
吃瓜!盘点互联网宕机名场面
不点蓝字关注,我们哪来故事?
剑指大厂,一个指导程序员进入大公司/独角兽的精品社群,致力于分享职场达人的专业打法,包括「学习路线+简历模板+实习避坑+笔试面试+试用转正+升职加薪+跳槽技巧+副业外快」。
 。
。

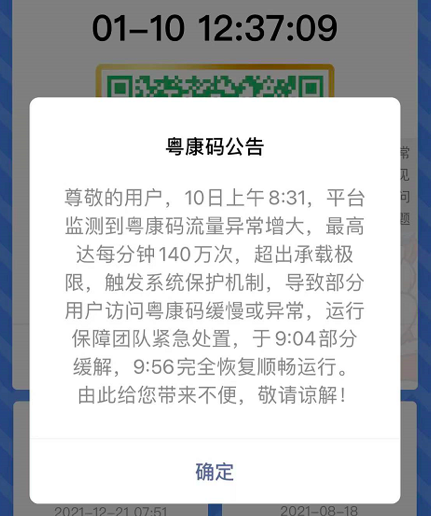
今天(10 日)上午 8:31,平台监测到粤康码流量异常增大,最高达每分钟 140 万次,超出承载极限,触发系统保护机制,导致部分用户访问粤康码缓慢或者异常,运行保障团队紧急处置,于 9:04 部分缓解,9:56 完全恢复顺畅运行。由此给您带来不便,敬请谅解!

END

若觉得文章对你有帮助,随手转发分享,也是我们继续更新的动力。
长按二维码,扫扫关注哦
✬「C语言中文网」官方公众号,关注手机阅读教程 ✬
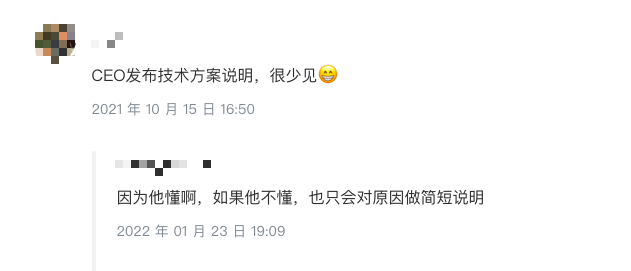
评论