大文件的分片上传、断点续传及其相关拓展
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
大文件的分片上传、断点续传及其相关拓展
大文件分片上传核心方法
在JavaScript中,文件FIle对象是Blob对象的子类,Blob对象包含一个重要的方法slice通过这个方法,我们就可以对二进制文件进行拆分 使用 FormData 格式进行上传 服务端接口接受到数据,通过 multiparty 库对数据进行处理 区分 files 和 fields,通过 fse.move 将上传的文件移动到目标路径下 客户端使用 Promise.all 方法,当监听到所有切片已上传完,调用 merge 接口,通知服务端进行切片的合并 使用 Stream 对切片边读边写,设置可写流的 start Promise.all判断所有切片是否写入完毕
进度条
使用浏览器 XMLHttpRequest 的 onprogress 的方法对进度进行监听
// 作为request的入参
const xhr = new XMLHttpRequest();
xhr.upload.onprogress = onProgress;
// 回调方法
onProgress: this.createProgressHandler(this.data[index])
// 接受回调,通过 e.loaded 和 e.total 获取进度
createProgressHandler(item) {
return (e) => {
item.percentage = parseInt(String((e.loaded / e.total) * 100));
};
},
复制代码
断点续传核心方法
1、通过xhr的 abort 方法,主动放弃当前请求
this.requestList.forEach((xhr) => xhr?.abort());
复制代码
2、番外篇:断点续传服务端做法
当用户在听一首歌的时候,如果听到一半(网络下载了一半),网络断掉了,用户需要继续听的时候,文件服务器不支持断点的话,则用户需要重新下载这个文件。而Range支持的话,客户端应该记录了之前已经读取的文件范围,网络恢复之后,则向服务器发送读取剩余Range的请求,服务端只需要发送客户端请求的那部分内容,而不用整个文件发送回客户端,以此节省网络带宽。 如果Server支持Range,首先就要告诉客户端,咱支持Range,之后客户端才可能发起带Range的请求。这里套用唐僧的一句话,你不说我怎么知道呢。response.setHeader('Accept-Ranges', 'bytes'); Server通过请求头中的Range: bytes=0-xxx来判断是否是做Range请求,如果这个值存在而且有效,则只发回请求的那部分文件内容,响应的状态码变成206,表示Partial Content,并设置Content-Range。如果无效,则返回416状态码,表明Request Range Not Satisfiable(www.w3.org/Protocols/r…[1] )。如果不包含Range的请求头,则继续通过常规的方式响应。
getStream(req, res, filepath, fileStat) {
res.setHeader('Accept-Range', 'bytes'); //告诉客户端服务器支持Range
let range = req.headers['range'];
let start = 0;
let end = fileStat.size;
if (range) {
let reg = /bytes=(\d*)-(\d*)/;
let result = range.match(reg);
if (result) {
start = isNaN(result[1]) ? 0 : parseInt(result[1]);
end = isNaN(result[2]) ? 0 : parseInt(result[2]);
}
};
debug(`start=${start},end=${end}`);
return fs.createReadStream(filepath, {
start,
end
});
}
复制代码
提高篇
时间切片计算文件hash:计算hash耗时的问题,不仅可以通过web-workder,还可以参考React的Fiber架构,通过requestIdleCallback来利用浏览器的空闲时间计算,也不会卡死主线程抽样hash:文件hash的计算,是为了判断文件是否存在,进而实现秒传的功能,所以我们可以参考布隆过滤器的理念, 牺牲一点点的识别率来换取时间,比如我们可以抽样算hash根据文件名 + 文件修改时间 + size 生成hash网络请求并发控制:大文件由于切片过多,过多的HTTP链接过去,也会把浏览器打挂, 我们可以通过控制异步请求的并发数来解决,这也是头条的一个面试题慢启动策略:由于文件大小不一,我们每个切片的大小设置成固定的也有点略显笨拙,我们可以参考TCP协议的慢启动策略, 设置一个初始大小,根据上传任务完成的时候,来动态调整下一个切片的大小, 确保文件切片的大小和当前网速匹配并发重试+报错:并发上传中,报错如何重试,比如每个切片我们允许重试两次,三次再终止文件碎片清理
1、时间切片计算文件hash
其实就是time-slice概念,React中Fiber架构的核心理念,利用浏览器的空闲时间,计算大的diff过程,中途又任何的高优先级任务,比如动画和输入,都会中断diff任务, 虽然整个计算量没有减小,但是大大提高了用户的交互体验
requestIdleCallback

requestIdelCallback(myNonEssentialWork);
function myNonEssentialWork (deadline) {
// deadline.timeRemaining()可以获取到当前帧剩余时间
// 当前帧还有时间 并且任务队列不为空
while (deadline.timeRemaining() > 0 && tasks.length > 0) {
doWorkIfNeeded();
}
if (tasks.length > 0){
requestIdleCallback(myNonEssentialWork);
}
}
复制代码
2、抽样hash
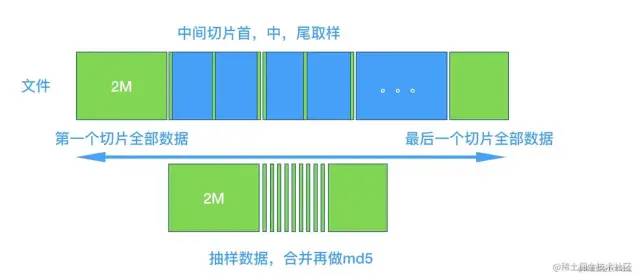
计算文件md5值的作用,无非就是为了判定文件是否存在,我们可以考虑设计一个抽样的hash,牺牲一些命中率的同时,提升效率,设计思路如下
文件切成大小为 XXX Mb的切片 第一个和最后一个切片全部内容,其他切片的取 首中尾三个地方各2个字节 合并后的内容,计算md5,称之为影分身Hash 这个hash的结果,就是文件存在,有小概率误判,但是如果不存在,是100%准的的 ,和 布隆过滤器的思路有些相似, 可以考虑两个hash配合使用我在自己电脑上试了下1.5G的文件,全量大概要20秒,抽样大概1秒还是很不错的, 可以先用来判断文件是不是不存在
3、根据文件名 + 文件修改时间 + size 生成hash
可根据File的lastModified、name、size生成hash,避免通过spark-md5对大文件进行hash计算,大大的节省时间
lastModified: 1633436262311
lastModifiedDate: Tue Oct 05 2021 20:17:42 GMT+0800 (中国标准时间) {}
