
springboot第60集:架构师万字挑战,一文让你走出微服务迷雾架构周刊
提交退款申请后,通过调用该接口查询退款状态。退款有一定延时,用零钱支付的退款20分钟内到账,银行卡支付的退款3个工作日后重新查询退款状态。
注意:如果单个支付订单部分退款次数超过20次请使用退款单号查询
如果该订单支付时间超过一年半,需单独使用微信订单号查询或者同时使用微信订单号和微信退款单号查询
 image.png
image.png image.png
image.png当一个订单部分退款超过10笔后,商户用微信订单号或商户订单号调退款查询API查询退款时,默认返回前10笔和total_refund_count(订单总退款次数)。商户需要查询同一订单下超过10笔的退款单时,可传入订单号及offset来查询,微信支付会返回offset及后面的10笔,以此类推。当商户传入的offset超过total_refund_count,则系统会返回报错PARAM_ERROR。
举例:
一笔订单下的退款单有36笔,当商户想查询第25笔时,可传入订单号及offset=24,微信支付平台会返回第25笔到第35笔的退款单信息,或商户可直接传入退款单号查询退款
当交易发生之后一段时间内,由于买家或者卖家的原因需要退款时,卖家可以通过退款接口将支付款退还给买家,微信支付将在收到退款请求并且验证成功之后,按照退款规则将支付款按原路退到买家账号上。
注意:
1、交易时间超过一年的订单无法提交退款
2、微信支付退款支持单笔交易分多次退款,多次退款需要提交原支付订单的商户订单号和设置不同的退款单号。申请退款总金额不能超过订单金额。 一笔退款失败后重新提交,请不要更换退款单号,请使用原商户退款单号
3、请求频率限制:150qps,即每秒钟正常的申请退款请求次数不超过150次
4、每个支付订单的部分退款次数不能超过50次
5、如果同一个用户有多笔退款,建议分不同批次进行退款,避免并发退款导致退款失败
6、申请退款接口的返回仅代表业务的受理情况,具体退款是否成功,需要通过退款查询接口获取结果。
7、一个月之前的订单申请退款频率限制为:5000/min
8、同一笔订单多次退款的请求需相隔1分钟
当用户扫码支付成功之后,微信会异步回调商户接口,告知用户支付成功。
用户支付成功后,微信异步通知商户支付结果,商户收到通知后告知支付通知接收情况。
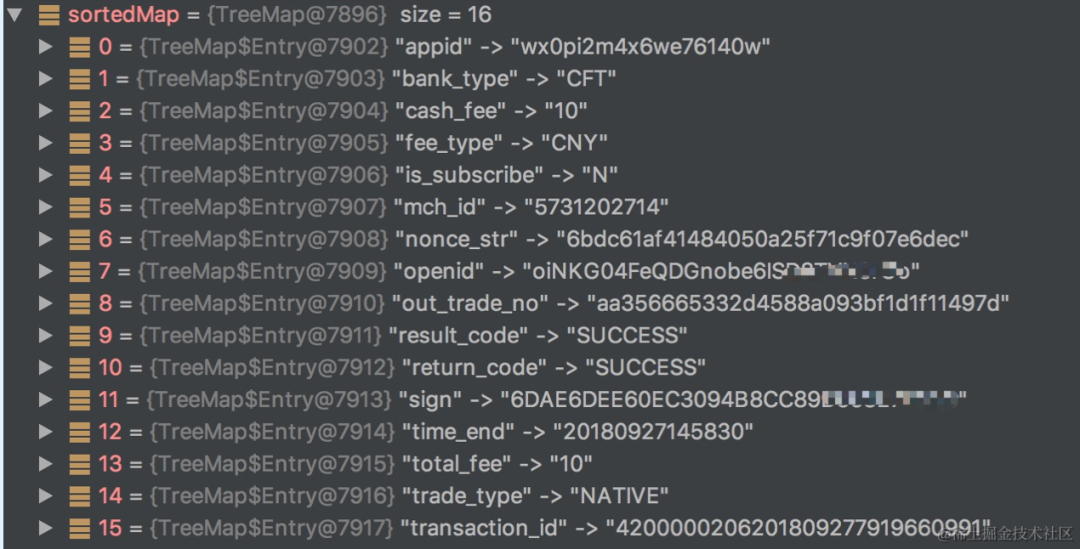 image.png
image.png有关商户接口应注意以下几点:
(1)该链接是通过【统一下单API】中提交的参数notify_url设置,如果链接无法访问,商户将无法接收到微信通知。
(2)notify_url不能有参数,外网可以直接访问,不能有访问控制(比如必须要登录才能操作)。示例:notify_url:“https://pay.weixin.qq.com/wxpay/pay.action”
(3)支付完成后,微信会把相关支付结果和用户信息发送给商户,商户需要接收处理,并返回应答。
(4)对后台通知交互时,如果微信收到商户的应答不是成功或超时,微信认为通知失败,微信会通过一定的策略定期重新发起通知,尽可能提高通知的成功率,但微信不
保证通知最终能成功。(通知频率为15/15/30/180/1800/1800/1800/1800/3600,单位:秒)注意:同样的通知可能会多次发送给商户系统。商户系统必须能够正确处理
重复的通知。推荐的做法是,当收到通知进行处理时,首先检查对应业务数据的状态,判断该通知是否已经处理过,如果没有处理过再进行处理,如果处理过直接返回结果成功。
在对业务数据进行状态检查和处理之前,要采用数据锁进行并发控制,以避免函数重入造成的数据混乱。
(5)特别提醒:商户系统对于支付结果通知的内容一定要做签名验证,防止数据泄漏导致出现“假通知”,造成资金损失。
 image.png
image.png有关商户接口应注意以下几点:
(1)该链接是通过【统一下单API】中提交的参数notify_url设置,如果链接无法访问,商户将无法接收到微信通知。
(2)notify_url不能有参数,外网可以直接访问,不能有访问控制(比如必须要登录才能操作)。示例:notify_url:“https://pay.weixin.qq.com/wxpay/pay.action”
(3)支付完成后,微信会把相关支付结果和用户信息发送给商户,商户需要接收处理,并返回应答。
(4)对后台通知交互时,如果微信收到商户的应答不是成功或超时,微信认为通知失败,微信会通过一定的策略定期重新发起通知,尽可能提高通知的成功率,但微信不
保证通知最终能成功。(通知频率为15/15/30/180/1800/1800/1800/1800/3600,单位:秒)注意:同样的通知可能会多次发送给商户系统。商户系统必须能够正确处理
重复的通知。推荐的做法是,当收到通知进行处理时,首先检查对应业务数据的状态,判断该通知是否已经处理过,如果没有处理过再进行处理,如果处理过直接返回结果成功。
在对业务数据进行状态检查和处理之前,要采用数据锁进行并发控制,以避免函数重入造成的数据混乱。
(5)特别提醒:商户系统对于支付结果通知的内容一定要做签名验证,防止数据泄漏导致出现“假通知”,造成资金损失。
回调微信统一下单接口,获取codeurl方法主要逻辑
微信官方统一下单接口文档说明: https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=9_1
(1) 根据接口需求添加所需参数:比如appid,mch_id,body等等......
