
FACIAL:更可控的说话人驱动
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
来源:AI科技评论
本文是对发表于计算机视觉领域的顶级会议 ICCV 2021的论文“FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning(具有隐式属性学习的动态谈话人脸视频生成)”的解读。

视频简介:https://m.youtube.com/watch?v=hl9ek3bUV1E
作者:张晨旭(德克萨斯大学达拉斯分校);赵一凡(北京航空航天大学);黄毅飞(华东师范大学);曾鸣(厦门大学);倪赛凤(三星美国研究院);Madhukar Budagavi(三星美国研究院);郭小虎(德克萨斯大学达拉斯分校)。
音频驱动的动态人脸谈话视频生成已成为计算机视觉、计算机图形学和虚拟现实中的一项重要技术。然而这一过程中,生成逼真的人脸视频仍然非常具有挑战性,这不仅要求生成的视频包含与音频同步的唇部运动,同时个性化、自然的头部运动和眨眼等属性也是十分重要的。动态谈话人脸合成所蕴含的信息大致可以分为两个不同的层次:
2)与语音信号具有较弱相关性的属性,即与语音上下文相关、与个性化谈话风格相关的其他属性(头部运动和眨眼)。
归纳总结上述两种不同类型的属性,我们称第一类属性为显式属性,第二类为隐式属性。
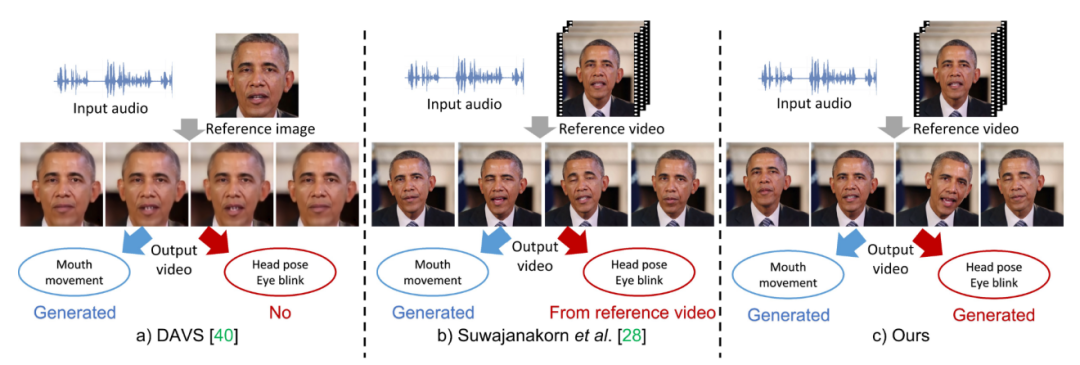
如图1所示,大多数现有生成方法只关注于人脸的显式属性生成,即通过输入语音,合成同步的唇部运动属性。这些方法合成的人脸结果要么不具有隐式属性[1,2](图1中a所示),要么复制原始视频的隐式属性[3,4](图1中b所示)。只有少部分工作[5,6]探索过头部姿势与输入音频之间的相关性。
尽管这些工作针对生成属性进行了不同侧面的探究,但是对这些属性的具体研究,仍存在以下问题:(1)显式和隐式属性如何潜在地相互影响?(2) 如何对隐式属性进行建模?例如头部姿势和眨眼等属性不仅取决于语音信号,还取决于语音信号的上下文特征以及与个体相关的风格特征。

