
手把手带你用Zabbix进行操作系统监控(附PDF下载)
Zabbix默认使用Zabbix agent监控操作系统,其内置的监控项可以满足系统大部分的指标监控,因此,在完成Zabbix agent的安装后,只需在前端页面配置并关联相应的系统监控模板就可以了。如果内置监控项不能满足监控需求,则可以通过system. run[command,
下面介绍Zabbix对于Linux和Windows的监控。
安装Zabbix agent的过程就不赘述了,主要介绍一些关键的配置和功能。
▊ Zabbix agent类型的监控项
在Zabbix官方手册中,可以查看Zabbix agent类型的监控项键值说明,其中不仅列出了所有操作系统可使用的键值,还包括参数和注意事项等信息。对于Windows系统,官方还列出了其特有的监控项,如服务、性能计数器等。
同样,手册中也介绍了上述监控项对不同操作系统的适用情况,明确地指出了不同操作系统中可用及不可用的监控项。
▊ 监控项主/被动模式的选择及优化
建议使用Zabbix默认的操作系统模板监控相应的主机,但是需要一些优化来确保达到最好的监控效果,以及最大限度地减少Zabbix系统性能的开销。
下面介绍Zabbix agent(active)和Zabbix agent监控项类型的区别。
前者又名主动模式监控项类型,后者为被动模式监控项类型。这里的主动和被动都是针对Zabbix agent来说的。主动模式监控项,顾名思义,就是Zabbix agent会主动上报监控数据给Zabbix server。而被动模式监控项就是指Zabbix server根据监控项的更新间隔向Zabbix agent拉取监控数据。两者都有各自的适用范围。
在小型环境中,当主机数量为200~500台时,可以将大部分监控项设置为Zabbix agent(被动模式)类型的监控项,这样,监控数据的更新时间不会受被监控对象的系统时间的影响,更新时间都是跟着Zabbix server走的。
在中大型环境中,建议将大部分监控项设置为Zabbix agent(active)(主动模式)类型的监控项,这样,Zabbix agent会主动上报监控数据给Zabbix server,可以大大减小Zabbix系统的压力。但主动模式监控项的监控数据会受到操作系统的时间影响,当被监控对象的系统时间与Zabbix server的系统时间有偏差时,其含有nodata函数的触发器就会产生误告警。
下面以Linux模板Template OS Linux为例进行优化。
经过多年的实践经验,建议将agent ping、Host local time及所有自动发现的规则项(不是监控项原型里的)都设置为被动模式,这样就不会受到系统时间的影响了。将自动发现的监控项设为被动模式,主要是由于间隔时间太长,导致纳管主机的监控数据很久才出来,这个时候,被动模式的监控项就可以使用“check now”的功能了。
监控频率:与主机性能指标有关的监控项,如CPU、内存等,建议将频率调整为1次/分钟;而一些信息指标监控项,如Host name、Version of zabbix_agent(d) running等,建议将频率设置为1次/小时(或更长);对于模板中的自动发现监控项,如Mounted filesystem discovery、Network interface discovery等,也建议将频率设置为1次/小时;对于一些容量指标监控项,如总内存、总文件系统大小等,也都建议将频率设置为1次/小时。
关闭无用的触发器:在默认的模板中,官方提供了很多触发器,在实际使用中,用户可以根据自身需求开启/关闭。
