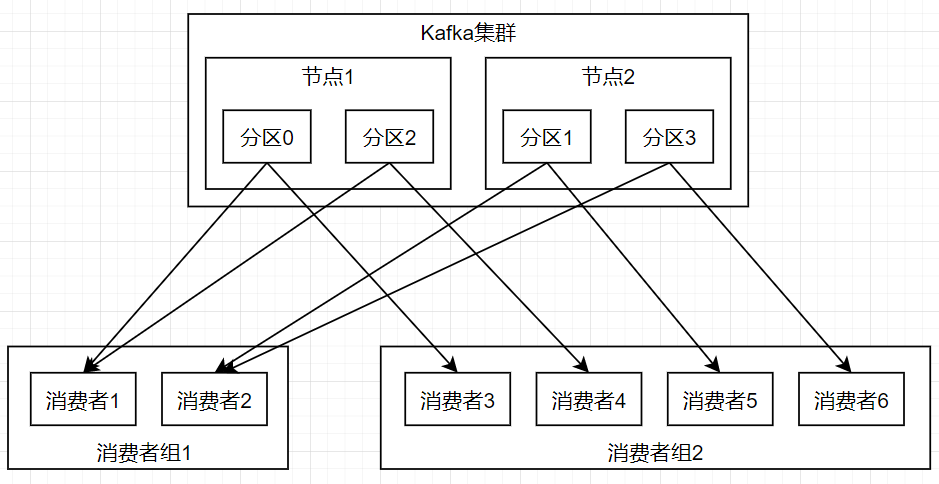
搞懂Kafka的这个问题,你离大厂就不远了!Java技术迷关注共 1479字,需浏览 3分钟 ·2021-09-22 09:58 点击关注公众号,Java干货及时送达最近,有些读者去头条二面,被面试官问了一个关于Kafka的问题:多个Kafka消费者如何同时消费相同Topic下的相同Partition的数据? 看似一个简单的问题,竟然把这位读者问懵了!今天,我们就一起来说说这个面试题,好了,开始今天的主题。题目分析首先,要明确面试官的问题:多个Kafka消费者如何同时消费相同Topic下的相同Partition的数据? 这个问题问的已经很明显了,我们只要回答出如何让多个Kafka消费者同时消费相同Topic下的相同Partition的数据就可以了。为了能够回答好这个问题,我们需要理解Kafka中的一个概念,就是 消费者组(Consumer Group)。消费者组是Kafka实现单播和广播两种消息模型的基础和手段。对于同一个Topic(主题)来说,每个消费者组都可以拿到这个Topic中的全部数据。消费者组内的所有消费者协调在一起来订阅并消费Kafka Topic中的所有分区。这里,每个分区只能由同一个消费者组内的一个消费者来消费。这里,为了更好的理解,我们简单的画一张Kafka消费消息的原理图,如下所示。在这张图中,一个主题可以配置几个分区,生产者发送的消息分发到不同的分区中,消费者接收数据的时候是按照消费者组来接收的,Kafka确保每个分区的消息只能被同一个消费者组中的同一个消费者消费,如果想要重复消费,那么需要其他的消费者组来消费。Zookeerper中保存每个主题下的每个分区在每个消费者组中消费的offset。新版kafka把这个offset保存到了一个__consumer_offsert的主题下。 这个__consumer_offsert有50个分区,通过将消费者组的id哈希值%50的值来确定要保存到那一个分区。这样也是为了考虑到Zookeeper不擅长大量数据读写的原因。所以,如果要一个消费者组用几个消费者来同时消费Kafka中消息的话,需要多线程来读取,一个线程相当于一个消费者实例。当消费者的数量大于分区的数量时,有些消费者线程会读取不到数据。扩展知识这里,我们举一个例子:假设一个主题 test 被groupA消费了,现在启动另外一个新的groupB来消费test,默认test-groupB的Offset不是0,而是还是在Kafka中还没有建立这样的一个Offset,除非当test主题有数据的时候,groupB会收到该数据,该条数据也是第一条数据,此时,groupB的Offset也是刚初始化的Offset, 除非用显式的用–from-beginning 来获取从0开始的数据。题目解答多个Kafka消费者要想同时消费相同Topic下的相同Partition的数据,则需要将这些Kafka消费者放到不同的消费者组中。往期推荐1、灵魂一问:你的登录接口真的安全吗?2、HashMap 中这些设计,绝了~3、在 IntelliJ IDEA 中这样使用 Git,贼方便了!4、计算机时间到底是怎么来的?程序员必看的时间知识!5、这些IDEA的优化设置赶紧安排起来,效率提升杠杠的!6、21 款 yyds 的 IDEA插件7、真香!用 IDEA 神器看源码,效率真高!点分享点收藏点点赞点在看 浏览 49点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 学会这21条,你离 Vim 大神就不远了!Python实用宝典0学会这21条,你离 Vim 大神就不远了!菜鸟学Python0学会这 11 条,你离 Git 大神就不远了!程序IT圈0学会这 11 条,你离 Git 大神就不远了!机器学习算法与Python实战0学会这 11 条,你离 Git 大神就不远了!杰哥的IT之旅0学会这 11 条,你离 Git 大神就不远了!良许Linux0学会这 11 条,你离 Git 大神就不远了!Python编程与实战0学会这 11 条,你离 Git 大神就不远了!Java项目开发0程序员面试指南,你离大厂Offer不远了程序IT圈0你以为大厂写得代码就不烂了?开发者技术前线0点赞 评论 收藏 分享 手机扫一扫分享分享 举报