(2)sign签名获取:具体获取规则官方已经说明: https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=4_3
(3) 通过工具类将map集合转为xml格式字符串
(4)回调微信统一下单接口,接口地址:https://api.mch.weixin.qq.com/pay/unifiedorder
(5)如果上一步成功(成功标志返回SUSSCUSS),则将返回成功的xml格式再通过工具类转为map
(6)通过key=code_url,获取value字符串,这也是最终生成二维码的字符串。code_url格式大致为:weixin://wxpay/s/An4baqw
接下来只要将code_url值变成二维码就可以供用户扫码付款了。
主要业务逻辑是:
(1)通过商品ID查询是否有该商品信息
(2)通过用户ID查询是否存在该用户
(3)如果上面两步没有问题,则生成用户订单信息保存到数据库中
调用http://localhost:8081/api/v1/order/buy?video_id=1接口
成功返回二维码:code_url有效期是两个小时
(1)、post方式提交
(2)、xml格式的协议
(3)、签名算法MD5
(4)、接口交易单位为 分
(5)、交易类型:JSAPI--公众号支付、NATIVE--原生扫码支付、APP--app支付
(6)、商户订单号规则:
商户支付的订单号由商户自定义生成,仅支持使用字母、数字、中划线-、下划线_、竖线|、星号*这些英文半角字符的组合,请勿使用汉字或全角等特殊字符,
微信支付要求商户订单号保持唯一性
(7)、安全规范:
签名算法:https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=4_3
校验工具:https://pay.weixin.qq.com/wiki/doc/api/native.php?chapter=20_1
(8)、采用微信支付扫码模式二(不依赖商户平台设置回调url)
 image.png
image.png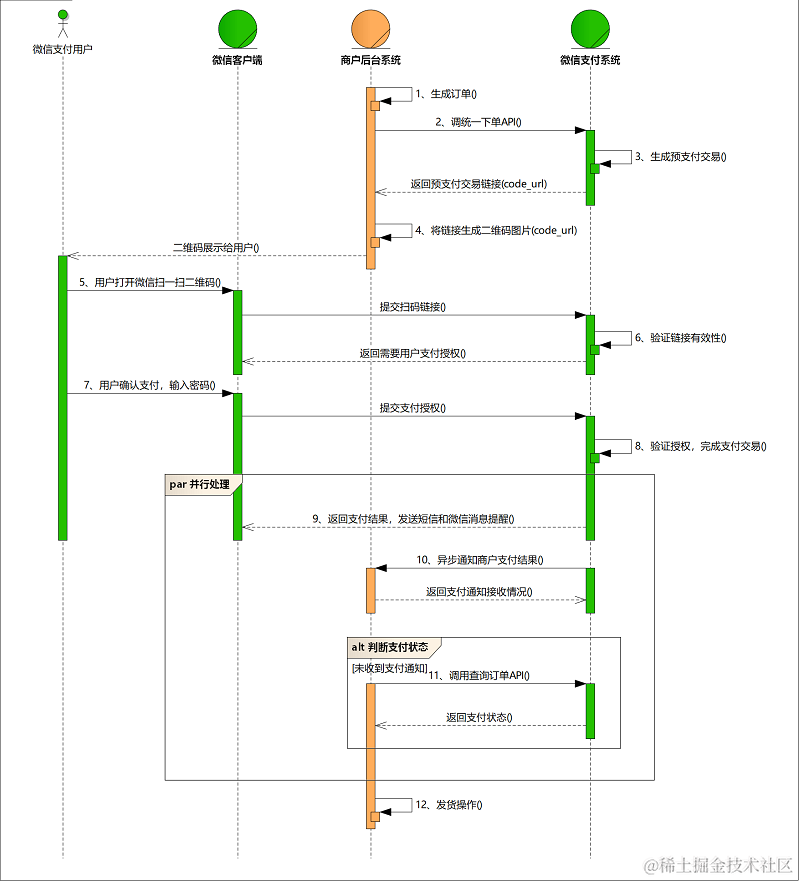 image.png
image.png商户后台系统先调用微信支付的统一下单接口,微信后台系统返回链接参数code_url,商户后台系统将code_url值生成二维码图片,用户使用微信客户端扫码后发起支付。注意:code_url有效期为2小时,过期后扫码不能再发起支付。
 image.png
image.png image.png
image.png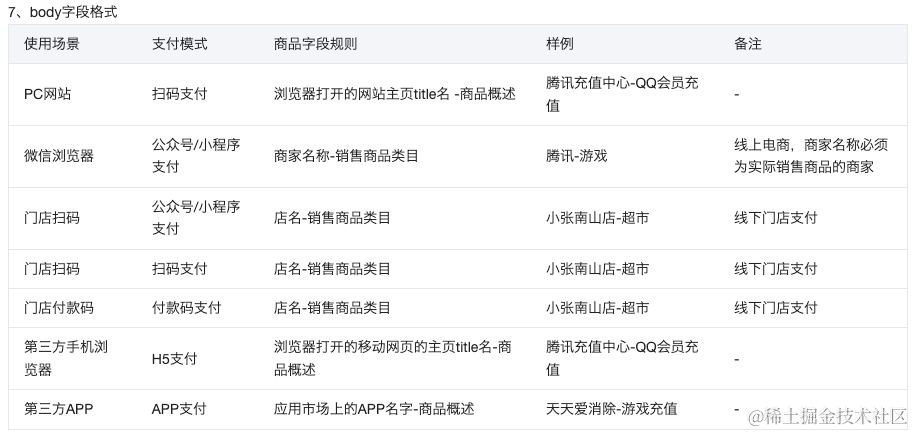 image.png
image.png image.png
image.png image.png