name: "2021.docx"
size: 1696681
type: "application/vnd.openxmlformats-officedocument.wordprocessingml.document"
复制代码
4、网络请求并发控制
大文件hash计算后,一次发几百个http请求,计算哈希没卡,结果TCP建立的过程就把浏览器弄死了
思路其实也不难,就是我们把异步请求放在一个队列里,比如并发数是3,就先同时发起3个请求,然后有请求结束了,再发起下一个请求即可
我们通过并发数max来管理并发数,发起一个请求max--,结束一个请求max++即可
async sendRequest(forms, max=4) {
return new Promise(resolve => {
const len = forms.length;
let idx = 0;
let counter = 0;
const start = async ()=> {
// 有请求,有通道
while (idx < len && max > 0) {
max--; // 占用通道
console.log(idx, "start");
const form = forms[idx].form;
const index = forms[idx].index;
idx++
request({
url: '/upload',
data: form,
onProgress: this.createProgresshandler(this.chunks[index]),
requestList: this.requestList
}).then(() => {
max++; // 释放通道
counter++;
if (counter === len) {
resolve();
} else {
start();
}
});
}
}
start();
});
}
复制代码
5、慢启动策略实现
chunk中带上size值,不过进度条数量不确定了,修改createFileChunk, 请求加上时间统计 比如我们理想是30秒传递一个 初始大小定为1M,如果上传花了10秒,那下一个区块大小变成3M 如果上传花了60秒,那下一个区块大小变成500KB 以此类推
6、并发重试+报错
请求出错.catch 把任务重新放在队列中 出错后progress设置为-1 进度条显示红色 数组存储每个文件hash请求的重试次数,做累加 比如[1,0,2],就是第0个文件切片报错1次,第2个报错2次 超过3的直接reject
7、服务器碎片文件清理
如果很多人传了一半就离开了,这些切片存在就没意义了,可以考虑定期清理
我们可以使用 node-schedule 来管理定时任务 比如我们每天扫一次存放文件目录,如果文件的修改时间是一个月以前了,就直接删除把
// 为了方便测试,我改成每5秒扫一次, 过期1钟的删除做演示
const fse = require('fs-extra')
const path = require('path')
const schedule = require('node-schedule')
// 空目录删除
function remove(file,stats){
const now = new Date().getTime()
const offset = now - stats.ctimeMs
if(offset>1000*60){
// 大于60秒的碎片
console.log(file,'过期了,浪费空间的玩意,删除')
fse.unlinkSync(file)
}
}
async function scan(dir,callback){
const files = fse.readdirSync(dir)
files.forEach(filename=>{
const fileDir = path.resolve(dir,filename)
const stats = fse.statSync(fileDir)
if(stats.isDirectory()){
return scan(fileDir,remove)
}
if(callback){
callback(fileDir,stats)
}
})
}
// * * * * * *
// ┬ ┬ ┬ ┬ ┬ ┬
// │ │ │ │ │ │
// │ │ │ │ │ └ day of week (0 - 7) (0 or 7 is Sun)
// │ │ │ │ └───── month (1 - 12)
// │ │ │ └────────── day of month (1 - 31)
// │ │ └─────────────── hour (0 - 23)
// │ └──────────────────── minute (0 - 59)
// └───────────────────────── second (0 - 59, OPTIONAL)
let start = function(UPLOAD_DIR){
// 每5秒
schedule.scheduleJob("*/5 * * * * *",function(){
console.log('开始扫描')
scan(UPLOAD_DIR)
})
}
exports.start = start
复制代码
客户端核心代码
"app">
type="file"
:disabled="status !== Status.wait"
@change="handleFileChange"
/>
"handleUpload" :disabled="uploadDisabled"
>上传 >
"handleResume" v-if="status === Status.pause"
>恢复 >
v-else
:disabled="status !== Status.uploading || !container.hash"
@click="handlePause"
>暂停 >
计算文件 hash
"hashPercentage">
总进度
"fakeUploadPercentage">
"data">
prop="hash"
label="切片hash"
align="center"
>
"大小(KB)" align="center" width="120">
"{ row }">
{{ row.size | transformByte }}
"进度" align="center">
"{ row }">
:percentage="row.percentage"
color="#909399"
>
复制代码
服务端核心代码
index.js
const Controller = require("./controller");
const http = require("http");
const server = http.createServer();
const controller = new Controller();
server.on("request", async (req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.setHeader("Access-Control-Allow-Headers", "*");
if (req.method === "OPTIONS") {
res.status = 200;
res.end();
