
分布式存储之GlusterFS

1.glusterfs概述
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。
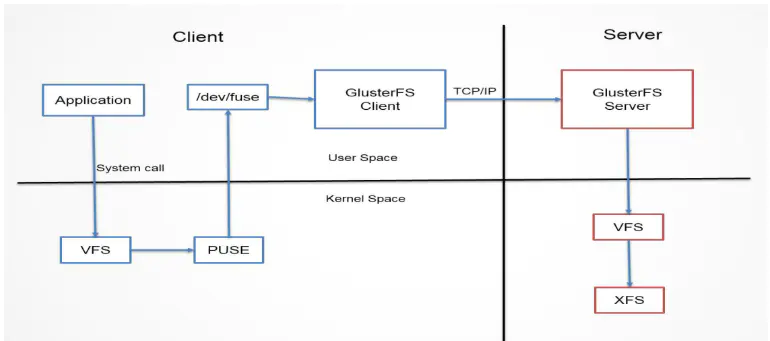
当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上。
2.glusterfs常用分布式简介
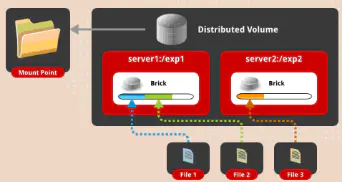
分布式卷也成为哈希卷,多个文件以文件为单位在多个brick上,使用哈希算法随机存储。
应用场景:大量小文件
优点:读/写性能好
缺点:如果存储或服务器故障,该brick上的数据将丢失
不指定卷类型,默认是分布式卷
brick数量没有限制
创建分布式卷命令:
gluster volume create volume_name node1:/data/br1 node2:/data/br1
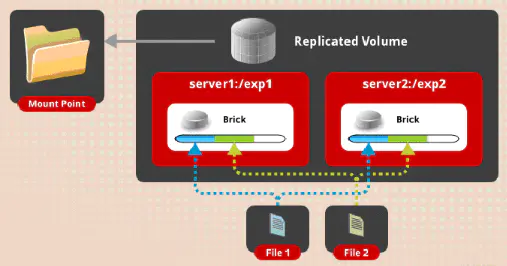
复制卷是将多个文件在多个brick上复制多份,brick的数目要与需要复制的份数相等,建议brick分布在不同的服务器上。
应用场景:对可靠性高和读写性能要求高的场景
优点:读写性能好
缺点:写性能差
replica = brick
创建复制卷:
gluster volume create volume_name replica 2 node1:/data/br1 node2:/data/br1
replica:文件保存的份数

条带卷是将文件分成条带,存放在多个brick上,默认条带大小128k
应用场景:大文件
优点:适用于大文件存储
缺点:可靠性低,brick故障会导致数据全部丢失
stripe = birck
创建条带卷:
gluster volume create volume_name stripe 2 node1:/data/br1 node2:/data/br1
stripe:条带个数
分布式条带卷是将多个文件在多个节点哈希存储,每个文件再多分条带在多个brick上存储
应用场景:读/写性能高的大量大文件场景
优点:高并发支持
缺点:没有冗余,可靠性差
brick数是stripe的倍数
创建分布式条带卷:
gluster volume create volume_name stripe 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
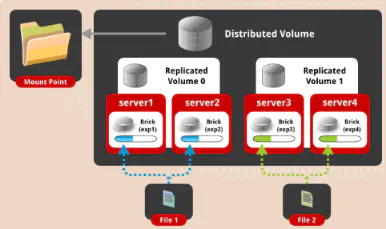
分布式复制卷是将多个文件在多个节点上哈希存储,在多个brick复制多份存储。
应用场景:大量文件读和可靠性要求高的场景
优点:高可靠,读性能高
缺点:牺牲存储空间,写性能差
brick数量是replica的倍数
gluster volume create volume_name replica 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
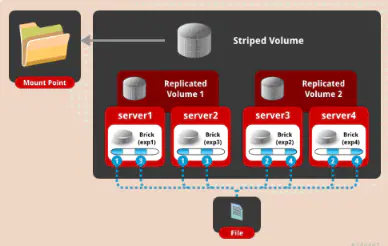
条带式复制卷是将一个大文件存储的时候划分条带,并且保存多份
应用场景:超大文件,并且对可靠性要求高
优点:大文件存储,可靠性高
缺点:牺牲空间写性能差
brick数量是stripe、replica的乘积
gluster volume create volume_name stripe 2 replica 2 node1:/data/br1 node2:/data/br1 node3:/data/br1 node4:/data/br1
3.glusterfs环境
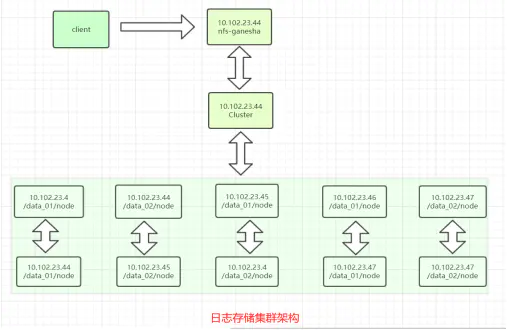