image.png image.png
image.png微信支付申请审核通过后,商户在申请资料填写的邮箱中收取到由微信支付小助手发送的邮件
 image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png image.png
image.png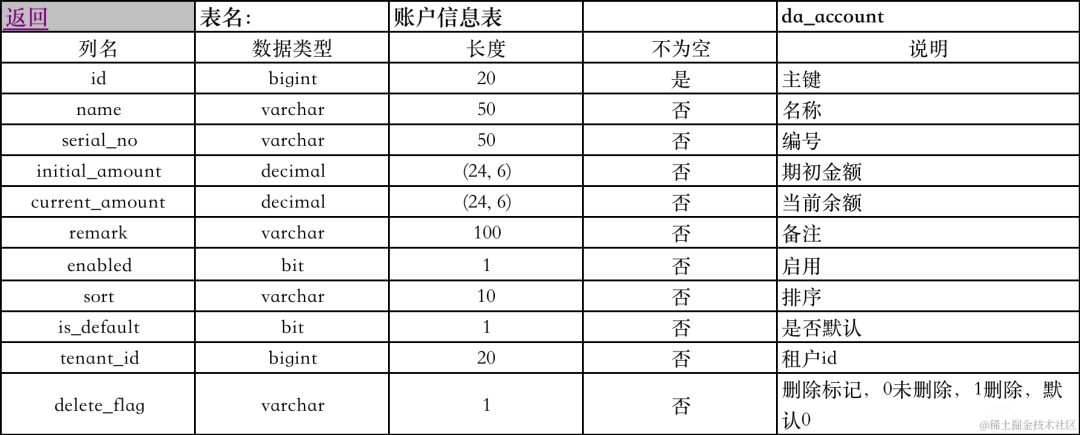 image.png
image.png image.png
image.png项目的质量目标:
- 通过系统呈现的小程序或网站实现企业建设的各区域新能源管理,能够远程启动充电,强制停止,功率限制等控制指令;
- 能够自行分析新能源运营情况;
- 从多个统计维度,特征指标来分析新能源收入的分布和变化规律;
- 全面地了解企业整体营收情况
场景 为了防止我们的接口被人恶意访问,比如有人通过JMeter工具频繁访问我们的接口,导致接口响应变慢甚至崩溃,所以我们需要对一些特定的接口进行IP限流,即一定时间内同一IP访问的次数是有限的。
实现原理 用Redis作为限流组件的核心的原理,将用户的IP地址当Key,一段时间内访问次数为value,同时设置该Key过期时间。
比如某接口设置相同IP10秒内请求5次,超过5次不让访问该接口。
这是一个使用 MyBatis 的 XML 配置文件,用于映射数据库表 tab_user 到 Java 对象 com.da.entity.User。
以下是这个 XML 配置文件的主要部分:
- mapper 标签: 定义了命名空间为
com.da.mapper.UserMapper,用于映射数据库操作。 - resultMap 标签: 定义了查询结果的映射规则,指定了从数据库查询结果到
com.da.entity.User对象属性的映射关系。 - sql 标签: 定义了一个 SQL 片段,名为
Base_Column_List,用于提供表的列名列表,可以在后续的 SQL 语句中重复使用。 - select 标签: 定义了一个查询语句,id 为
selectAll,执行该语句会查询tab_user表中的所有列,并将结果映射为com.da.entity.User对象。 - insert 标签: 定义了一个插入语句,id 为
insert,用于向tab_user表中插入数据,参数类型为com.da.entity.User,并指定了插入的列和值。
这个 XML 配置文件的作用是提供了 MyBatis 操作数据库的映射规则和 SQL 语句,使得开发者可以通过调用对应的方法来执行数据库操作,而不必编写繁琐的 SQL 语句。
注意 ShardingSphere并不支持CASE WHEN、HAVING、UNION (ALL),有限支持子查询。这个官网有详细说明。
实现分表
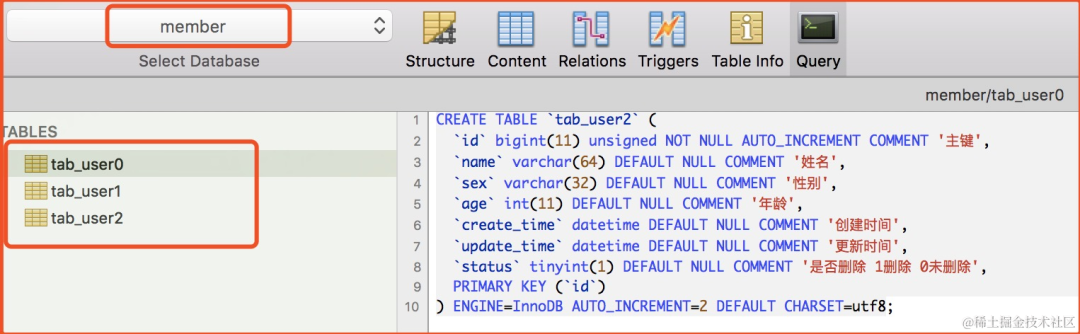 image.png