return;
}
if (req.url === "/verify") {
await controller.handleVerifyUpload(req, res);
return;
}
if (req.url === "/merge") {
await controller.handleMerge(req, res);
return;
}
if (req.url === "/") {
await controller.handleFormData(req, res);
}
});
server.listen(3000, () => console.log("正在监听 3000 端口"));
复制代码
controller.js
const multiparty = require("multiparty");
const path = require("path");
const fse = require("fs-extra");
const extractExt = (filename) =>
filename.slice(filename.lastIndexOf("."), filename.length); // 提取后缀名
const UPLOAD_DIR = path.resolve(__dirname, "..", "target"); // 大文件存储目录
const pipeStream = (path, writeStream) =>
new Promise((resolve) => {
const readStream = fse.createReadStream(path);
readStream.on("end", () => {
fse.unlinkSync(path);
resolve();
});
readStream.pipe(writeStream);
});
// 合并切片
const mergeFileChunk = async (filePath, fileHash, size) => {
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
const chunkPaths = await fse.readdir(chunkDir);
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
// 指定位置创建可写流
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size,
})
)
)
);
fse.rmdirSync(chunkDir); // 合并后删除保存切片的目录
};
const resolvePost = (req) =>
new Promise((resolve) => {
let chunk = "";
req.on("data", (data) => {
chunk += data;
});
req.on("end", () => {
resolve(JSON.parse(chunk));
});
});
// 返回已经上传切片名
const createUploadedList = async (fileHash) =>
fse.existsSync(path.resolve(UPLOAD_DIR, fileHash))
? await fse.readdir(path.resolve(UPLOAD_DIR, fileHash))
: [];
module.exports = class {
// 合并切片
async handleMerge(req, res) {
const data = await resolvePost(req);
const { fileHash, filename, size } = data;
const ext = extractExt(filename);
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`);
await mergeFileChunk(filePath, fileHash, size);
res.end(
JSON.stringify({
code: 0,
message: "file merged success",
})
);
}
// 处理切片
async handleFormData(req, res) {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
console.error(err);
res.status = 500;
res.end("process file chunk failed");
return;
}
const [chunk] = files.chunk;
const [hash] = fields.hash;
const [fileHash] = fields.fileHash;
const [filename] = fields.filename;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(filename)}`
);
const chunkDir = path.resolve(UPLOAD_DIR, fileHash);
// 文件存在直接返回
if (fse.existsSync(filePath)) {
res.end("file exist");
return;
}
// 切片目录不存在,创建切片目录
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
// fs-extra 专用方法,类似 fs.rename 并且跨平台
// fs-extra 的 rename 方法 windows 平台会有权限问题
// https://github.com/meteor/meteor/issues/7852#issuecomment-255767835
await fse.move(chunk.path, path.resolve(chunkDir, hash));
res.end("received file chunk");
});
}
// 验证是否已上传/已上传切片下标
async handleVerifyUpload(req, res) {
const data = await resolvePost(req);
const { fileHash, filename } = data;
const ext = extractExt(filename);
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`);
if (fse.existsSync(filePath)) {
res.end(
JSON.stringify({
shouldUpload: false,
})
);
} else {
res.end(
JSON.stringify({
shouldUpload: true,
uploadedList: await createUploadedList(fileHash),
})
);
}
}
};
文章来由掘金@火车头授权分享,https://juejin.cn/post/7071877982574346277

往期推荐


最后
欢迎加我微信,拉你进技术群,长期交流学习...
欢迎关注「前端Q」,认真学前端,做个专业的技术人...