▊ 告警抑制及触发器中宏变量的巧用
Zabbix提供了很多触发器函数,用户可以通过使用这些函数灵活地制定告警规则。下面就简单介绍一下常用在操作系统监控中的触发器函数。
(1)告警抑制。
告警抑制在监控中起到了很大的作用,可以有效减少误告警。但Zabbix没有直接相关的告警抑制选项,可以通过几个常用的触发器函数来达到抑制告警的目的。
告警抑制需求举例:如果CPU iowait连续5min都大于20%,则告警{Template OS Linux:system.cpu.util[,iowait].min(5m)}>20,表示5min内的最小值大于20%就告警,即只有5min内的数据都大于20%才告警。基本上所有的告警都可以用类似的方法进行抑制。
(2)宏变量。
Zabbix有一个特性,就是模板关联主机之后,主机中继承自模板的监控项和触发器的配置很多都是不能改的,这就导致使用者很难定制化一些告警阈值。但Zabbix提供了宏变量来解决这一问题。下面同样以CPU iowait监控项的触发器举例。
对于{Template OS Linux:system.cpu.util[,iowait].avg(5m)}>20,其中的20为固定的值,现在有一种场景:有20台主机,都套用了Linux的模板,但其中两台主机需要将CPU iowait的阈值调整成10%,其他不变。此时如果设置成固定的20,那么对于特定机器的阈值调整很难做到。解决方案如下:将模板中的触发器写成{Template OS Linux:system.cpu. util[,iowait].avg(5m)}>{$CPUIOWAIT},然后在模板的“宏”选项卡中添加一个模板宏“{$CPUIOWAIT}”,值为“20”,如图1所示。
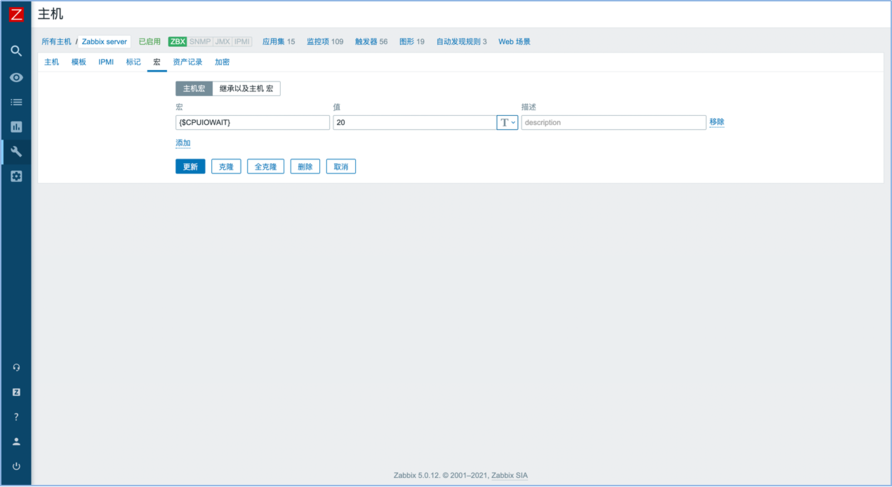
图1
这是模板宏,此时将那两台需要修改阈值的主机的宏改为10就可以了,因为在主机中,主机宏的优先级是高于模板宏的优先级的。
(3)LLD宏变量。
LLD的宏变量解决了在自动发现中单个监控项宏的问题。例如,有以下场景:一台主机中有很多文件系统,整个文件系统的告警阈值宏变量为85%,此时,有一个文件系统/opt,它的阈值需要设置为95%。为了解决这个问题,Zabbix也提供了LLD宏变量,书写方式为:
{host:vfs.fs.size[{#FSNAME},pfree].last()}<{$LOW_SPACE_LIMIT:"{#FSNAME}"}此时,在主机宏中添加“{$LOW_SPACE_LIMIT:"/opt "}”,值为“95”就可以了,如图2所示。
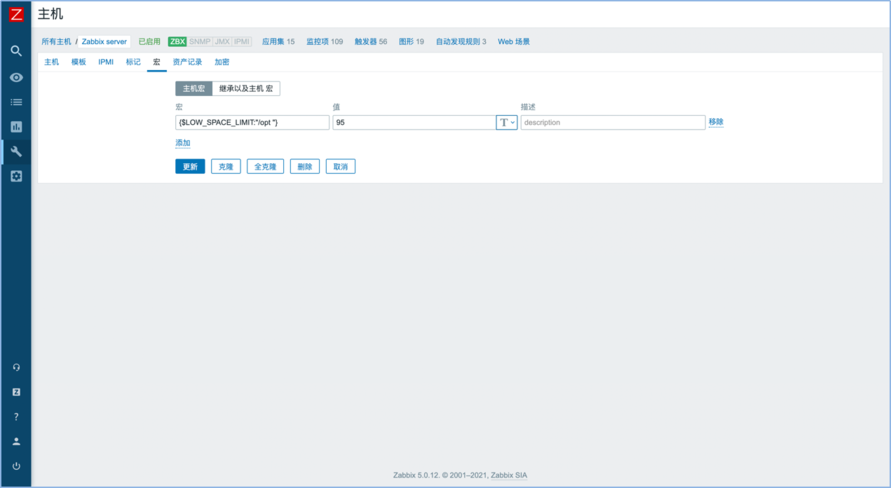
图2
本节主要介绍Linux系统中CPU、内存、文件系统相关Zabbix监控指标的使用及优化。
1.CPU使用率
Zabbix默认的CPU使用率相关的监控项共有15个,但是没有可以表示主机总体CPU使用率的监控项。可以通过创建可计算类型的监控项来监控总体的CPU使用率指标,计算逻辑为“100-system.cpu.util[,idle]”,意思是用100减去CPU的空闲值,可以比较准确地表示总体CPU的使用率。
2.内存使用率
Zabbix默认的内存键值vm.memory.size中有很多参数。
total:总物理内存。
free:可用内存。
active:RAM中当前或最近使用的内存。
inactive:未使用内存。
wired:被标记为始终驻留在RAM中的内存,不会移动到磁盘中。
pinned:和wired一样。
anon:与文件无关的内存(不能重新读取)。
exec:可执行代码,通常来自一个(程序)文件。
