语法,内置的实现都不同,表达能力也不同。这基本确定了语言基调,后续再补也很难,就像js里面实现函数式,你又不能限制人家不能用命令式,就很难写出纯粹的函数式代码。
DSL 不是图灵完备的,却换取了某领域的更强的表达能力,比如html、css、正则表达式,jq的选择器语法等等,比较像一种伪代码,特定领域的表达能力很强,但是却不是图灵完备的不能描述所有可计算问题。
编译原理是实现编程语言的步骤要学习的,更上层的语言设计还要学很多东西,最好能熟悉多门编程语言的特性。
我该怎么学习编译原理呢?
昊昊:光哥,那我该怎么学习编译原理呢?
我:首先你要理解编译都学什么,看我上面对编译、转译、解释的科普大概能有个印象,然后查下相关资料。知道都可以干啥了之后先写parser,因为不管啥都要先parse成ast才能被“理解”和后续处理,学下有限状态机来分词和递归下降构造ast。推荐看下vue template compiler 的 parser,这种xml的parser比较简单,适合入门。语言级别的parser细节很多,还是得找一个来debug看。不过我觉得没太大必要,一般也就写个html parser,要是语言的,可以用antlr生成。转译器肯定要了解babel,这个是前端领域很不错的转译器。
js引擎可以尝试用babel做parser,自己做语义分析,解释执行ast试试,之后进一步生成字节码或其他线性ir,然后写个vm来解释字节码。
还可以学习wasm相关技术,那个是涉及到其他语言编译到wasm 字节码的过程的。
当你学完了编译原理,就大概知道怎么实现一门编程语言了,之后想深入语言设计可以多学一些其他编程范式的语言,了解下各种语言特性,怎么设计一门表达性强的gpl或者dsl。
也可以进一步学习一下操作系统和体系结构,因为编译以后的代码还是要在操作系统上以进程的形式运行的,那么运行时该怎么设计就要了解操作系统了。然后cpu指令集是怎么用电路实现的,这个想深入可以去看下计算机体系结构。
不过,前端工程师不需要达到那种深度,但是眼界开阔点没啥坏处。
关注我,一起一步步“通关”前端工程化!