日志存储集群采用的是分布式复制卷,将多个文件在多个节点上哈希存储,在多个brick复制多份存储。共有五台服务器,磁盘空间共有90T,那么采用这种分布式复制卷的方式,只有45T磁盘空间可用。并且需要采用分布式复制卷方式需要要有双数的brick,所以现采用一台服务器上创建两个brick,如上图所示,10.102.23.4:/data_01/node和10.102.23.44:/data_01/node是备份关系,其他节点均是如此,10.102.23.44作为日志存储集群的管理节点,nfs-ganesha服务只需要安装在控制节点,客户端则可以通过nfs方式挂载。
# sed -i 's#SELINUX=enforcing#SELINUX=disabled#' /etc/sysconfig/selinux #关闭selinux
# iptables -F #清除防火墙规则
安装glusterfs(01-05)
# yum install userspace-rcu-*
# yum install python2-gluster-3.13.2-2.el7.x86_64.rpm
# yum install tcmu-runner-* libtcmu-*
# yum install gluster*
# yum install nfs-ganesha-*
#这个nfs只要需要对外挂载的哪台服务器需要安装(10.102.23.44)
# systemctl start glusterd.service #所有服务器启动glusterd
# systemctl start rpcbind
# systemctl enable glusterd.service
# systemctl enable rpcbind
# ss -lnt #查询端口是否有为24007,如果有则服务正常运行
创建集群(在10.102.23.44节点上执行一下操作,向集群中添加节点):
[root@admin-node ~]# gluster peer probe 10.102.23.44
peer probe: success. [root@admin-node ~]# gluster peer probe 10.102.23.45
peer probe: success.
[root@admin-node ~]# gluster peer probe 10.102.23.46
peer probe: success.
[root@admin-node ~]# gluster peer probe 10.102.23.47
peer probe: success.
[root@admin-node ~]# gluster peer probe 10.102.23.4
peer probe: success.
查看虚拟机信任状态添加结果
[root@admin-node ~]# gluster peer status
Number of Peers: 4
Hostname: 10.102.23.46
Uuid: 31b5ecd4-c49c-4fa7-8757-c01604ffcc7e
State: Peer in Cluster (Connected)
Hostname: 10.102.23.47
Uuid: 38a7fda9-ad4a-441a-b28f-a396b09606af
State: Peer in Cluster (Connected)
Hostname: 10.102.23.45
Uuid: 9e3cfb56-1ed4-4daf-9d20-ad4bf2cefb37
State: Peer in Cluster (Connected)
Hostname: 10.102.23.4
Uuid: 1836ae9a-eca5-444f-bb9c-20f032247bcb
State: Peer in Cluster (Connected)
在所有节点进行以下磁盘操作:
[root@admin-node ~]# fdisk /dev/sdb
创建卷组:
[root@admin-node ~]# vgcreate vg_data01 /dev/sdb1 /dev/sdc1 /dev/sdd1 /dev/sde1 /dev/sdf1
[root@admin-node ~]# vgcreate vg_data02 /dev/sdg1 /dev/sdh1 /dev/sdi1 /dev/sdj1 /dev/sdk1