file:缓存最近访问文件的目录。
buffers:缓存文件系统元数据。
cached:缓存。
shared:可以同时被多个进程访问的内存。
used:active + wired 内存。
pused:active + wired 总内存的百分比。
available:inactive + cached + free memory内存。
pavailable:inactive + cached + free memory占total的百分比。
可以看到,available、pavailable是inactive + cached + free memory的可用内存,而used、pused则不是,更建议给pavailable参数的内存监控项设置告警阈值。
3.文件系统
默认模板中关于文件系统的监控项共有5个。
Free disk space on {#FSNAME}。
Free disk space on {#FSNAME} (percentage)。
Free inodes on {#FSNAME} (percentage)。
Total disk space on {#FSNAME}。
Used disk space on {#FSNAME}。
建议将文件系统的监控项改为3个,分别为总容量、已使用大小、已使用的百分比大小,这样也可以减小Zabbix的压力。
本节主要介绍Windows系统中服务、性能计数器、事件日志相关Zabbix监控指标的使用及优化。
1.Windows服务的自动发现
在大部分情况下,用户不会去关心所有Windows系统的服务,但默认模板会将所有的服务都发现出来并添加告警。对此,建议将模板中的Windows service discovery关闭,当有主机需要监控服务时,在主机上开启,并添加过滤条件来找到需要监控的服务,如图3所示。
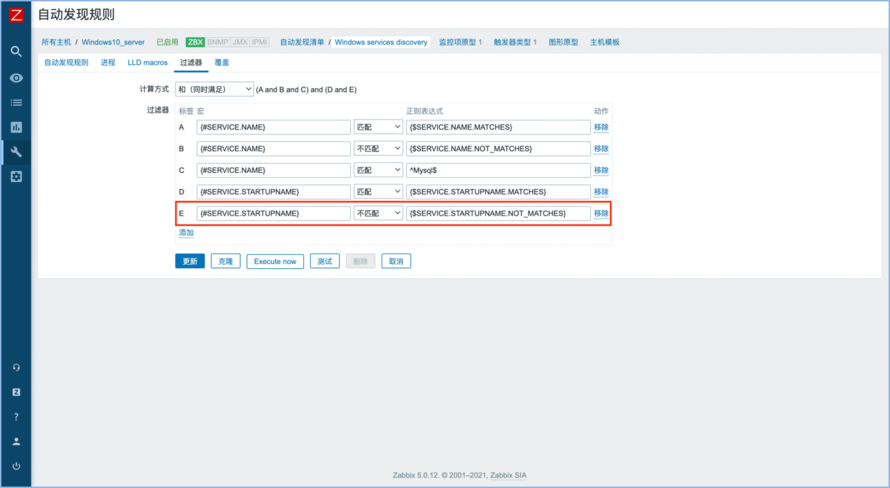
图3
2.Windows性能计数器监控
Zabbix提供了一个很重要的且专属于Windows的监控项键值perf_counter [counter,
3.Windows event log
在Windows中有一个重要的组件,就是event log。Zabbix同样提供了相应的专属键值来监控它,即eventlog[name,
打开Windows中的事件查看器,选择一个事件,如图4所示。
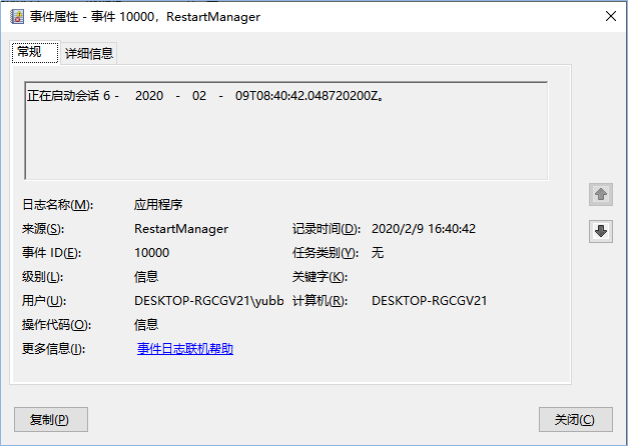
图4
可以看到,键值中的参数在图4中都有出现。
name:日志名称。
: 级别。: 来源。: 事件ID。
需要注意的是,上述参数都需要填写英文。
本文节选自《Zabbix监控系统之深度解析和实践》一书,对本书感兴趣的同学在开源Linux后台回复“225251”获取。
推荐阅读:
shell编程100例(附PDF下载)
IPv6技术白皮书(附PDF下载)
Linux主流发行版本配置IP总结(Ubuntu、CentOS、Redhat、Suse)
批量安装Windows系统
无人值守批量安装服务器
运维必备的《网络端口大全》,看这一份就够了。
收藏:服务器和存储知识入门
什么叫SSH?原理详解,看这一篇就够了!
Nginx面试40问(收藏吃灰)
20 个 Linux 服务器性能调优技巧
超详细!一文带你了解LVS四层负载均衡企业级实践!
收藏 | Linux系统日志位置及包含的日志内容介绍
100 道 Linux 常见面试题,建议收藏,慢慢读~
服务器12种基本故障+排查方法
IT运维管理常用工具大全,让你成为真正的高手
什么是QoS?
有收获,点个在看