image.png有个member库,里面的tab_user表由一张拆分成3张,分别是tab_user0、tab_user1、tab_user2。
如果表的数据过大,我们可能需要把一张表拆分成多张表,但不分库。
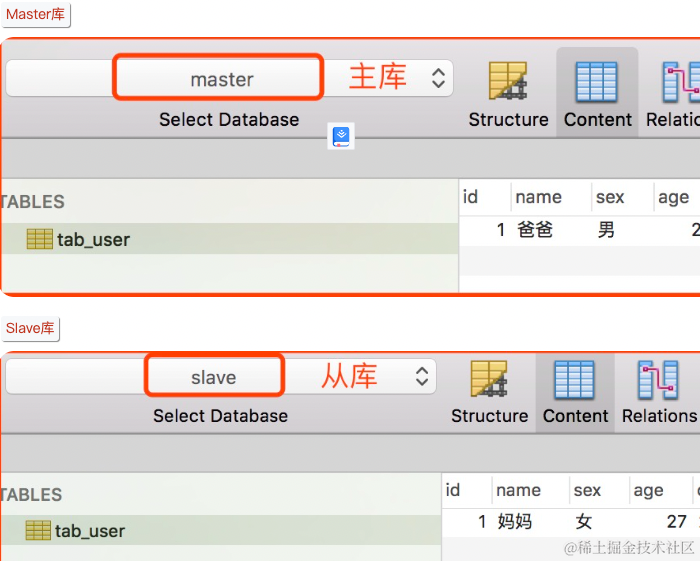 image.png
image.pngMysql是 Master-Slave (主从)部署的,那么数据保存到Master库,Master库数据同步数据到Slave库,数据读取到Slave库,
这样可以减缓数据库的压力。同一个服务器建立两个库,一个当做Master库,一个当做Slave库。
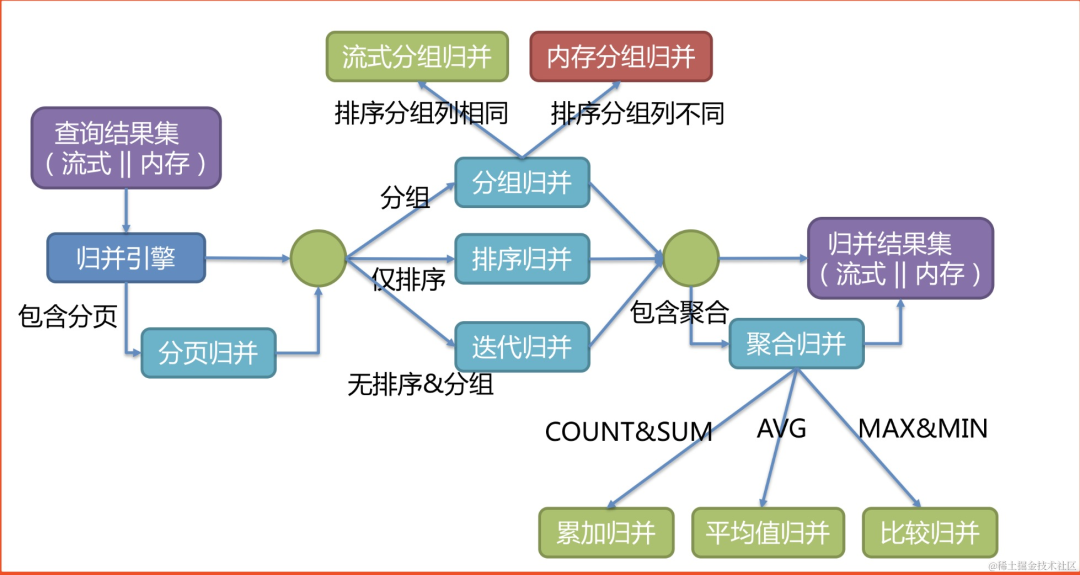 image.png
image.png通过分数进行排序的示例图。 图中展示了3张表返回的数据结果集,每个数据结果集已经根据分数排序完毕,但是3个数据结果集之间是无序的。
将3个数据结果集的当前游标指向的数据值进行排序,并放入优先级队列,t_score_0的第一个数据值最大,t_score_2的第一个数据值次之,t_score_1的第一个数据值最小,
因此优先级队列根据t_score_0,t_score_2和t_score_1的方式排序队列。
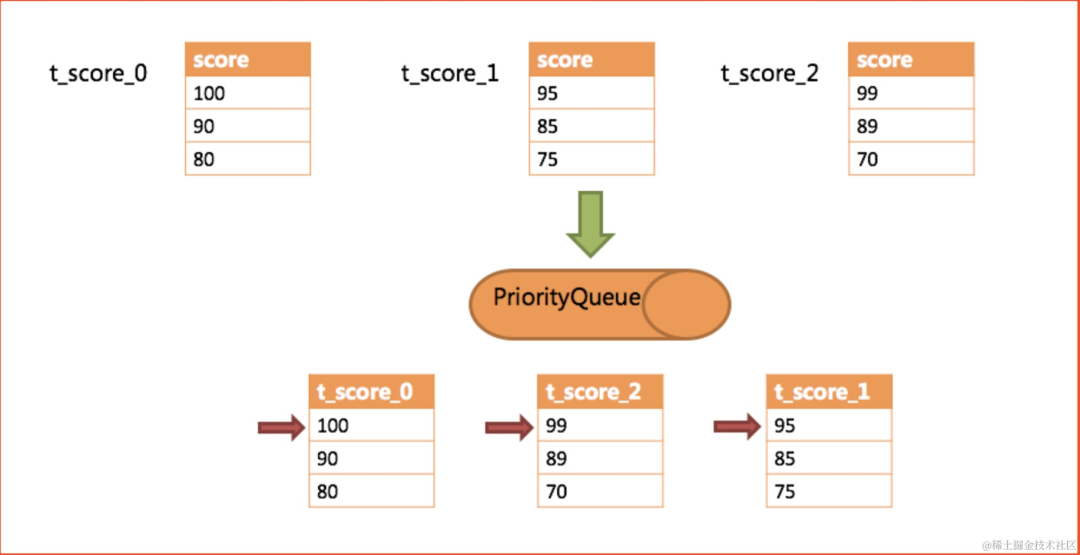 image.png
image.png展现了进行next调用的时候,排序归并是如何进行的。 通过图中我们可以看到,当进行第一次next调用时,排在队列首位的t_score_0将会被弹出队列,并且将当前
游标指向的数据值(也就是100)返回至查询客户端,并且将游标下移一位(90)之后,重新放入优先级队列。根据当前数值,t_score_0排列在队列的最后一位。 之前队列中
排名第二的t_score_2的数据结果集则自动排在了队列首位。
在进行第二次next时,只需要将目前排列在队列首位的t_score_2弹出队列,并且将其数据结果集游标指向的值返回至客户端,并下移游标,继续加入队列排队,以此类推。
当一个结果集中已经没有数据了,则无需再次加入队列。
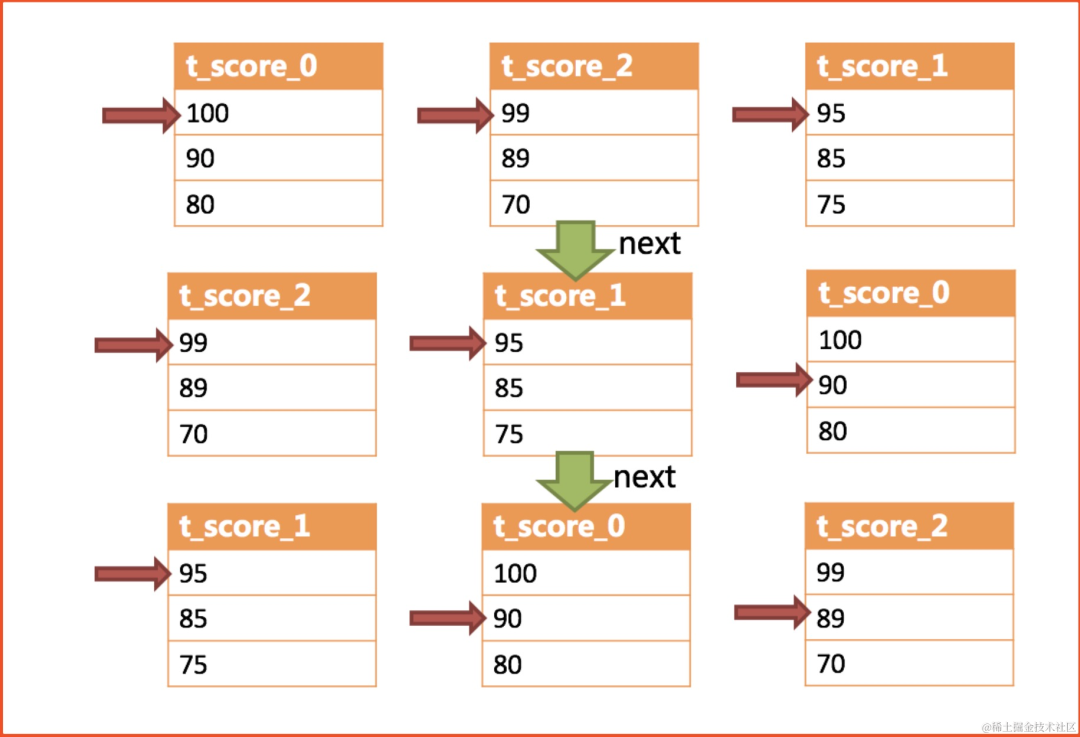 image.png
image.png可以看到,ShardingSphere的排序归并,是在维护数据结果集的纵轴和横轴这两个维度的有序性。
纵轴是指每个数据结果集本身,它是天然有序的,它通过包含ORDER BY的SQL所获取。
横轴是指每个数据结果集当前游标所指向的值,它需要通过优先级队列来维护其正确顺序。 每一次数据结果集当前游标的下移都需要将该数据结果集重新放入优先级队列排序,
而只有排列在队列首位的数据结果集才可能发生游标下移的操作。