查看卷组:
[root@admin-node ~]# vgdisplay
创建逻辑卷:
[root@admin-node ~]# lvcreate -n lv_data01 -L 9TB vg_data01
[root@admin-node ~]# lvcreate -n lv_data02 -L 9TB vg_data02
查看逻辑卷:
[root@admin-node ~]# lvdisplay
格式化逻辑卷:
[root@admin-node ~]# mkfs.xfs /dev/vg_data01/lv_data01
[root@admin-node ~]# mkfs.xfs /dev/vg_data02/lv_data02
挂载逻辑卷:
[root@admin-node ~]# mkdir -p /data_01/node /data_02/node
[root@admin-node ~]# vim /etc/fstab
/dev/vg_data01/lv_data01 /data_01 xfs defaults 0 0
/dev/vg_data02/lv_data02 /data_02 xfs defaults 0 0
[root@admin-node ~]# mount /data_01
[root@admin-node ~]# mount /data_02
分布式复制模式(组合型), 最少需要4台服务器才能创建。
创建卷:
[root@admin-node ~]# gluster volume create data-volume replica 2 10.102.23.4:/data_01/node 10.102.23.44:/data_01/node 10.102.23.44:/data_02/node 10.102.23.45:/data_02/node 10.102.23.45:/data_01/node 10.102.23.4:/data_02/node 10.102.23.46:/data_01/node 10.102.23.47:/data_01/node 10.102.23.46:/data_02/node 10.102.23.47:/data_02/node force
启动创建的卷:
[root@admin-node ~]# gluster volume start data-volume
volume start: data-volume: success所有机器都可以查看:
[root@admin-node ~]# gluster volume info
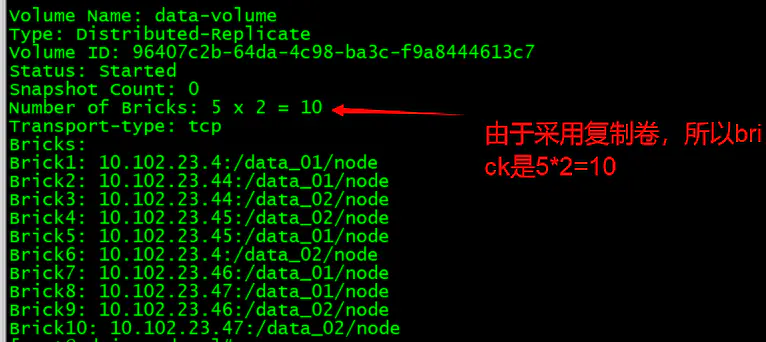
查看分布式卷的状态:
[root@admin-node ~]# gluster volume status
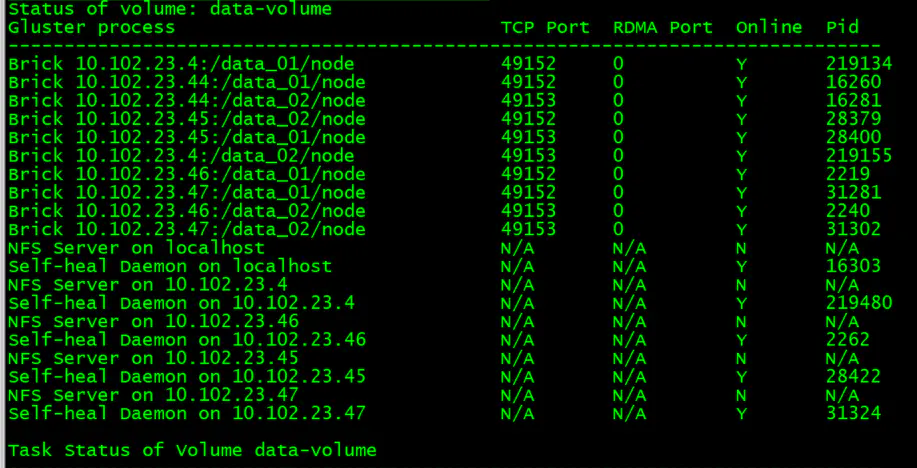
基于以上glusterfs部署,glusterfs分布式复制卷已经完成
4.nfs-ganesha环境搭建
glusterfs服务本身也是支持nfs挂载,由于现有生产环境存在多个网段,并且有些网段与glusterfs存储服务器网段是不通,所以需要通过nginx代理nfs来实现nfs挂载。Glusterfs服务只是支持nfs3版本的挂载,在通过nginx代理方面也不是那么方便,端口繁多,所以glusterfs与NFSs-Ganesha是完美组合。NFSs-Ganesha 通过FSAL(文件系统抽象层)将一个后端存储抽象成一个统一的API,提供给Ganesha服务端,然后通过NFS协议将其挂载到客户端。在客户端上对挂出来的空间进行操作。并且NFSs-Ganesha 可以指定nfs的版本。
在管理节点10.102.23.44上安装nfs-ganesha,在一开始部署glusterfs已在管理节点上安装,这里就不重复说明了,直接简要说明配置文件
[root@admin-node ~]# vim /etc/ganesha/ganesha.conf
.....................................