图 2 音频驱动的隐式-显式属性联合学习的谈话人脸视频合成框架。
如图2所示,我们提出了一个人脸隐式属性学习(FACIAL)框架来合成动态的谈话人脸视频。
(1)我们的 FACIAL 框架使用对抗学习网络联合学习这一过程中的隐式和显式属性。我们提出以协作的方式嵌入所有属性,包括眨眼信息、头部姿势、表情、个体身份信息、纹理和光照信息,以便可以在同一框架下对它们用于生成说话人脸的潜在交互进行建模。
(2) 我们在这个框架中设计了一个特殊的 FACIAL-GAN网络来共同学习语音、上下文和个性化信息。这一网络将一系列连续帧作为分组输入并生成上下文隐空间向量,该向量与每个帧的语音信息一起由单独的基于帧的生成器进一步编码。因此,我们的 FACIAL-GAN 可以很好地捕获隐式属性(例如头部姿势等)、上下文和个性化信息。
(3) 我们的 FACIAL-GAN 还可以预测眨眼信息,这些信息被进一步嵌入到最终渲染模块的眼部相关的注意力图中,用于在输出视频合成逼真的眼部运动信息。实验结果和用户研究表明,我们的方法可以生成逼真的谈话人脸视频,该生成视频不仅具有同步的唇部运动,而且具有自然的头部运动和眨眼信息。并且其视频质量明显优于现有先进方法。
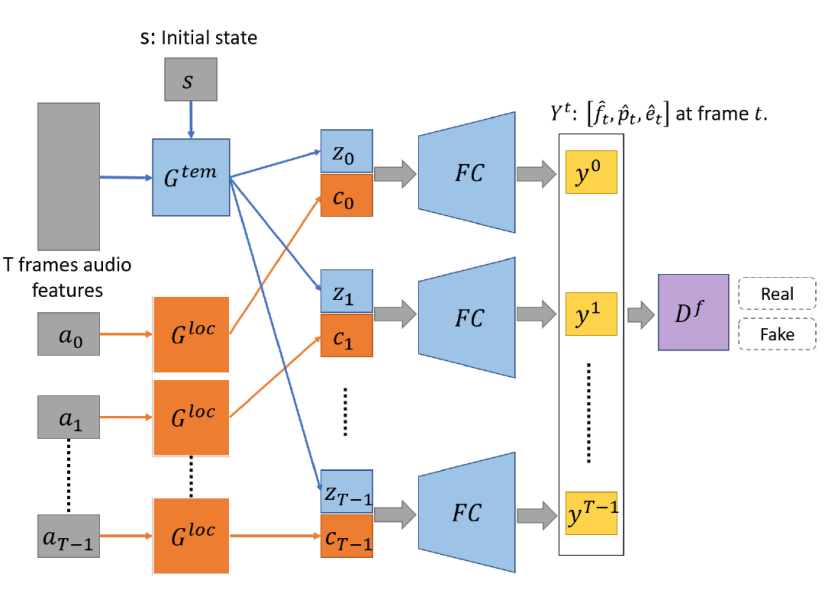
图 3 本方法提出的FACIAL-GAN网络结构框架
如图3所示,FACIAL-GAN 由三个基本部分组成:时间相关生成器用于构建上下文关系和局部语音生成器用于提取每一帧特征。此外,使用判别器网络来判断生成的属性的真假。(具体的网络细节请参考原文内容)
定性比较实验

图 4 与现有音频驱动的人脸视频生成方法的定性比较结果
如图4,图5,图6所示,我们与现有音频驱动的人脸视频生成方法进行比较。相比之下,通过显式和隐式属性的协同学习,我们的方法生成具有个性化的头部运动,考虑到不同个体的运动特性,同时可以生成更加逼真眨眼信息的人脸视频。(详细的比较结果请参考上述的视频链接)

图 5 与 Vougioukas,Chen等方法的定性对比

图 6 与 Suwajanakorn,Thies等方法的定性对比
定量比较实验
我们同时通过定量化分析实验,如关键点运动偏移,视听同步置信度进行衡量,具体信息如表1所示。本文所提出的联合隐式和显式属性生成框架,超越了大多数现有方法,在各项属性生成任务中,均具有较优的解析质量。

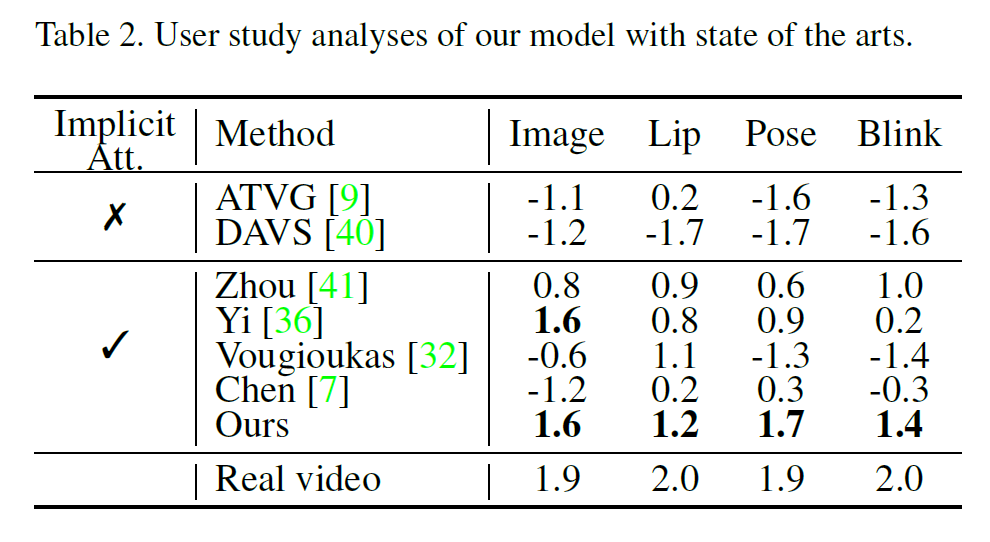
如表2所示,我们通过进行主观的用户研究(User Study),即从人类观察的角度比较生成的结果,其中更大的数值代表更优的生成质量和用户认可度。
在这项工作中,除传统的唇部运动等显式属性之外,我们以自然头部姿势和眨眼信息等隐式属性作为学习目标,优化谈话人脸视频的生成质量和真实度。但需要注意的是,人脸谈话视频仍然具有其他更细节的隐式属性,例如,眼球运动、身体和手势、微表情等等。这些属性可能受其他更深层次维度信息的引导,可能需要其他网络组件的特定设计,仍有待于未来进一步探究。我们希望本文提出的FACIAL 框架可以为未来探索隐式属性学习提供一种新颖的研究思路和启发。
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!