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
我们在实现分库分表之后,遍历、排序、分组、分页 和 聚合 操作变成不在一张表上进行SQL,而是多张表执行的结果进行归并。
它是最为简单的归并方式。 只需将多个数据结果集合并为一个单向链表即可。在遍历完成链表中当前数据结果集之后,将链表元素后移一位,继续遍历下一个数据结果集即可。
由于在SQL中存在ORDER BY语句,每个数据结果集自身是有序的,所以我们要做的就是对多个有序的数组进行排序
ShardingSphere在对排序的查询进行归并时,将每个结果集的当前数据值进行比较(通过实现Java的Comparable接口完成),并将其放入优先级队列。
每次获取下一条数据时,只需将队列顶端结果集的游标下移,并根据新游标重新进入优先级排序队列找到自己的位置即可。
分组归并的情况最为复杂,它分为流式分组归并和内存分组归并。 流式分组归并要求SQL的排序项与分组项的字段以及排序类型(ASC或DESC)必须保持一致,否则只能
通过内存归并才能保证其数据的正确性。
举例
假设根据科目分片,表结构中包含考生的姓名(为了简单起见,不考虑重名的情况)和分数。通过SQL获取每位考生的总分,可通过如下SQL:
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
在分组项与排序项完全一致的情况下,取得的数据是连续的,分组所需的数据全数存在于各个数据结果集的当前游标所指向的数据值,因此可以采用流式归并。
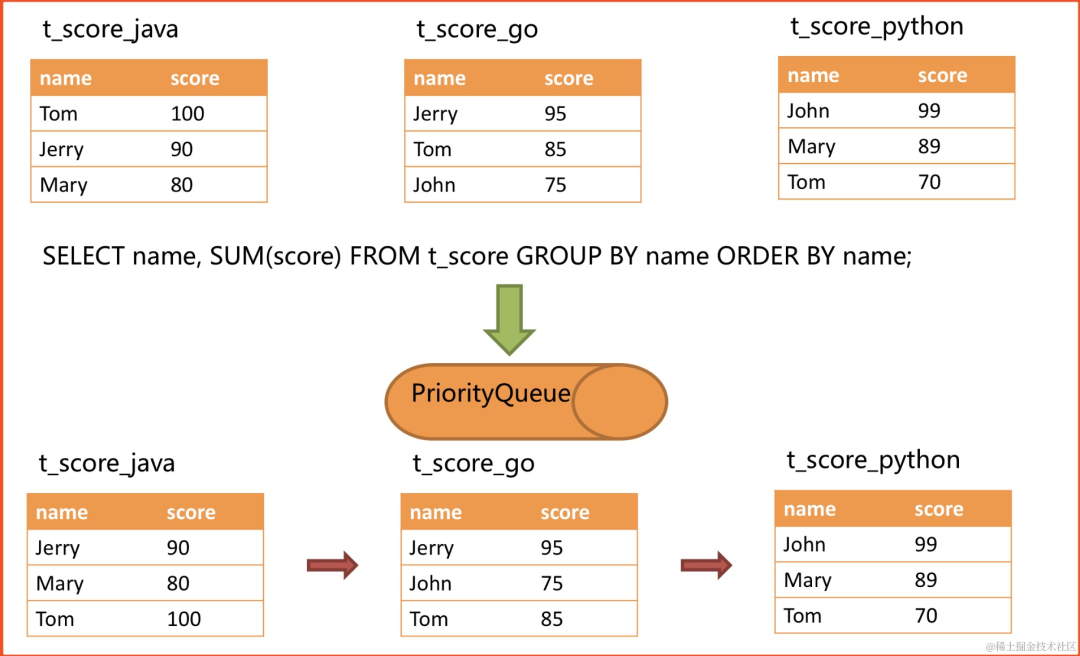 image.png
image.png进行归并时,逻辑与排序归并类似。 下图展现了进行next调用的时候,流式分组归并是如何进行的。
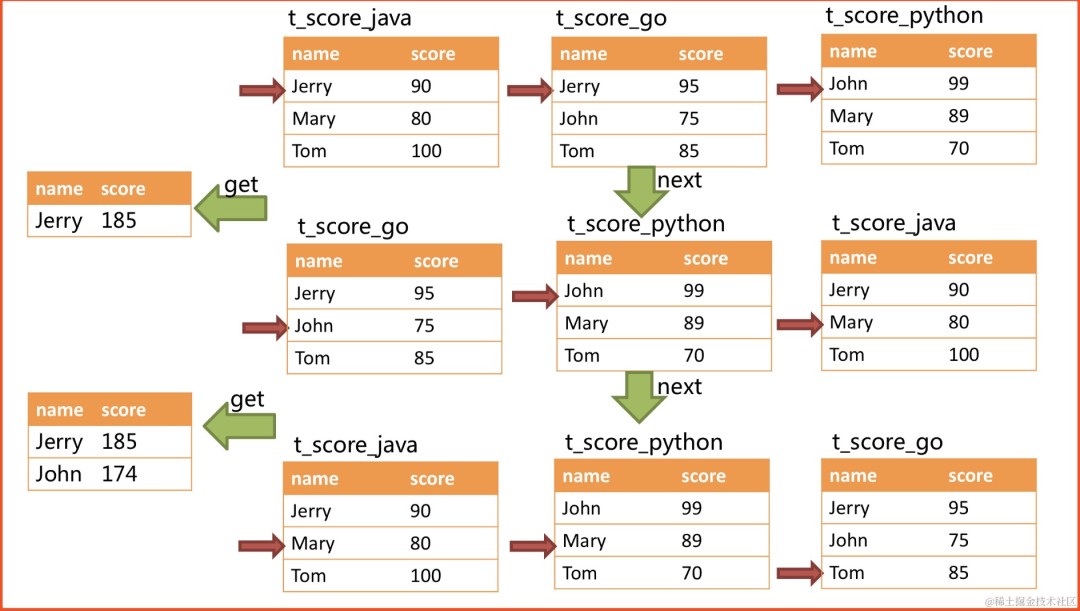 image.pngimage.png
image.pngimage.png无论是流式分组归并还是内存分组归并,对聚合函数的处理都是一致的。 除了分组的SQL之外,不进行分组的SQL也可以使用聚合函数。 因此,聚合归并是在之前介绍的归并类
的之上追加的归并能力,即装饰者模式。聚合函数可以归类为比较、累加和求平均值这3种类型。
比较类型的聚合函数是指MAX和MIN。它们需要对每一个同组的结果集数据进行比较,并且直接返回其最大或最小值即可。
累加类型的聚合函数是指SUM和COUNT。它们需要将每一个同组的结果集数据进行累加。
求平均值的聚合函数只有AVG。它必须通过SQL改写的SUM和COUNT进行计算
所有归并类型都可能进行分页。 分页也是追加在其他归并类型之上的装饰器,ShardingSphere通过装饰者模式来增加对数据结果集进行分页的能力。 分页归并负责
将无需获取的数据过滤掉。