EXPORT
{
## Export Id (mandatory, each EXPORT must have a unique Export_Id)
#Export_Id = 12345;
Export_Id = 10;
## Exported path (mandatory)
#Path = /nonexistant;
Path = /data01;
## Pseudo Path (required for NFSv4 or if mount_path_pseudo = true)
#Pseudo = /nonexistant;
Pseudo = /data01; #客户端通过nfs挂载的根目录
## Restrict the protocols that may use this export. This cannot allow
## access that is denied in NFS_CORE_PARAM.
#Protocols = 3,4;
Protocols = 4; #客户端nfs挂载的版本
## Access type for clients. Default is None, so some access must be
## given. It can be here, in the EXPORT_DEFAULTS, or in a CLIENT block
#Access_Type = RW;
Access_Type = RW; #权限问题
## Whether to squash various users.
#Squash = root_squash;
Squash = No_root_squash; #root降级
## Allowed security types for this export
#Sectype = sys,krb5,krb5i,krb5p;
Sectype = sys; #类型
## Exporting FSAL
#FSAL {
#Name = VFS;
#}
FSAL {
Name = GLUSTER;
hostname = "10.102.23.44"; #glusterfs管理节点IP
volume = "data-volume"; #glusterfs卷名
}
}
...................
[root@admin-node ~]# systemctl restart nfs-ganesha
[root@admin-node ~]# systemctl enable nfs-ganesha
[root@admin-node ~]# showmount -e 10.102.23.44
Export list for 10.102.23.44: #nfs-ganesha搭建成功
5.客户端挂载
以glusterfs方式挂载:
[root@admin-node ~]# mkdir /logs
[root@admin-node ~]# mount -t glusterfs 10.102.23.44:data-volume /logs/
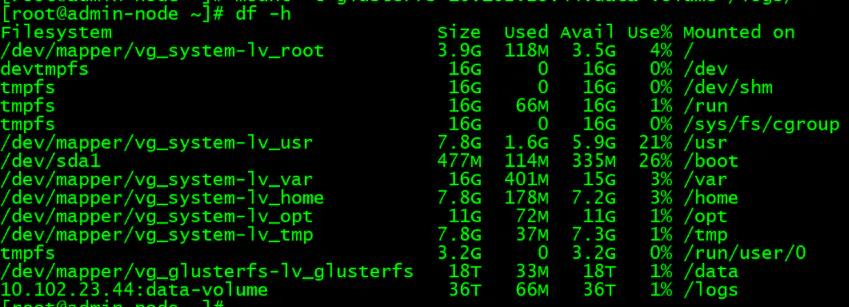
以NFS方式进行挂载:
在客户端(10.1.99段):
[root@moban-00 ~]#yum -y install nfs-utils rpcbind
[root@moban-00 ~]# systemctl start rpcbind
[root@moban-00 ~]# systemctl enable rpcbind
[root@moban-00 ~]# mkdir /home/dwweiyinwen/logs/
[root@moban-00 ~]# mount -t nfs -o vers=4,proto=tcp,port=2049 10.102.23.44:/data01 /home/dwweiyinwen/logs/
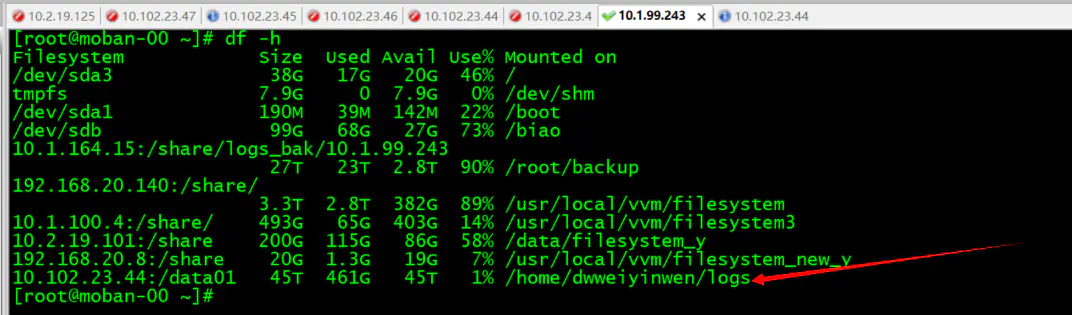
原文链接:https://www.jianshu.com/p/4b7d7a262980
关注「开源Linux」加星标,提升IT技能