ShardingSphere的分页功能比较容易让使用者误解,用户通常认为分页归并会占用大量内存。 在分布式的场景中,将LIMIT 10000000, 10改写为LIMIT 0, 10000010,
才能保证其数据的正确性。 用户非常容易产生ShardingSphere会将大量无意义的数据加载至内存中,造成内存溢出风险的错觉。 其实,通过流式归并的原理可知,会将
数据全部加载到内存中的只有内存分组归并这一种情况。 而通常来说,进行OLAP的分组SQL,不会产生大量的结果数据,它更多的用于大量的计算,以及少量结果产出的场景。
除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此ShardingSphere会通过结果集的next方法将无需取出的数据全部跳过,并不会将其存入内存。
但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到ShardingSphere的内存空间。 因此,采用LIMIT这种方式分页,并非最佳实践。 由于LIMIT并不能通过索引
查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
或通过记录上次查询结果的最后一条记录的ID进行下一页的查询,例如:
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
数据分片
- 分库 & 分表
- 读写分离
- 分片策略定制化
- 无中心化分布式主键
分布式事务
- 标准化事务接口
- XA强一致事务
- 柔性事务
数据库治理
- 配置动态化
- 编排 & 治理
- 数据脱敏
- 可视化链路追踪
- 弹性伸缩(规划中)
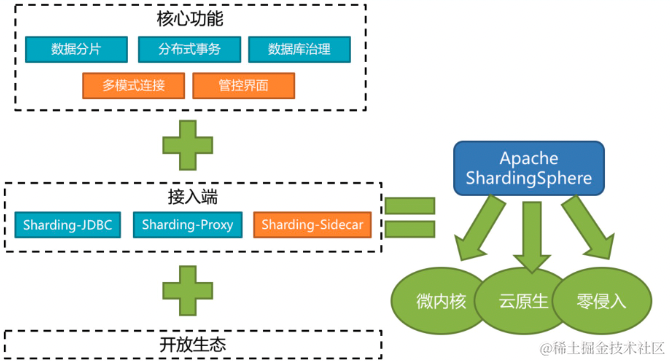 image.png
image.pngShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar这3款相互独立的产品组成。
他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
当一张表的数据达到几千万时,查询一次所花的时间会变长。业界公认MySQL单表容量在 1千万 以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
垂直切分又可以分为: 垂直分库和垂直分表。
数据切分可以分为:垂直切分和水平切分。
概念 就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按业务分类进行独立划分。与"微服务治理"的做法相似
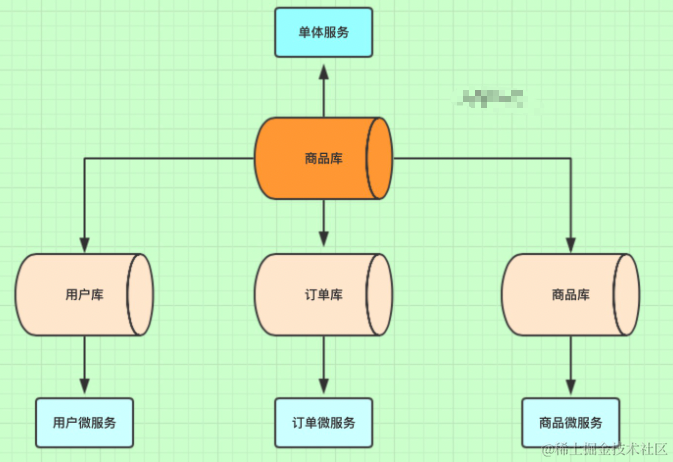 image.png
image.png一开始我们是单体服务,所以只有一个数据库,所有的表都在这个库里。
后来因为业务需求,单体服务变成微服务治理。所以将之前的一个商品库,拆分成多个数据库。每个微服务对应一个数据库。
垂直分表把一个表的多个字段分别拆成多个表,一般按字段的冷热拆分,热字段一个表,冷字段一个表。从而提升了数据库性能。
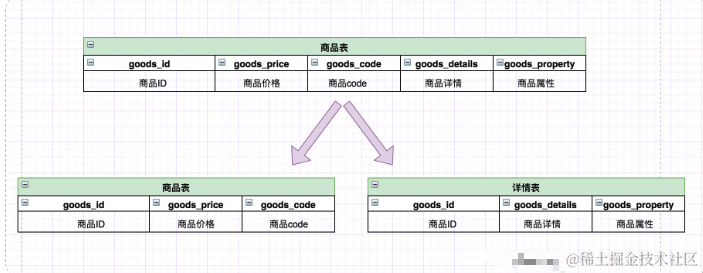 image.png
image.png一开始商品表中包含商品的所有字段,但是我们发现:
1.商品详情和商品属性字段较长。2.商品列表的时候我们是不需要显示商品详情和商品属性信息,只有在点进商品的时候才会展示商品详情信息。
所以可以考虑把商品详情和商品属性单独切分一张表,提高查询效率。
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
- 分库后无法Join,只能通过接口聚合方式解决,提升了开发的复杂度
- 分库后分布式事务处理复杂
- 依然存在单表数据量过大的问题(需要水平切分)
当一个应用难以再细粒度的垂直切分或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
水平切分也可以分为:水平分库和水平分表。
商品库分成3个库,但是随着业务的增加一个订单库也出现QPS过高,数据库响应速度来不及,一般mysql单机也就1000左右的QPS,如果超过1000就要考虑分库。
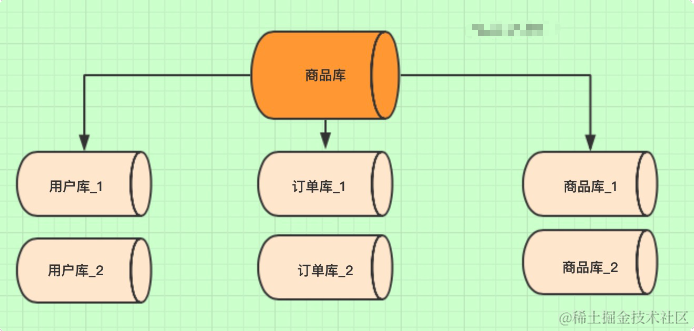 image.png
image.png一般我们一张表的数据不要超过1千万,如果表数据超过1千万,并且还在不断增加数据,那就可以考虑分表。
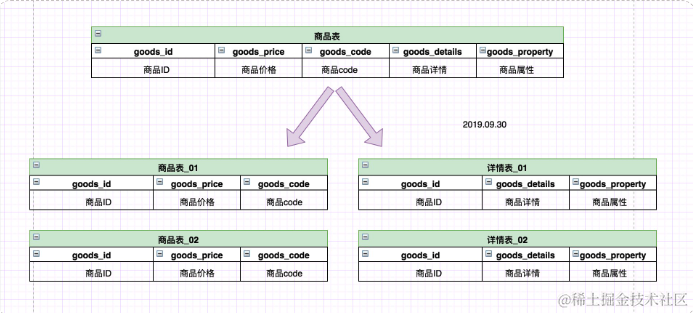 image.png
image.png- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
- 跨分片的事务一致性难以保证
- 跨库的Join关联查询性能较差
- 数据多次扩展难度和维护量极大
将一张表水平切分成多张表,这就涉及到数据分片的规则,比较常见的有:Hash取模分表、数值Range分表、一致性Hash算法分表。
一般采用Hash取模的切分方式,例如:假设按goods_id分4张表。(goods_id%4 取整确定表)
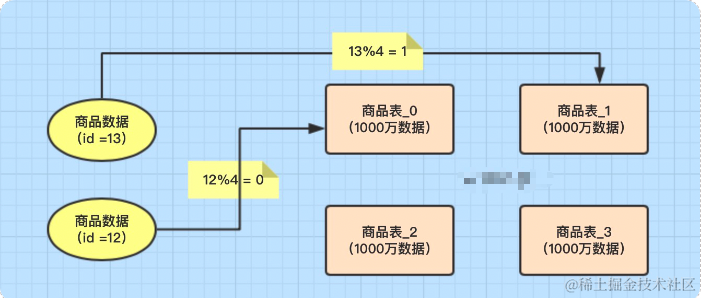 image.png
image.png- 数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈。
- 后期分片集群扩容时,需要迁移旧的数据很难。
- 容易面临跨分片查询的复杂问题。比如上例中,如果频繁用到的查询条件中不带goods_id时,将会导致无法定位数据库,从而需要同时向4个库发起查询, 再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
按照时间区间或ID区间来切分。例如:将goods_id为11000的记录分到第一个表,10012000的分到第二个表,以此类推。
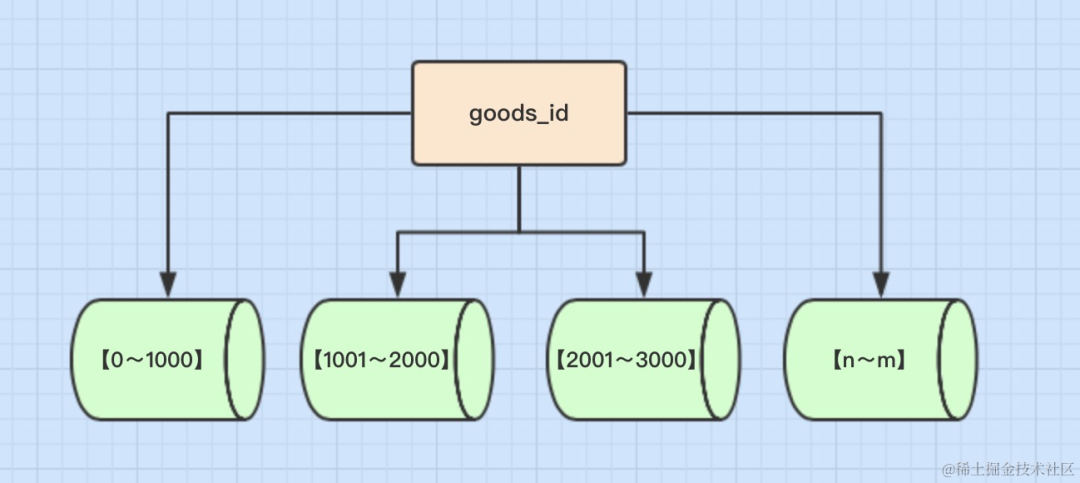 image.png
image.png- 单表大小可控 - 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移
- 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
- 热点数据成为性能瓶颈。 例如按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
一致性Hash算法能很好的解决因为Hash取模而产生的分片集群扩容时,需要迁移旧的数据的难题。
任何事情都有两面性,分库分表也不例外,如果采用分库分表,会引入新的的问题
用分布式事务中间件解决,具体是通过最终一致性还是强一致性分布式事务,看业务需求
切分之前,我们可以通过Join来完成。而切分之后,数据可能分布在不同的节点上,此时Join带来的问题就比较麻烦了,考虑到性能,尽量避免使用Join查询。
全局表,也可看做是 "数据字典表",就是系统中所有模块都可能依赖的一些表,为了避免跨库Join查询,可以将 这类表在每个数据库中都保存一份。这些数据通常
很少会进行修改,所以也不担心一致性的问题。
利用空间换时间,为了性能而避免join查询。例:订单表保存userId时候,也将userName冗余保存一份,这样查询订单详情时就不需要再去查询"买家user表"了。
在系统层面,分两次查询。第一次查询的结果集中找出关联数据id,然后根据id发起第二次请求得到关联数据。最后将获得到的数据进行字段拼装。
跨节点多库进行查询时,会出现Limit分页、Order by排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;
当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。
如果都用主键自增肯定不合理,如果用UUID那么无法做到根据主键排序,所以我们可以考虑通过雪花ID来作为数据库的主键,
采用双写的方式,修改代码,所有涉及到分库分表的表的增、删、改的代码,都要对新库进行增删改。同时,再有一个数据抽取服务,不断地从老库抽数据,往新库写,
边写边按时间比较数据是不是最新的。
每个微服务使用单独的一个数据库
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview